RBm,erci,emp.nts
Tout d'abord, nous
remercions
Dieu
de
nous
avoir permis de terminer
ce
modeste
travail.
Nous tenons d
remercier
exceptionnellement notre encadrant
Dr.
Boukraa
Doulkifli pour
sesprdcieux
conseils
qu'il
nous
aprodigudes, ainsi
quepour
son
soutien,
sesorientations, sq
disponibilitd
et
sa
comprdhension tout au long
de
ce
travail.
Nos
remerciements
vont
dgalement
aux
membres
du
contribution
scientifique
lors
de
l'dvaluation
de ce
travail.
Nous
remercions dgalement
tous
les
enseignants
de
ddpartement
jury,
pour
leur
informatique,
enparticulier
notre chef ddpartement et chef
de
spdciolitd.
Tous
lesparents,
membres
defamilles,
connaissances et amies
qui
nous
ont
6td
d'un
soutien
moral
tout au long
de notre
formation
sont
dgalement vivement
remercids.
A
toute
personne
qui,
deprds
ou de
loin, a
contribud
d
la
rdalisation
de
ce
travail.
O6{icace
A
gtfos
cftnrs
I
atre,ttts,
Qu.e
nut
trefficace
ne
puisse exloriwter
ce
que
nous
feurs
devorts,
_pour
feur
7ientteiffartce,
feur affection
et feur
soutieyr,
en tdmoignage
tre
nos
yrofonds
e?nours
et
nos
grartfes
recovwlaissances
<<Qu.e
Dieu
yo.tLs
garde
et
vous
yrotd.ge
>>.A
t{os
cfu*res
sewrs
et
nns
frdres,
A
fous
nos amis,
?sur
feur entauragem.ent et feur
ssuti.en
moraf
furant
f efaSoratinn
{e
ce
grojet
{e
fin
f
etu{es.
O€it'
ad
cJ-n LL*lt -rJS-+.i-i.-blr
drur+lr crLus* iJ^.,Ej rJio _.rljlr grr.-,
d,JlJr
,jis"rJ
d*,lr
haLir*t
:llr:J-S
ill'^'iL
"i{jl
,,+iJ4itil
crUl.lll,j,L
ll"r
,1L:.i-:,
.a.i.:ll
ol-rlull grJisol+rd
.!*b;r;c
Usl;$l cs_r\ d,l-ri. J,"+ Neo4j
Ujl
drNoSeL ciUlll i.rLI
,4^i.:ll
cru!5rll crLrs.,i-i.:ll
oul;;ll
tr:Ieo
,NoSeL
oNoe4j
.
i..t':i
ojlgL.lslf
R6sum6
Le travail prdsentd dans ce mdmoire a pour objectif de permettre aux analystes et d6cideurs de
concevoir
des
cubesde
donn6es massives(Big
Data).
Le
travail est
centr6 autour
de
la moddlisationd'un
entrep6t de donndes pour des donn6es massives, nous appliquonsnotre
travail
aux donndes 6ducatives de
l'Inde
en exploitant une technologie deBig
Data : la base de donn6esNoSQL Noe4j. Nous
montrons
la
faisabilit6
de
notre proposition
d
travers une
applicationd6di6e.
Mots-cl6s
! Noe4j, NoSQL, entrepdt de donn6es massives, cube de donn6es massives.Abstract
This work
aims atallowing
analysts and decision makersto
designBig
data cubes. The coreof
ourwork
is the modelingactivity of
a data warehousefor
massive dat4 we apply our work to the educational data of Indiaby
using a mainBig
data technology: Noe4jNoSeL
database. We show thefeasibility
of our proposal through a dedicated software.Table
dernatiires
Table
dernatiires
6.1.
Historique...
...t5
6.2.D€frrxtion...
... 156.3. Diffbrents types de base de donn6es
NoSeL
...t6
6.3.1. Bases de donndes Orientdes Cl6 /Valeur
... 166.3.2. Bases de donndes Orient6es
Document
... 166.3.3. Bases de donndes Orientdes
Colonne
...176.3.4. Base de donndes Orientdes
Graphe...
...lg
6.4. Avantages duNoSQL...
...t9
6.5.
Quelquestravaux sur
le
croisement entreles
entrepdtsde
donndeset les
Systdmes NoSQL orient6sgraphes...
...207.
Conclusion...
... 21Chapitre 2
: Pr6sentation del'6tude
de casl.Introduction
...
...232. Pr6sentation de
systime
d'enseignementsup6rieur
indien
...232.1. Enseignement
sup6rieur...
...232.2.Type
d'institutions...
...243. Les donn6es 6ducatives de I'enseignement
sup6rieur
indien...
...2s 3.1. Description desdonndes
...253.2. Mod6lisation logique (relationnelle) des donn6es
6ducatives
....26
4. Exemples de besoins
dtana1yse...
....2g 5.Opportunitd
de larepr6sentation
des donn6es 6ducativespar un
graphe
....32
Table
detnatiires
Chapitre3:Conceptionetentreposagedecubededonn6esmassives
?5 1.
Introduction
...2. Les bases de donn6es orient6es
graphe
"""
35 3.Mod6lisation
des donn6es 6ducatives orienteesgraphes
""""""'
364.
Mod6tisation
dusch6ma
""""""
365.
Mod6lisation
des donn6espar
un
graphe
""""""""""
44 6.Conception
de cubesOLAP
sur
des donn6es orient6esgraphes
"""""""""'
47 6.1. Moddle de cube de donn6es massives orient€graphes
"""""""
47 6.2. processus de conceptiond'un
cube de donndes massives orientdes graphes""""""""
496.2.t.Choix
du nmudfait
"""""
"""""""
496.2.2.Obtention et choix des dimensions
""""'
""""'
506.2.3.Ajout
d'extension
""""'
516.2.4 .Ghndration des donn6es du
cube
<t
6.3. Exemple de conception de cubes de donndes massives orient6es graphe""""""""""'
53
7.
Conclusion
...'.
""'
54Chapitre
4 :Mise
en (Puvre dela
conception et entreposage de cubes de donn6es massives ... 56 1.Introduction
... 2.Environnement
de stockage"""""""'
""""'
562.|.Lesystdmedegestiondedonndesorient6grapheNeo4j.''...56
2.2.
Carastlristiques deNeo4j
""
56 2.3. Installation deneo4j
"""""'
57 2.4. Lancement deneo4j
""""""'
57 2.5. Pr6sentation du langageCypher
""""""
58Table
dernatiires
2.6. Crflation de la base de
donndes
... 592.6.1. Cr6ation de
sch6ma
... 592.6.2. Crdation du graphe des donn6es
...
... 593.
Environnement
ded6veloppement
...653.l.IDENetBeans
....653.2. Relation entre NetBeans et
Noe4j
... 654.
dpplication
de conception de cubes orient6sgraphes
...655.
Conclusion
...
....70
conclusion
G6n6rale
...71Bibliographie
...
....72
Liste
de
figures
Figure
1.1 : Architecture g6n6rale d'un entrepOt de donn6es...
... 6
Figure
1.2:
Caractdristiques des entrepdts dedonn6es...
...6Figure
1.3 : Architecture fonctionnelle d'un entrep6t dedonndes
...7
Figure
1.5Figure
1.6Illustration
d'une Base de donndes orientde cl6/valeur
...l6
Illustration
d'une base de donn6es orientdedocument
... T7f
igure
1.7 :Illustration
d'une Base de donndes orientdecolonne
... 1g
Figure
1.8 :Illustration
d'une Base de donndes orient6egraphe
... 19
X'igure 1.9 : Reprdsentation logique orientde
graphe
...20Figure
2.1:
Sch6ma relationnel de donndesdducatives.
...27
Figure
2.2:
partie de Schdma relationnel de donndesdducatives.
...2gFigure
2.3 : R6partition des universitds rdpondantes selon la sp6cialisation ... ...29Figure
2.4: Rlpartition
du personnel non enseignant selon resniveaux
... 30
Figure
2.5 : Rdpartition 6quilibrde entre les sexes du personnel non enseignant ...31
Figure
2.6 :Dishibution
des cat6gories sociales du personnel nonenseignant
...31
Figure 2'7 :
Nombre de femmespour
100 hommes parmile
personnel non enseignant dans diversescat6gories.
...32
Figure
3.1:
Sch6ma de graphe de l'6tude decas
...37Figure
3.2 : partie de Schdma de graphe de l,6tude decas
...37
Figure
3.3:
exempled'un fichier
csv...
....47
Figure
3.4:
Sch6ma de cubeclassique
... 4gListe
defigures
ettableaux
Figure
3.6Figure
3.7Figure
3.8Figure
3.9Figure
3.10Figure
3.11Figure
3.L2Figure
3.13Figure
3.14Figure
3.15Figure
3.16Figure
3.17Exemple de cube de donn6es orientd
graphe...
...49Choix de nmud
fait...
... 50Obtention des
dimensions
...
... 50Choix des dimensions
pr6f6r6es...
... 51Ajout
d'extension
...5l
Elagage de niveaux dedimensions...
....52
Schdma de
cube
...52Gdndration des donn6es de
cube
... 53Exemple de choix de
fait
... 53Obtention des dimensions assocides au
fait
choisi
... 53Exemple d'ajout
d'extension
...54Exemple de choix des dimensions
pr6ferdes...
...54Lancement de
Neo4j
... 57Interface de
Neo4j
... 58Ecran d'accueil de
l'application...
...66Visualisation de schdma de
donndes
...67Choix de
naud
fait
...
...67Obtention des dimensions
...
... 68Extension de cube
existant
... 68G6n6ration des donn6es de
cube
... 69Choix de nom du
cube
...69:
Confirmationd'enresistrement...
... 69: Liste des cubes
enresistr6s
..-...70F'igure 4.1
Figure
4.2Figure
4.3Figure
4.4Figure
4.5Figure
4.6Figure
4.7Figure
4.8Figure
4.9Figure
4.10Figure
4.11Liste
de{igures
ettableaux
Liste
de
tableaux
Tableau
1.1Tableau
1.2Tableau
1.3 Tableau 2.1Tableau
2.2Tableau
2.3Tableau
3.1Tableau
3.2Tableau
3.3Tableau
3.4Caract6ristiques des
Big
data
... 13Outils
utilis6s
dans lesBig
data
... 13Difftrence
entre data lakeset
entrepdts dedonn6es
.... 15R6ponse des universit6s en
2016-2017
...28Nombre d'universitds selon la gamme de
colldges
...29Nombre de colldges par
district
... 30Explication des 6l6ments utilisd dans I'orient6
graphe
... 36Description des
nauds
deschdma
...41Description des relations de
sch6ma...
...44Statistiques des donn6es dducatives
...
...46Introduction
G6n6raleIntroduction
G6n6rale
En quelques ann6es,le volume des donndes brassdes par les entreprises a consid6rablement augment{. Venant de sources diverses (transactions, comportements, r6seaux sociaux, 96o
localisation...), elles sont souvent structur6es autour
d'un
seul point d'entrde, et susceptibles de croitre trds rapidement. Autant de caracteristiques qui les rendent trdsdifficiles
d mettre en 6chelle et de les traiter avec des outils classiques de gestion de donn6es. Par ailleurs, l'analyse de grands volumes de donn6es, ce qu'on appelle le Big Data, d6fie 6galement les moteurs de bases de donn6es traditionnels. C'est pour rdpondrei
ces diffdrentes probl6matiques que sont ndes les bases de donn6es NoSQL (NotOnly
SQL),Sont regroupdes dans la catdgorie NoSQL, de nornbreuses bases qui ont 6t6 spdcialisdes d des cas d'usage trds spdcifiques, que les bases relationnelles ne peuvent pas (ou elles peuvent
difficilement)
traiter[1].
On ddnombre quatre type de bases de donn6esNoSQL
: c16-valeur, orientde colonnes, orientdes graphes et documents.Dans ce m6moire, nous allons nous focaliser sur un de ces quatre types de bases
NoSQL'
d savoir les bases de donndes orient6es graphe. Ces demidres se basent sur la th6orie des graphes, une th6orie bien qu'ancienne, est utilisde dans un grand nombre de disciplines. En effet ces bases de donn6es ont pourobjectifde
stocker les donndes en se basant sur la th6orie des graphes en s'appuyant sur les notions de nceuds qui ont chacun leur propre structure, sur les relations entre les nceuds, et leurs propri6t6s'Les sources de donnde pouvant Otre reprdsent6es par des graphes couvrent diff6rents domaines tels que les rdseaux sociaux,
etc.
Ces donn6es peuvent 6tre la source alimentant des structures analytiques comme des cubes OLAP pour une meilleure prise de d6cision.Cependant, les outils actuels d'analyse en ligne traitent bien les donn6es structur6es mais les donn6es orient{es graphes restent d6pourvues
d'outils
d6di6es ou adapt6es pour I'analyse enligne.
Notre travail poursuit
l'objectif
de contribuer d la proposition de solutions pour I'analyse enligne
(OLAP)
de donn6es orientdes graphes. Pour ce faire, le travail consiste d'abord dconcevoir et impldmenter une base de donn6es d6cisionnelle orient6e graphe puis d permettre aux utilisateurs (analystes, ddcideurs, etc.) de concevoir des cubes d la demande' colnme
Introduction
G6n6raleo
Dans un premier temps,il
s'agit de permettre aux analystes de concevoir des groupes de nmuds reprdsentant des entitds de la rdalitd etd'6tablir
les relations entre ces entit6s. La base de donn6es ainsi cr66e est d6cisionnelle dans le sens qu'elle permet aux utilisateurs d'extraire des structures d'analyse par le biais d'opdrations de sdlection de sous-graphes selon les besoins d'analyse ad hoc. Comme domaine d'application, nous nous intdressons au domaine 6ducatif.Dans ce contexte, et pour le besoin d'appliquer notre travail d des donn6es volumineuses, nous appliquons notre travail aux donn6es dducatives de
l'Inde,
mises sur Internet d la disponibilit6de la communautd de la recherche et autres.
o
Dans un deuxidme temps, nous proposons un processus de conception de cubesOLAp
basds sur des donndes orient6es graphes, support6 par une application informatique. Le processus permet de sdlectionner un neud-type pourjouer
le r61e de fer,itd
analyser, puis de ddduire,filtrer
et d6velopper les dimensions d'analyse li6es au fait. Une fois le cubeOLAp
basd sur les donndes graphe est congu,il
s'agit de le g6n6rer d partir des donn6es de base et de le charger dans une base de donn6es pourqu'il
puisse 6tre exploitd par des outils d6cisionnels. Nous avons organisd notre travail en quatre parties. La premidre partie consiste d pr6senter le concept de I'entrepdt de donndes, celui duBig
Data et des Data Lakes ainsi que des bases de donn6es NoSQL. La deuxidme partie consiste d introduire le domaine d'application qui est sur des donn6es de 1'6ducation indiennes, la structure de donn6es par des graphes et les possibilit6sd'analyser ces donndes selon le besoin. La hoisidme partie prdsente le moddle logique de
I'entrepdt de donn6es massives appliqu6 d notre domaine, le processus de conception des cubes de donndes massives et le m6canisme de leur stockage. La quatridme partie est d6di6e d la
pr6sentation des d6tails d'impldmentation de notre
fravail,la
construction d'entrep$t des donn6es massives, la conception et le stockage des cubes.Chapitre
I
:
Etat
de
I'art
1.
Introduction...
... 42.
Entrepdt
dedonn6es...
...52.1.Dffrnrtion...
... 52.2. Caractdristiques des entrep6ts de donn6es
...
... 62.3.
Arclntecture fonctionnelled'un
ED...
...73. Cube de
donn6es...
... g 3.1.D6finition...
... g 3.2. ConceptOLAP
...93.3. Opdrations
OLAP
...1l
4.Big
data...
...124.1. Qu'est-ce que le
Big
data?...
... 124.2. Caruct6risation des
Big
data...
... 124.3. Les Outils utilisds dans les sc6narios de
Big
Data...
... 134.4.Tenatns d'applications du
Big
data....
... 135. Data
lakes
... 145.1.
D6finition...
... 145.2. Les limites des Data
Lakes
... 145.3. Data lakes vs Enhepdts de
donndes
... 156. Bases de donndes
NoSQL..
... 156.1.
Historique...
... 156.2.Defnition...
... 156.3. Diffdrents types de base de donn6es
NoSQL
... 166.3.1. Bases de donndes Orientdes Cld
/
Valeur
... 166.3.2. Bases de donndes Orientdes
Document
... 166.3.3. Bases de donndes Orient6es
Colonne
...176.3.4. Base de donn6es Orientdes
Graphe...
... 1g 6.4. Avantages duNoSQL...
...,... 196.5.
Quelquestravaux sur
le
croisement entreles
entrep6tsde
donndeset les
Systdmes NoSQL orient6sgraphes...
...20 7.Conclusion...
...2l
Etat
del'art
l.
Introduction
Les systdmes d'aide d la ddcision occupent une place pr6ponddrante au sein des entreprises et des grandes organisations, pour permethe des analyses dddi6es d la prise de ddcision. Dominde par les outils du march6,
I'informatique
d6cisionnelle est un domaine investi par le monde de la recherche au travers des concepts d'entrep6t de donndes.L'Entrepdt
de donn6es (ou data warehouse) d6signe une base de donn6e qui fait plusieurs actions commela
collection, l'ordonnancement,la
journalisationet
le stockage desinformations provenant de base de donndes op6rationnelles et
fournir
ainsi un soclei
l'aide
d la d6cision en entreprise [2].Aujourd'hui,
il
y a de plus en plus de donndes et informations d traiter. L'entreprise produitses propres donn6s, et acquiert aussi des donndes
dpartir
des 6changes avec ses clients, ses fournisseurs, ses partenaires, ses actionnaires et en reproduit sans cesse de nouvelles. Cependant aufil
du temps, bon nombres de grandes entreprises se sont retrouvdes avec des volumes de donndes ing6rables. Face d ce probldme, la question concemant la gestion de ces volumes est : comment les exploiter et les analyser, pour mieux piloterl'activitd
de son entreprise ?Lorsque le traitement et
l'utilisation
des donn6es ddpassent les capacitds des technologies courantes en raison de leur volume, v61ocit6,vai6t6,valeur
et vdracit6, un ensemble de rdponses logicielles et matdrielles 6tiquet6es <Big
Data > a vu rejour.
Le
Big
Data est une nouvelle g6ndration de technologies et d'architectures congues pourextraire de la valeur, de fagon rentable, d partir
d'un
volume considdrable de donn6es trds varides en permettant leur capture et leur exploration d grande vitesse [3].Dans ce chapitre nous allons prdsenter le concept d'entrep6t de donn6es, celui du Big Data principalement de la technologie
NoSQL,
ainsi que quelques travaux de recherche quiprdsentent le croisement entre les entrepdts de donndes et le
Big
Data.Chanitre
L :Etat
del'art
2.
Entrep6t
de donndes
2.1.
D6finition
Un entrep6t de donn6es
(ED)
est une base de donn6es regroupant des parties ou des ensembles des donn6es fonctionnelles des entreprises.Il
entre dans le cadre de I'informatiqueddcisionnelle ; son but est de fournir un ensemble de donn6es servant de rdfdrence unique,
utilis6e pour la prise de ddcisions dans I'entreprise par le biais de statistiques et de rapports r6alis6s via des outils de reporting. D'un point de l.ue technique,
il
sert surtoutd'd,llester'les
bases de donn6es opdrationnelles des requ6tes pouvant nuire d leurs performances [2].
D'un point de vue architectural,
il
existe deux manidres d'appr6hender un entrepdt de donndes :.
L'architecture de haut en bas : selonBill
Inmon, I'entrepdt de donn6es est une base de donndes au niveau ddtail, consistant en un r6f6rentiel global et centralisd de I'entreprise. En cela,il
se distingue du Datamart, qui regroupe, agrdge et cible fonctionnellement les donn6es..
L'architecture de bas en haut : selon RalphKimball,
I'entrep6t de donn6es est constitu6 peu d peu par les Datamarts de I'entreprise, regroupant ainsi diffdrents niveaux d'agrdgation etd'historisation de donn6es au sein d'une mOme base.
La ddfrnition la plus commun6ment admise est un mdlange de ces deux points de vue. Le
terme Data warehouse englobe le contenant et le contenu :
il
ddsigne d'une part la base ddtaill6equi est la source de donndes d I'origine des Datamarts, et d'autre part l'ensemble constitud par cette base d6taill6e et ses Datamarts. De la mOme manidre, les mdthodes de conception
actuelles prennent en compte ces deux approches,
privil6giant
certains aspects selon les risques et les opportunitds inhdrents d chaque entreprise [2].Chapitre
1 :Etat
de Inart Zone de Zone de pr€paralnni*"'
-'
* **- 'I li
.l iI
t
r*rr*rm*'
I
i
Henoyaoet i
lsunaamir*ml'ti
:tii
i Sources ds donndesi
I I Zone de sloct4e flelg'ldq! n A R G E M E N Ti*'g
I Requ€tesr*g
Rapub , Vnuahsaton ROahilnrp'
'S
i*B
Figure 1.1 : Architecture g6n6rale d'un entep6t de donndes [4]
2.2. Caract6ristiques
des
entrepdts
de donn6es
L'entrepdt de donn6es est une collection de donn6e pour le support d'un processus d'aide d la d6cision.
Il
offre des donn6es int6gr6es, consolid6es et histori6espolr
faire des analyses.Un
entrepdt de donndes possdde les caractdristiques suivantes
[5],
illustrdes parlafigrxe
1.2-->
€
Historfu6eFigure 1.2 z Cnacteristiques des entrepdts de donndes
o Orientation
sujet
Les donndes s'organisant par sujets ou thdmes. Une telle organisation permet de rassembler toutes les donndes pertinentes
i
un sujet et n6cessaires aux besoins d'analyse se trouvant rdpanduesi
travers les structures fonctionnelles d'une entreprise.o
Intdgration
Le r6sultat de
l'int6gration
de donn6es en provenance de multiples sourcesd6finit
lesdonndes de I'entrepot, ainsi toutes les donn6es ndcessaires pour r6aliser rrxe analyse particulidre
se trouvent dans 1'entrep6t.
L'intdgration
est le r6sultat d'un processus qui peut devenir trdscomplexe du d I'h6tdrog6n6it6 des sources' o
Historisation
L'activit6
d,une entreprise pendant une l0ngue p6riode peut 6fie repr6sent6e par les donn6esd,un entrepot,
d'ot il
est important de g6rer les differentes valeurs qu'une information peut prendre aufil
du temps. cette caract6ristique donne la possibilit6 de suivre une donn6e dans le temps pour analyser ses variations'o
Non
volatilitd
Les donndes charg6es dans 1'entrep6t ne peuvent pas 6tre modifi6es sauf dans certains cas de rafraichissement. Elles sont utilis6es en interrogation.
2.3.
Architecture
fonctionnelle dtun ED
un
entrep6t de donn6es se base sur la collection de 1'ensembled'information utile
auxd.cideurs d partir des sources de donn6es (bases de donn6es(BD) op6rationnelle, bases de
donn.es externes,...) et centralisation de
I'information
d6cisionnelle, garantie def
intdgrationdes donn6es extraites et de leur p6rennit6 dans le temps
[6]'
L'architecture fonctionnelle d',un entrepdt de donndes comporte trois niveaux i11ustr6s dans
lafigure
1.3 : Nlveau exDloitationE
Pr€sentationt-l
It---_-Jl Client decisionnel Exploration Naveau fusion ion, liltrageDonn€es extemes BD l6galaires Donnees operationnelles
Etat
deI'art
Niveau
extraction
Ce niveau traite I'extraction de donndes des
BD
op6rationnelles et del'extdrieur
:r'
Approche < push > : d6tection instantan6e des mises djour
sur lesBD
opdrationnellespour
l'intdgration
dansl'ED.
/
Approche <pull
> : d6tection pdriodique des mises djour
sur lesBD
pourl'int6gration
dans
I'ED.
Niveau fusion
'/
L'krteglation,
le chargement et le stockage des donn6es dans laBD
entrep6t organis6e par sujets ou par thdmes.,/
Rafraichissement aufir
et d mesure des mises d iour.Niveau
exploitation
{
Les
tableaux de bords, visualisation par les graphes, et 6dition des rapports{
L'analyse etI'exploration
des donn6es entreposdes./
Requ6tes complexes pour I'analyse de tendance, I'extrapolation, la ddcouverte de connaissance, .. .3.
Cube
de donndes
3.1.
D6finition
Le cube de donndes
offre
une
abstractiontrds
prochede
la fagon dont l'analystevoit
et interroge les donndes.Il
organise les donndes en une ou plusieurs dimensions qui ddterminent une mesure d'intdrdt. Une dimension spdcifiela
manidre dont on regarde les donndes pour les analyser,alors
qu'une mesure est un objet d'analyse. Chaque dimension est forrn6e par unensemble d'atFibuts et chaque attribut peut prendre difErentes valeurs. Les dimensions
possddent
en
gdndral des hidrarchies associ6es qui organisent lesattributs
d diff6rents niveaux pour observer les donndes d differentes granularitds. Une dimension peut avoir plusieurs hi6rarchies assocides, chacune spdcifiantdiftrentes
relations d'ordre entre ses attributs [7].Exemple
: lafigure
1.4 ddcrit un cube de donn6es VENTES mod6lisant les ventesd'un
Chapitre
I
:Etat
deI'art
F3Produit
P? P1 C1 C2Client
c3
Figure 1.4 : Cube de donn6es [7]
Les dimensions sont client, produit, temps et la mesure est quantit6 avec les domaines :
dom(produit):{P1, P2,P3}, dom(client):
{Cl,
C2,C3},
dom(temps):
{1999,2000},
etdom(quantite)
c 5.
Le cube VENTES est d6fini par trois dimensions pour les membres (produit, client et temps), et une mesure (le n-uplet<quantite> et la fonction Fventes de domproduitx domclientx
domtemps vers dom(quantite) U
{0,1}).
Une cellule du cube VENTES est par exemple < P2,c2,2000>.
Plusieurs op6rations sont introduites pour
offrir
des possibilit6s d'animation dans larepr6sentation du cube d 1'6cran. Elles consistent d faire pivoter le cube, le couper en tranches,
interchanger ou combiner les coordonn6es eVou les contenus [7].
3.2.
Concept OLAP
OLAP
ou OnlineAnalytical
Processing est une technologie de traitement informatique .Ellepermet
i
unutilisatew
de consulter et d'extraire facilement les donndes pour les comparer de diffdrentes fagons. Les donndesOLAP
sont stock6es sur une base de donndesmultidimensionnelle, aussi appeldes Cubes OLAP,
pow faciliter
ce type d'analyses.Un
serveurOLAP
est ndcessaire [8].Le noyau
d'un
systdme OLAP est son serveur. Les serveursOLAP
sont class6s selon la politique rdgissant l'architecture du serveur.Ainsi,
ces architectures peuvent 0tre distingu6es comme suit:Chapitre
I
:Etat
deI'art
Les systdmes
MOLAP
<Multidimensional OnJine Analytical
Processing > sont congus exceptionnellement pour I' analyse multidimensionnelle.Kimball d6finit
ces systdmes comme 6tant un < Ensemble d'interfaces utilisateur,d'applications et de technologies de bases de donndes propridtaire dont l'aspect dimensionnel est prdpond6rant > [9].
Ainsi
donc, un systdmeMOLAP
adopte r6ellement la structure multidimensiorurelle, exploitant de cefait
ces capacitds au maximum. En effet, leMOLAP
offre des temps d'accds optimisds et cela en pr6d6finissant les opdrations de manipulation et de chemin d'accds prdd6finis.Une autre caract6ristique du
MOLAP
estqu'il
agrdge tout par d6faut, pdnalisant le systdme lorsque la quantitd de donn6es d traiter augmente. On parle g6ndralement de volume deI'ordre
du giga-octet pas plus.
F
Les systimesi
architecture
ROLAP
Ces systdmes sont d6crits cofirme 6tant un < Ensemble d'interfaces utilisateurs et
d'applications qui donnent une vision dimensionnelle d des bases de donn6es relationnelles >
tel.
Les systdmes
ROLAP
< Relational On-lineAnalytical
Processing > sont en mesure desimuler le comportement d'une SGBD multidimensionnel en exploitant un SGBD relationnel.
L'utilisateur
aurs ainsi I'impression d'interroger un cube multidimensionnel alors qu'en r6alit6il
nefait
qu'adresser des requ6tes sur une base de donn6es relationnelles.Ces systdmes peuvent stocker de grands volumes de donn6es, mais ils peuvent prdsenter un temps de rdponse dlev6. Les principaux avantages de ces systdmes sont :
(l)
unefacilitd
d'int6gration dans les SGBDs relationnels existants,(2) une bonne efficacitd pour stocker les donn6es multidimensionnelles [7].
F
Les systimesi
architecture
HOLAP
L'impldmentation
HOLAP
repr6sente une combinaison entref
impldmentationMOLAP
etROLAP. L'approche
HOLAP
permet d'entreposer les donn6es dont I'accds est le plus frdquent 10Etat
deI'art
par les utilisateurs dans une structure multidimensionnelle et le reste dans une structure
relationnelle. En combinant les structure
ROLAP
etMOLAP,
l',approcheHOLAP
donneaccds
aux donndes ddtaill6es ou agr6g6es selon le besoin d'analyse du d6cideur
[10]'
F
Les systimes drarchitecture
DOLAP
D-OLAP
<Desktoponline
Analytical
Processing> permet ir I'utilisateur d'enregistrer une partie de ra base de donn.esmulti
dimensionne*e en rocar.on
voit
trdsvite
1'utilit6 d'une tellesolution pour les commerciaux et les " nomades
"
de l'entreprise' Cela permettrait d un commercial, par exemple, de faire des analyses sur les ventes' conserver ses r6sultats'et
v6rifier
1'6volution de ses analyses, une fois revenu de son voyage d'affaire[11]'
3.3.
Op6rations
OLAP
)
Op6rations
li6esi
lastructure
Ces opdrations sont regroupdes sous le nom de restructuration' Tout cube obtenu paf une op6ration de restructuration
d'un
cubeinitial
contient tout cequ'il
faut pour r6g6n6rer le cubeinitial
par restructuration r6ciproque. Ces operations sont :pivot,
swich, split, nest, push' etpull
t7l.
{
Rotateou
Pivot
: effectuer d un cube une rotation autourd'un
de ses trois axespassant par le centre de 2 faces opposdes, de fagon d prdsenter un ensemble de faces
diff6rent.
r'
switch
: consiste dr interchanger la position des membres d'une dimension'{Sptit:Consisteirpr6senterchaquetrancheducubeetdepasserd'unepr6sentation
tridimensionnelle d,un cube d sa pr6sentation Sous la forme
d'un
ensemble de tables./
Nest:
oimbrication des membres d partir du cube'
oPermet de grouper sur une mome representation bi-dimensionnelle toutes les
informations (mesures et membres)
d'un
cube quelque soit le nombre de ses dimensions./
push
:
Consiste d combiner les membresd'une
dimension aux mesurss du cube' et donc de faire passer des mernbres conlme contenu de cellules':
Etat
deI'art
r'
Roil'up
: permet de monter dans les hi6rarchies des dimensions, et d'agr6ger les mesures.r'
Drill-Down
: est I'inverse duRoll-Up
et permet de descendre dans une hi6rarchie./
Slice : utilise un prddicatd6fini
sur les membres des dimensions pour couper une partie de I'hypercubelimitant
le champ d'analyse et permettant d I'utilisateur de seconcentrer sur des aspects particuliers du phdnomdne. En utilisant la terminologie de
l'algdbre relationnelle, I'op6ration de slice est 1'6quivalent de la sdlection.
r'
Dice : rdduit la dimensionnalitd de I'hypercube en dliminant une dimension. Cetteop6ration est 6quivalente d la projection de I'algdbre relationnelle [12].
4.
Big
data
4.1.
Qu'est-ce
que le
Big Data
?Plusieurs ddfinitions ont 6t6 donn6es au
Big
Data dont nous retiendrons la suivante :<
Il
s'agit de donndes de trds grandetaille
dont la manipulation et gestion pr6sentent des enjeux dupoint de vue logistiques. Englobe tout terme pour ddcrire toute collection de donndes tellement
volumineuse et complexe
qu'il
devientdifficile
de la traiter en utilisant des outils classiques de traitement d'applications. LeBig
Data concerne des collections de donn6es dont lataille
ddpasse lacapacite de capture, stockage, gestion et analyse des systdmes de gestion de bases de donndes classiques> [1 3].
+
Les facteurs cl6s pour la croissance duBig
Data sont:oAugmentation des capacit6s de stockage.
oAugmentation de la puissance de traitement.
.Disponibilit6
des donndes [14].4.2.
Ctract6risation
du
Big
Data
Selon Garhrer, ce concept regroupe une
famille d'outils
qui rdpondent d unetriple
probldmatique dite rdgle des 3V.
Il
s'agit notammentd'un
volume de donndes considdrable dtraiter, une grande varidtd d'informations, et un certain niveau de V6locit6 d atteindre.
tre
1 :Etat
deI'art
autrementdit
de fr6quence de cr6ation, collecte et partage de ces donn6es. Le tableau suivant prdsente quelques caractdristiques duBig
Data [13].Les
caractdristiques
Signification
Diflicult6s
Volum6trie
Grande quantit6 de donndes stockage, recherche, partage, analvse. visualisationV6locit6
Flux
continus de donn6es :capteurs, appareils mobiles, r6seaux sociaux
analyse et traitement des donn6es d la vol6e, sans les avoir en
intdgralitl
(one-pass processing)
Vari6t6
Diffdrents formats :s6quences, graphes,
D'intdgration
fi ointure, association) par le sens, l'6chelle, la qualitd, ...Tableau 1.1 : Caractdristiques du Big data
4.3.
Outils
utilis6s
dans les sc6narios
du
Big Data
De nombreuses technologies ont 6t6 ddvelopp6es pour analyser, gdrer, int6grer et exploiter
les donn6es massives, le tableau 1.2 prdsente les solutions les plus utilisds dans le
Big
data [13].lvlAP REDUCE Frincipe de programmation qui consiste
i
distribuer et paralleliser le traitement sur plusieurs nceudsFIADOOP HDFS {Hadoop
DistribLrted File Systenr) fondation Hadoop est une plate-forme informatique open-soltrce de laApache. capable de gerer/traiter des big data sur une architecture distribu€e. HDFS est le systeme de
gestion de flchier de base qui supporte Hadoop
NOSAL Technologie qui se diffErencie
i
la notian relationnelle des donn6es, adapt6ei
des donn€es peu structur6es (nombre dynamique de colonnes, document, graphes,..HBase, Cassandra. l'u'longoDB NE04J, Couche DB. Redis
SGBD qui supportent I'approche d'interrogation des donnees NOSQL
SAS. Talend. R. Python Outils et ou environemments de programmation et analyse adapt€s aux Big Data
Tableau 1.2 : Outils utilis6s dans les Big Data [13]
4.4.Terrains
d'applications
du
Big
data
Ch"ptt"-1tEt"td*
Le
marketing
: Collecter de nombreuses donndes sur le client, ses habitudes, sonprofil;
et croisement de ces donn6es avec d'autres sources de donn6es pour pr6dire son comportementfutur. On parle de vision d
360'
du client.L'industrie
: Collecter de nombreuses et diverses sources de donn6es lides aux processus defabrication de produits, d leurs usages, pour amdliorer ces demiers [15].
Transports
: I'analyse des donndes duBig
Data (donn6es provenant despass de transport en cofilmun, g6olocalisation des personnes et des voitures, etc.) permet de mod6liser les ddplacements des populations afin d'adapter les infrastructures et les services (horaires et frdquence des trains, par exemple)[5].
5.
Data
lakes
5.1.
D6finition
Un Data Lake est une m6thode de stockage des donn6es utilis6e par le
Big
Data. Le principe6tant d'avoir dans un lieu des donn6es de natures differentes: fichiers. blobs...
LaData
Lake est reconnu colnme une fagon de stocker de trds grands volumes de donndes,oi
les schdmas et les besoins d'analyses (oud'exploitation)
ne sont connus qu'au moment del'utilisation
des donndes [15].Exemple
: les logs de sites web, les tweets, les profiles sociaux, les commentaires de blogs, lesphotos...[5].
5.2.
Limites
des
Data
Lakes
Les limites des Data Lakes sont les suivent : [15]
)
N6cessite beaucoup de ressources:/
complexitd des algorithmes et prdparation des donn6es{
non adapt6 d des analyses r6pdtitivesoi
les donndes doivent 6tre recalcul6es d chaquenouvelle 6tude
)
Difficultds
de mise en place:{
llfautrepenser
le fonctionnement des systdmes de donn6es (quifait
quoi, comment...).F
S6curit6:
r'
probldmes li6si
I'accds aux donndes sensibles.Chapitre
I
:Etat
deI'art
5.3.
I)ata
lakes vs
Entrep6ts
de donn6es
Le tableau 1.3 prdsente la difference entre les entrep6ts de donn6es et les Data Lakes :
Tableau 1.3 : Difference entre data lakes et entrepdts de donndes [15]
6.
Bases
de donn6es
NoSQL
6.1.
Historique
Le monde entend le terme NoSQL
pour
la premidre fois au 1998,il
est invent6 et employd par CarloSnoznpour
qu'il
nomme son SGBD relationnel open source l6ger quin'utilisait
pas le langage SQL, sa trouvaille n'a rien dvoir
avec la mouvance NoSQL queI'on
connaitaujourd'hui,
vu
que son SGBD est de type relationnel. En effet, le terme NoSQL a 6t6 mis augott
dujour
en 2009, lors d'un rassemblement de la communautd des d6veloppeurs des SGBDnon-relationnels, pour englober tous les SGBD de type non-relationnel [16].
6.2.
D6frnition
NoSQL est une combinaison de deux mots :
No
et SQL qui pourrait 6tre mal interpr6t6e carI'on
pourrait penser que cela signifie lafin
du langage SQL et qu'on ne devrait donc plusI'utiliser.
Les moddles NoSQL sont de nouveaux moteurs de stockage qui emploient une architecture distribude capable de traiter de gros volume de donn6es. Ils prdsentent une nouvelle alternative
pour l' entreposage des donn6es multidimensionnelles.
Entrepdts
de donn6es Data lakesDonn6e Structur6e, traitee Structurde, semi-structur6e,
non structur6e,
originelle
Traitement
Sch6ma-On-Write Sch6ma-On-Readstockage Cofiteux pour les grands volumes de donn6es
Congus pour un stockage pas Cotrteux
Agilit6
Moins agile, structure fig6e Hautement aglle, configuration etreconfi guration d volont6
S6curit6 Mature En cours de maturation
Chapitre
1 :Etat
deI'art
En effet, NoSQL ne vient pas remplacer les bases de donndes relationnelles mais proposer une alternative ou compldter les fonctionnalitds des SGBDR pour donner des solutions plus intdressantes dans certains contextes. Le NoSQL regroupe de nombreuses bases de donn6es, r6centes pour la plupart, qui se differencient du moddle SQL par une logique de repr6sentation de donn6es non relationnelle [16].6.3.
Diff6rents
types de base de donn6es
NoSQL
Les bases de donn6es NoSQL ne sont plus fond6es sur l'architecture classique des bases relationnelles. Quatre grandes cat6gorises se distinguent parmi
celles-ci [16]
:6.3.1. Bases de donn6es orient6es Cl6 /
Valeur
Les bases de donn6es NoSQL de type cld / valeur s'articulent sur une architecture trds basique. Une valeur, un nombre ou du texte est stockd grdce d une c16, qui sera le seul moyen d'y acc6der. Leurs fonctionnalitds sont tout autant basiques, car elles ne contiennent que les commandes dl6mentaires du CRUD.
Les bases de type cl6/valeur les plus utilis6es sont Redis et Riak.
Figure 1.5 : Illushation d'une Base de donndes orientde cl6 /valeur [16]
6.3.2. Bases de donn6es orient6es
document
Ces bases de donndes sont une 6volution des bases de donndes de type c16-va1eur.
Ici
les c16sne sont plus assocides d des valeurs sous forme de bloc binaire mais d un document dont le format n'est pas impos6.
Il
peut 6tre de plusieurs types diffdrents comme par exemple du JSON ou duXI\[L,
pour autant que la base de donn6es soit en mesure de manipuler le format choisi afin de permethe des traitements sur les documents.Chapitre
L :Etat
deI'art
Les bases les plus connues se basant sur ce concept sont MongoDB et CouchBaseDocument 3 Champl Valeur Champ2 Valeur Champ3 Chamn4 Valeur Valeur
€hamp5 Chamol Valeur
Chamo2 valeur
Figure 1.6 : Illustration d'une base de donndes orientde document
[6]
6.3.3. Bases de donn6es orient6es colonneLes bases de donn6es orientdes colonne ont 6td congues par les gdants du Web afin de faire
face d la gestion
et
au traitement de gros volumes de donn6es.Le principe d'une base de donndes colonne consiste dans leur stockage par colorule
et
non par ligne(voir figure
1.7). Les basesde
donndes orientdes colonne quanti
elles vont stocker les donn6es de fagoni
ce que toutes les donn6es d'une mOmecolonne
soient stock6esensemble. Ces bases peuvent dvoluer avec le temps, que ce soit
en
nombre de lignes ou en nombre de colonnes.Autement
di!
et contafuement A une base de donndes relationnelle oriles colonnes sont statiques et pr6sentes
polr
chaque ligne, celles des bases de donndes orientdes colonne sont dites dynamiques et prdsentes donc uniquement en cas de n6cessit6.Chapitre
1 :Etat
deI'art
F'igure 1.7 : Illustration d'une Base de donndes orientde colonne [16]
6.3.4. Base de donn6es Orient6es graphe
Les bases de donn6es orient6es graphe permettent de rdsoudre des probldmes trds complexes
qu'une base de donn6es relationnelle serait incapable de faire. Les r6seaux sociaux (Facebook,
Twiffer,
etc.), ori desmillions
d'utilisateurs sont reli6s de diffdrentes manidres, constituent unbon exemple : amis, fans,
famille
etc. Le d6fiici
n'est pas le nombre d'616menti
gdrer, mais le nombre de relationsqu'il
peut y avoir enffe tous ces 616ments.Ces bases de donndes reposent sur la thdorie des graphes, avec
tois
6l6ments d retenir(voir
figure 1.8):
o
Un objet sera appeld unneud
(dans le contexte de Facebook nous allons dire que c'est un utilisateur).o
Deux objets peuvent6te
relids entre eux (comme une relationd'amiti6).
.
Chaque objet peut avoir un certain nombre d'attributs (statut social, pr6nom, nom, etc.).o
Laprincipale
solution est Neo4JChapitre
L :Etat
deI'art
connait
estFigure 1.8 : Illustration d'une Base de donndes orient6e graphe [16]
6.4.
Avantages du
NoSQL
Les bases de donn6es NoSQL par leur conception sont diffdrentes des bases relationnelles classiques. Elles rdpondent 6galement d d'autres probl6matiques et besoins.
Voici
quelques avantages [16].D
Plus6volutif
NoSQL est plus
6volutif.
C'est en effetl'6lasticit6
de ses bases de donndes NoSQL qui les rend si bien adaptdes au traitement de gros volumes de donndes.Au
contraire, les bases de donndes relationnelles ont souvent tendancei
utiliser
la scalabiltd verticale, quand celui-ci atteint ses limites.F
Plusflexible
N'6tant pas enfermde dans un seul et unique moddle de donn6es, une base de donn6es
NoSQL est beaucoup moins restreinte qu'une base SQL. Les applications NoSQL peuvent donc stocker des donn6es sous
n'importe
quel format ou structure, et changer de format enproduction. En
fin
de compte, cela 6quivaut d un gain de temps considdrable et d une meilleurefiabilitd.
Par contre une base de donn6es relationnelle doit Otre g6rde attentivement, car un changement, aussi mineur, peut entrainer un ralentissement ou un arrOt du service.F
Plus 6conomiqueLes serveurs destin6s aux bases de donndes
NoSQL
sont gdndralement bon march6 contrairement d ceux qui sont utilisds par les bases relationnelles. De plus, la trds grandeChapitre
1 :Etat
deI'art
majoritd des solutions NoSQL sont Open Source, ce qui refldte une 6conomie importante sur le
prix
des licences.F
Plus simpleLes bases de donndes NoSQL ne sont pas forc6ment moins complexes que les bases relationnelles, mais elles sont beaucoup plus simples d ddployer. La fagon dont elles ont dte congues permet une gestion beaucoup plus 16gdre.
6.5.
Quelques
travaux
sur
le
croisement
entre
les
Entrep6ts
de donn6es et
les
systimes
NoSQL
orient6s graphes
Dans cette section, nous prdsentons quelques travaux de recherche qui se sont int6ress6s au croisement entre les entrep6ts de donn6es et les systdmes NoSQL.
F
Travaux d'Arnaud
Castelltort
andAnne
Laurent. Q0l4)
<NoSQL Graph-based
OLAP
Analysis
>>Et20l4,
une premidre approche a 6t6 propos6e pour coupler le moddle orient6 graphe etI'OLAP
[17]. Dans cette approche les auteurs on proposd de structurer les donn6es dans lesystdme NoSQL orient6 graphes
Neo4J
et pr6sentent deux formalismes pour reprdsenter lefait
et les dimensions au niveau du moddle logique orientd graphes. Le formalisme assure deux types de relations, celles liant le
fait
aux dimensions, et celles reliant les attributs des dimensions entre eux; ces dernidres permettent de prdserver la relation hidrarchique(voir
Figure 1. 9).
I
c€tegorv II
ropm IF-r
lD4'l
---r=---['i*l
I r&sr II
rd-u
II
tmrion II rcdm
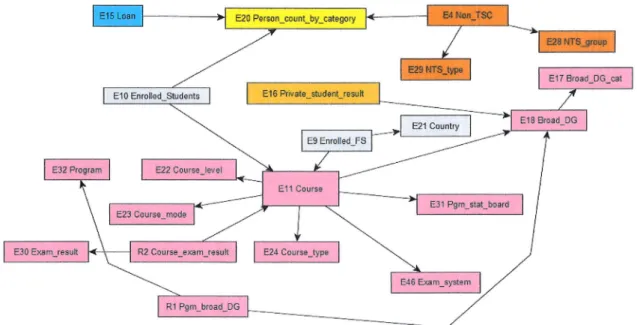
I !_-?J tr.atlon I uss 9rbject Trreet l*.b" | | t*Figure 1.9 : Reprdsentation logique orientde graphe selon [17]
Chapitre
1 :Etat
deI'art
}
Travaux
de C6cileFavre
et al,Q0l7)
<< Graphesenrichis
par
des Cubes(GreC)
>Dans le travaiL de
([18]),
Cdcile Favre et des co-auteurs ont propos6 une approche innovante appelde GreC (Graphes enrichis par des Cubes). Plutdt que de construire des cubes de graphes, leur proposition consiste d enrichir les graphes avec des cubes de donn6es qui viennent d6crire les neuds etlou les ardtes du r6seau selon les besoins. Cela permet des analyses int6ressantes pourI'utilisateur
qui peut naviguer au seind'un
graphe enrichi de cubes selon differents niveaux d'analyse, avec des opdrateurs d6di6s.)
Travaux
deAmine
Ghrab
et al. <<A Framework for Building OLAP
Cubes onGraphs
>>Dans le travuL de
([19]),
Amine Ghrab et des co-auteurs ont propos6 un cadre pourconstruire des cubes
OLAP
d partir de donndes orient6es graphe et analyser les propri6tds topologiques du graphe. Le cadre prend en charge I'extraction et la conception des espacesmultidimensionnels candidats dans les graphes de propri6t6s (property graphs). Outre les graphes de propri6t6s, un nouveau moddle de base de donndes adaptd d la mod6lisation multidimensionnelle et permettant I'exploration d'espaces multidimensionnels candidats suppl6mentaires est introduit. Ils prdsentent de nouvelles techniques pour I'agr6gation
OLAP
du graphe, et discutent le cas des hi6rarchies de dimension dans les graphes. De plus,
I'architectwe et la mise en Guvre de leurs travaux de cadre d'entreposage de graphes sont prdsentdes et
montrent
1'efficacit6 de leurs approches.7.
Conclusion
Dans ce chapitre nous avons pr6sent6 I'entrep6t de donndes, ses caractdristiques,
l'architecture fonctionnelle et la notion de cube de donn6es, et aussi on parle de concept
OLAP
et sesdiftrentes
opdrations. Par la suite nous avons pr6sent6 leBig
Data, ses caract6ristiques, les outils utilis6s dans ses sc6narios. Ensuite, nous avons prdsent6les data lakes, leur limites et la diffdrence avec l'entrep6t de donn6es. Nous avons 6galement prdsentd les bases de donn6esNoSQL, leurs types et leurs avantages. Enfin, nous avons pr6sent6 quelques travaux de recherche en croisement entre les entrep6ts de donn6es avec le NoSQL.
Chapitre
2
:
Pr6sentation
de
l'6tude
de
cas
l.Introduction
...
...232. Pr6sentation de
systime
d'enseignementsup6rieur
indien
.-...232.1. Enseignement
sup6rieur...
...232.2.Type
d'institutions...
...243. Donn6es 6ducatives de I'enseignement
sup6rieur
indien...
...253.1. Description des
donndes
...253.2. Mod6lisation logique (relationnelle) des donndes
6ducatives
....26
4. Exemples de besoins
d'analyse
...285.
Opportunit6
de Iarepr6sentation
des donn6es 6ducativespar un
graphe
....32
6.
Conclusion...
...33Chapitre2
tp.6t*@
l.Introduction
Dans ce chapitre, nous prdsentons le domaine d'application de notre travail qui est l'enseignement sup6rieur. Dans ce contexte, et pour le besoin d'appliquer noffe travail ir des donnfes massives, notamment en termes de volume, notre choix a port6 sur le systdme
d'enseignement sup6rieur de
I'Inde,
et ce, vu la population de cepays
qui a enregistte 1,26milliards
d'habitantsen20l6 (I7%
de la population mondiale) selon Wikip6dia, cela d'unepart. Le besoin d'analyser des donn6es massives du domaine de l'enseignement sup6rieur nous a conduites d chercher des donndes volumineuses disponibles gratuitement. Dans ce sens, les donndes de l'enseignement sup6rieur indien satisfont nos besoins.
Dans ce chapitre, nous pr6sentons d'abord le systdme d'enseignement sup6rieur de
l'Inde.
Par la suite, nous pr6sentons les donn6es 6ducatives que nous avons utilis6es dans notre travail.Aussi, nous pr6sentons de exemples de besoins d'analyse sur css donn6es. Enfin, nous
motivons
l'utilisation
d'une base de don:r6es orientde graphes pour l'analyse de donn6es dducatives.2.
Pr6sentation
de
systime
d'enseignement
sup6rieur indien
Le systdme d'enseignement supdrieur indien est similaire au systdme alg6rien. Un dipldme
de Bachelor peut Otre obtenu en trois ann6es d'6tudes (quatre pour les frlidres d'ing6nierie). Les Masters peuvent par la suite Otre ddcroches en une ou deux ann6es d'6tudes suppl6mentaires,
pour finalement mener au doctorat en trois anndes d'6fudes additionnelles [20].
L'enseignement indien a tent6 de r6pondre d la demande en provoquant une expansion de grande envergure.
Ainsi,
entre les ann6es 2000et 20l0,ce
sont quelques 20.000 < colldgesl>qui ont 6t6 cr66s, accueillant plus de 3.000.000 dtudiants suppl6mentaires. D'aprds
I'UNESCO,
le nombre total d'6tudiants indiens 6tait, en 2013, de28,2millions
(pour 34millions
d'6tudiants chinois).
2.1.
Enseignement
sup6rieur
Une enqu€te a 6t61anc6e par le ministdre du d6veloppement des ressources humaines indien
(MHRD),
qui calcule des statistiques pour construire une 6tude sur l'enseignement sup6rieur au 23 septembre 2010. Le rapport de cette enquOte ddfrnit I'enseignement sup6rieur cofilme unet
Nous utilisons leterme
collEge dans le sens anglais comme 6tant un 6tablissementChapitre 2
:pr6sentation
del'6tude
de cas dducation qui est obtenue aprds avoir termind 12 anndes de scolaritd ou l'6quivalent de la dur6e d'au moins neuf mois (d temps plein), ou aprds 10 ann6es de scolarit6 de la dur6e d'au moins 3ans. L'6ducation peut Otre de la nature de 1'6ducation g6ndrale, professionnelle ou technique
l2rl.
2.2.
Type
d'institutions
Toutes les institutions, dans lesquelles I'enseignement sup6rieur est
ddfini
ci-dessus, seront couvertes par cette enqu6te. Les dtablissements couverts ont 6t6 classds en trois grandes catdgories:/
Etablissements universitaires/
Colldges/
dtablissements - affilids / reconnus avec I'Universit6/
Etablissements autonomes - non afFrlids / reconnus avec I'universitd)
Etablissementsuniversitaires
En vertu de la
loi
de 1956 sur la Commission des subventions universitaires (UGC), universitd signifie Universit6 dtablie ou constitude en vertu d'uneloi
centrale, d'uneloi
provinciale ou d'une
loi
d'Etat et comprenant toute institution qui en consultation avec 1'universit6 int6ress6e, peut 0tre reconnue par Ia Commission conformdment aux rdglementspris en application de la pr6sente
Acte
[21].Ce sont des institutions qui peuvent mener des programmes d'6tudes, mais ne sont pas habilit6es d
fournir
un dipldme de leur propre chef et doivent ndcessairement Otre attachds avec un Institution de niveau universitaire / universitaire dans le but d'obtenir un dipl6me. Pour le but de I'enqu6te ces institutions ont 6td class6es coflrmssuit
[21]
:F
Cotldgesaffili6s
i
desinstitutions
de niveauuniversitaire
Les colldges peuvent 6tre de deux types :
(i)
Colldge universitaire/
constitutif - Un colldge maintenu par I'Universit6(ii)
Colldgeaffilid
)
Institutions
reconnuespar
I'Universit6
Chapitre 2
:pr6sentation
deI'6tude
de casI1 existe plusieurs institutions qui ne reldvent pas de I'Universitd et du Colldge.
Ces institutions gdrent g6n6ralement des prograrnmes de niveau Dipl6me / PG pour
lesquels elles doivent 6tre reconnues par I'un ou l'autre des organismes statutaires.
Aux
fins de l'enquOte, ces institutions seront consid6rdes cofllme des institutions autonomes. Cesinstitutions reldvent principalement des catdgories suivantes
[21]
:r
Institut indien de gestion(IIM)
ddcernant principalement PG Dipldme en gestion de dur6e de deux ans dont la qualification d'entrde est dip16m6e.e
Polytechniqueso
Secr6taire d'entreprise, comptable agr66, science actuarielle, etc.3.
Donn6es
6ducatives
de
I'enseignement
sup6rieur indien
Grdce au
Big
Data eti
l'essor del'informatique
et du num6rique dans l'6ducation, l'analysedes donn6es permet ddsormais d'amdliorer les systdmes scolaires et 6ducatifs du monde entier.
Pour le besoin d'analyser des donn6es massives li6es d 1'6ducation, et vu la disponibilit6 des donndes de ce domaine pour
l'lnde,
cela nous a permis de cibler ces donndes couvrant cinqanndes universitaire cons6cutives (de l'ann6e universitaire
20ll-2012jusqu'i
l'ann6euniversitaire 20 | 5 -2A
rc).
Les donn6es sont disponibles sur le site https://www.kasgle.com/rajanand/aishe/version/1.
Les donn6es de l'enseignement sup6rieur indien ont 6t6 collect6es dans le cadre d'un projet
AISI{E (All
Indian Survey On Higher Education)initid
par le ministdre indien dud6veloppement des ressources humaines.
L'objectif
6tantd'identifier
et de capturer toutes lesinstitutions d'enseignement sup6rieur et de collecter les donn6es sur ces institutions relatives d divers aspects.
3.1.
Description
des
donn6es
Les donndes collect€es dans
le
cadre du projetAISHE
et utilisdes dans notre travarl portentntation
del'6tude
de casLes informations d6taill6es sur les institutions Les informations d6tai1l6es des enseignants Les informations du personnel non enseignant
Les offres d,enseignement dans les facu1t6s, les 6coles, les d6partements et les centres Les r6sultats d,examens de la demidre annde d'6tude de chaque offre de
formation
Les informations financidres notamment de r6ception et de ddpenses'La disponibilitd des infrastructures
Les bourses, les pr6ts et les accrdditations
3.2.
Mod6lisation
togique
(relationnelle)
des donn6es dducatives
Les donndes que nous avons utilisdes sont disponibles en format
csv
et correspondent pratiquement d des donn6es structur6es du niveau physique' Pour mieux comprendre ces donn6es, nous avons proc6dd d la constructiond'un
sch6marelationnel
paf reverseengineering, ce qui a conduit d un grand nombre de tables relationnelle. Nous avons choisi de ne pas remonter jusqu'au niveau conceptuel avec le moddle conceptuel de donndes
(MCD)
ou le moddle Entitd Association vu que cela engendrera 6norm6ment d'associations entre les entit6s et donc aboutira d un moddle complexe'Le sch6ma
suivant
reprdsente le schdma relationnel des donn6es 6ducatives que nous l,avons r6a1is6 parl',outil
<< yed >> et on l',utilise dans cetravail (voir figure
2'I)'Le
sch6ma estpr6sent6 d
titre illustratif
pour montrer le grand nombre de tables relationnelles ainsi que lesdivers liens de type pdre-frls entre les tables'
o a a a
Chapitre 2
:pr6sentation
de ln6tude de casT----.
I I
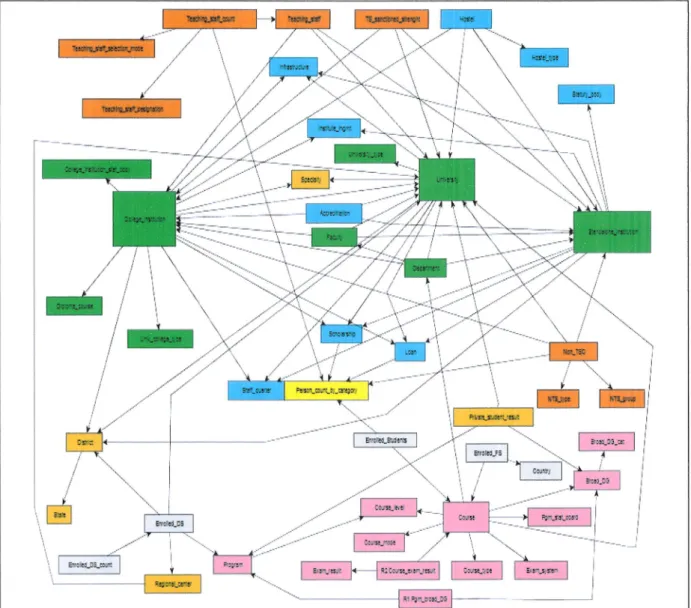
Figure 2.1 : Sch6ma relationnel de donndes dducatives
pens ce sch6ma, les formes rectangulaires reprdsentent les tables relationnelles en nombre
de 47 tables
qui
comportent des attributs parmi lesquels une cl6 primaire identifie de manidre tmique chaque occrrrence de la table et dventuellement une ou plusieurs c16s dtrangdresqui
sont des cl6s primaires dans une autre table.Ces
tables
sont li6es entreelles
avec
desfldches
qui
reprdsentent des liens fils-pdre (dufils
vers le pdre), dans le sens que la fldche d6marrei
partir de la table qui contient la cl6 dtrangdre vers la table qui possdde la cl6 primaire. Dans le cas des associations hi6rarchiques (de type [1,n]),
la cl6 primaire correspondant d I'entit6 pdre (c6t6 1) migre comme cl6 dtrangdre dans la relation correspondant d I'entit6fils
(c6t6n)
etpour
les associations non hi6rarchiques (de type [n,n]),
elles deviennent une relation < table Dcomme
dans notre sch6ma deux tables portant le nom dePgm_broad_DG
et
Course_exam_result.Chapitre 2
:pr6sentation
del'6tude
de casLa figure 2.2 illustre une partie de sch6ma relationnel plus iisible.
Figure 2.2 : partie de Sch6ma relationnel de donndes 6ducatives
4.
Exemples
de
besoins
d'analyse
*R6ponses
des
universit6s au
projet AISHE
En2016-2A17
,864
universit6s figurant sur le portailAISHE
devaient t6l6charger lesdonndes. Le nombre d'universitds avec leurs types est indiqu6 dans le tableau 2.1. Les d6tails de type des 864 universit6s sont donn6s ci-dessous. Parmi eux 795 universit6s ont t6l6chargd les donndes au cours
de
2016-2017et
sont arrivdes d de meilleurs indicateurs dducatifs, 40universitds ayant tdldchargd les donn6es soit en 2014-2A15 soit en 2015-2016, mais pas au
cours de2016-17 [22].
Type of
university
Numberof
Universities Number
of
Responsel_ 13 337 1 10 835 Central OpenUniversity
Central Universiry
Deemed University- Goverrrment
Institution
Under State Legislature ActInstitution
of National lmportanceDeemed University- Private state Private
university
State Open University State Public University
State Private Open University
Deemed University- Government Aided
Grand Total 1 44 33 5 100 79 233 1 42 33 4 94 79 221 13 345 1 10
864
Tableau 2.1 : Rdponse des universitds en 2016-2017 l22l
![Figure 1.1 : Architecture g6n6rale d'un entep6t de donndes [4]](https://thumb-eu.123doks.com/thumbv2/123doknet/14530836.723527/17.892.161.736.107.433/figure-architecture-g-n-rale-entep-t-donndes.webp)
![Figure 1.3 : Architecture fonctionnelle d'un entrep6t de donndes [6]](https://thumb-eu.123doks.com/thumbv2/123doknet/14530836.723527/18.892.168.750.798.1093/figure-architecture-fonctionnelle-entrep-t-donndes.webp)
![Figure 1.4 : Cube de donn6es [7]](https://thumb-eu.123doks.com/thumbv2/123doknet/14530836.723527/20.892.99.785.107.430/figure-cube-de-donn-es.webp)
![Figure 1.5 : Illushation d'une Base de donndes orientde cl6 /valeur [16]](https://thumb-eu.123doks.com/thumbv2/123doknet/14530836.723527/27.892.120.810.632.893/figure-illushation-base-donndes-orientde-cl-valeur.webp)
![Figure 1.6 : Illustration d'une base de donndes orientde document [6]](https://thumb-eu.123doks.com/thumbv2/123doknet/14530836.723527/28.892.119.804.151.457/figure-illustration-base-donndes-orientde-document.webp)
![Figure 1.8 : Illustration d'une Base de donndes orient6e graphe [16]](https://thumb-eu.123doks.com/thumbv2/123doknet/14530836.723527/30.892.145.790.109.400/figure-illustration-base-donndes-orient-e-graphe.webp)
![Figure 1.9 : Reprdsentation logique orientde graphe selon [17]](https://thumb-eu.123doks.com/thumbv2/123doknet/14530836.723527/31.892.121.774.812.1126/figure-reprdsentation-logique-orientde-graphe-selon.webp)
![Figure 2.3 : Rdpartition des universitds r6pondantes selon la sp6cialisation [22]](https://thumb-eu.123doks.com/thumbv2/123doknet/14530836.723527/40.892.209.683.144.431/figure-rdpartition-universitds-r-pondantes-sp-cialisation.webp)
