Blind calibration for compressed sensing: State evolution and an online algorithm
Texte intégral
Figure
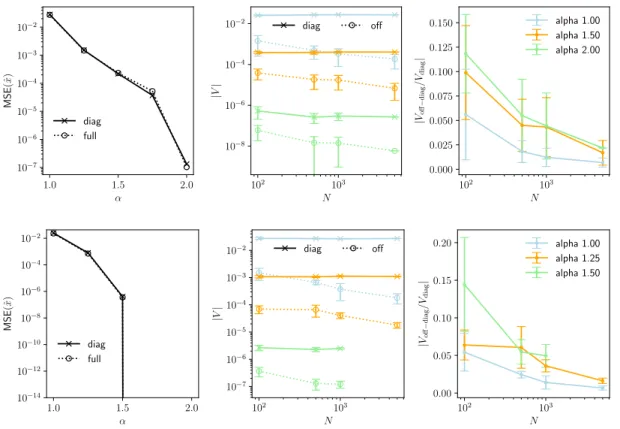
![Figure 3: Comparison of mean squared errors in reconstructing the signal X 0 using cal-AMP and predicted by SE for the gain calibration problem with calibration variables uniformly distributed in [0.95, 1.05] and N = 10 4](https://thumb-eu.123doks.com/thumbv2/123doknet/12857445.368319/23.918.194.719.254.800/comparison-reconstructing-predicted-calibration-calibration-variables-uniformly-distributed.webp)
![Figure 4: Normalized cross correlation between cal-AMP estimate X ˆ and teacher signal X 0 for the gain calibration problem with calibration variables uniformly distributed in [0.95, 1.05] and N = 10 3](https://thumb-eu.123doks.com/thumbv2/123doknet/12857445.368319/24.918.126.800.256.704/normalized-correlation-estimate-calibration-calibration-variables-uniformly-distributed.webp)
![Figure 5: Normalized cross correlation between cal-AMP estimate ˆ s and teacher signal s 0 for the gain calibration problem with calibration variables uniformly distributed in [0.95, 1.05] and N = 10 3](https://thumb-eu.123doks.com/thumbv2/123doknet/12857445.368319/25.918.119.804.277.730/normalized-correlation-estimate-calibration-calibration-variables-uniformly-distributed.webp)
Documents relatifs
The primitive BSP EXCHANGE send each state s for a pair (i, s) in tosend to the processor i and returns the set of states received from the other processors, together with the
In this paper, we derive the theoretical performance of a Tensor MUSIC algo- rithm based on the Higher Order Singular Value Decomposition (HOSVD), that was previously developed
In this paper we have tested three different image stitching algorithms applied over our optical probe which provides at the same time two types of panoramic images of the
creation of a more complex species is like a prime number, unpredictable, discontinuous, and 20.. yet can be modeled by a smooth curve in relation
✓ Europe - Nomenclature of Territorial Units for Statistics (NUTS) 4 versions, 4 levels, 7619 geographic units. 122,000 resources describing
conjugate gradient, deflation, multiple right-hand sides, Lanczos algorithm AMS subject classifications.. A number of recent articles have established the benefits of using
shown here, rule 8 Elim allows the universally quantied type variables to be. instantiated using an
The primitive BSP EXCHANGE send each state s for a pair (i, s) in tosend to the processor i and returns the set of states received from the other processors, together with the
