Random sampling and machine learning to understand good decompositions
25
0
0
Texte intégral
(2)
(3)
(4)
(5)
(6)
(7)
(8)
Figure

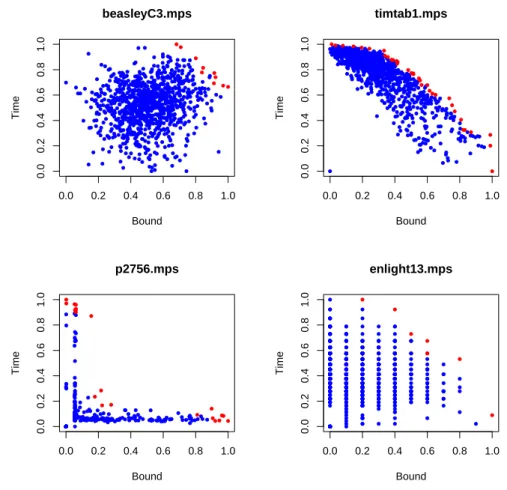


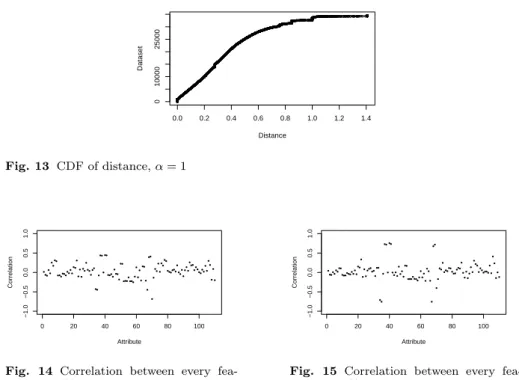
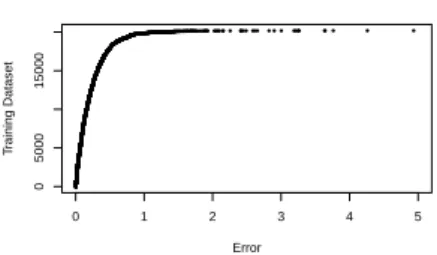
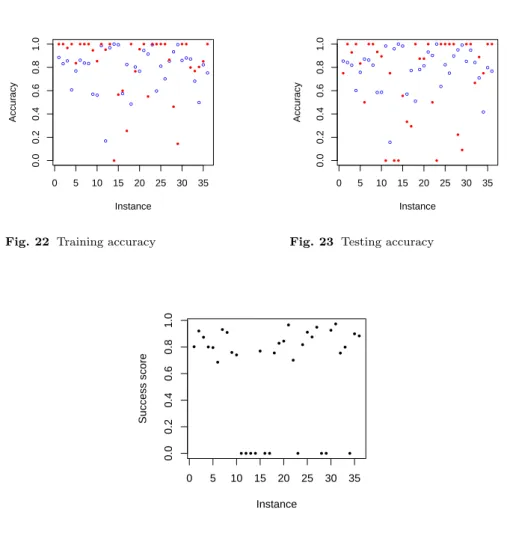
+7



Documents relatifs
Supervised learning : building an input-output model from the observation of a large set of data in order to predict the target value of new examples.. Reinforcement learning :
Michael Guedj, Laëtitia Marisa, Aurélien de Reynies, Béatrice Orsetti, Renaud Schiappa, Frédéric Bibeau, Gaëtan Macgrogan, Florence Lerebours,.. Pascal Finetti, Michel Longy,
Two complementary problems are solved by this proposal: (i) we understand the order of size of the cosmological constant, linked to the typical confinement scale ≈ 70 MeV; (ii)
In the more general case where the point source is not located on the optical axis but at coordinates (x, y, z), analytical expressions of resolution can be obtained using the
• On the border of the region ℜ + L located inside the first octant, there exist a single direct kinematic solution, which corresponds to the “flat” manipulator
Local chiral axis in a directional medium and wedge component of a disclination... 2014 On démontre l’existence d’un ensemble de surfaces caractéristiques d’une
2014 We have calculated the zero temperature magnetization of the random axis chain in the limit of strong anisotropy and small magnetic field h.. [ 1] to describe
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
