Event-Scheduling Algorithms with Kalikow Decomposition for Simulating Potentially Infinite Neuronal Networks
Texte intégral
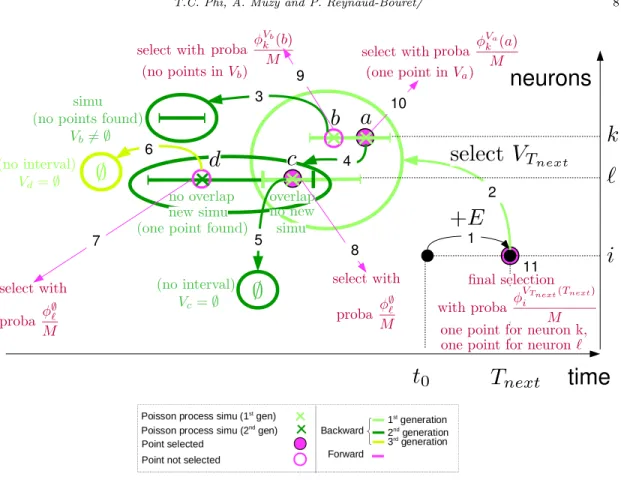
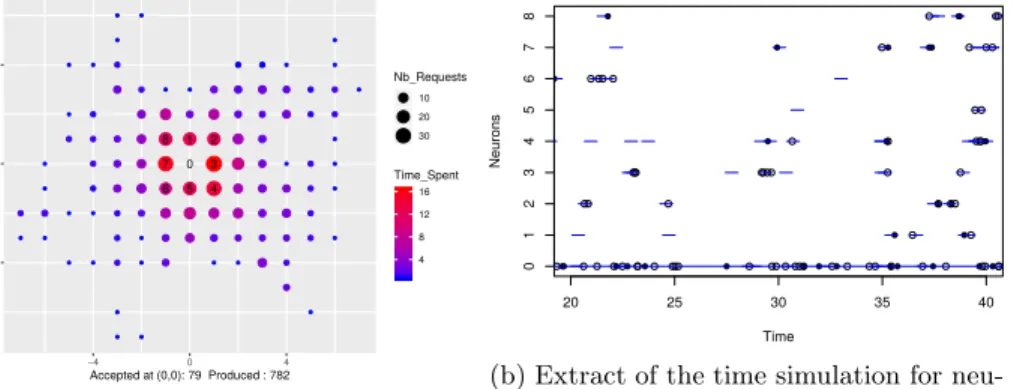
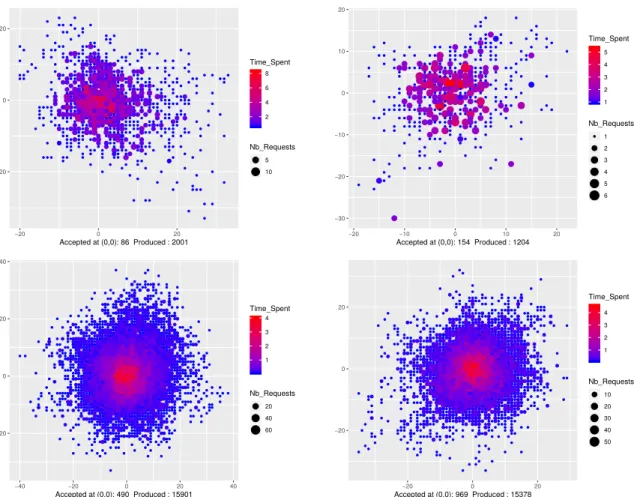
Figure
Documents relatifs
An accurate simulation of the biomass gasification process requires an appropriately detailed chemistry model to capture the various chemical processes inside the
Fatigue levels were high in this large cohort of patients with symptoms suggestive of early.. axSpA, independently of the fulfillment of the ASAS
Thus, addressing anxiety and depression through the concentrated breath work practices, physical postures, and meditation of yoga may be an additional way for mental
Our proposed finite method SeROAP computes rank-1 approximations based on a sequence of singular value decompositions followed by a sequence of projections onto Kronecker vectors.
And what is more, the relevant measure really is not subject to quantification by any practicable clinical trials; realistic assessment of its magnitude requires
In order to achieve this goal, we use algebraic methods developed in constructive algebra, D-modules (differential modules) theory, and symbolic computation such as the so-called
Parmi ces nombreux auteurs, nous nous sommes arrêtés sur Dostoïevski et Boudjedra non point pour leurs parcours ou leur notoriété mais pour deux raisons : la première est la
Heute sind Jugendliche längst nicht mehr Subjekt eigener Forschungen sondern Objekt von WissenschaftlerInnen, JournalistInnen und PädagogInnen, deren Intentionen sie in der Regel
