Publisher’s version / Version de l'éditeur:
Vous avez des questions? Nous pouvons vous aider. Pour communiquer directement avec un auteur, consultez la
première page de la revue dans laquelle son article a été publié afin de trouver ses coordonnées. Si vous n’arrivez pas à les repérer, communiquez avec nous à [email protected].
Questions? Contact the NRC Publications Archive team at
[email protected]. If you wish to email the authors directly, please see the first page of the publication for their contact information.
https://publications-cnrc.canada.ca/fra/droits
L’accès à ce site Web et l’utilisation de son contenu sont assujettis aux conditions présentées dans le site LISEZ CES CONDITIONS ATTENTIVEMENT AVANT D’UTILISER CE SITE WEB.
18th International Congress on Acoustics [Proceedings], pp. V-3587-3588,
2004-04-01
READ THESE TERMS AND CONDITIONS CAREFULLY BEFORE USING THIS WEBSITE.
https://nrc-publications.canada.ca/eng/copyright
NRC Publications Archive Record / Notice des Archives des publications du CNRC :
https://nrc-publications.canada.ca/eng/view/object/?id=ce6f2b4b-681d-4bf2-a8fe-9feba866e3e6 https://publications-cnrc.canada.ca/fra/voir/objet/?id=ce6f2b4b-681d-4bf2-a8fe-9feba866e3e6
NRC Publications Archive
Archives des publications du CNRC
This publication could be one of several versions: author’s original, accepted manuscript or the publisher’s version. / La version de cette publication peut être l’une des suivantes : la version prépublication de l’auteur, la version acceptée du manuscrit ou la version de l’éditeur.
Access and use of this website and the material on it are subject to the Terms and Conditions set forth at
Speech security thresholds for closed offices
Gover, B. N.; Bradley, J. S.
Speech security thresholds for closed offices
Gover, B.N.; Bradley, J.S.
NRCC-46883
A version of this document is published in / Une version de ce document se trouve dans : 18th International Congress on Acoustics, Kyoto, Japan, April 4-9, 2004, pp. V-3587-3588
Speech Security Thresholds for Closed Offices
Bradford N. Gover and John S. Bradley
Institute for Research in Construction,
National Research Council, 1200 Montreal Road, Ottawa, Ontario K1A 0R6 Canada
[email protected]Abstract
Conversations occurring within closed offices can frequently be audible or intelligible to some degree outside of the room containing the talkers. Three speech security thresholds can be defined: Threshold of Audibility, where the speech sounds are just audible; Threshold of Cadence, where the overheard sounds are just recognizable as speech possessing rhythm or cadence; and Threshold of Intelligibility, where the overheard speech is just intelligible. English sentence listening tests have been used to explore these thresholds. Subjects listened to a large number of sentences representing a wide range of acoustical conditions, and repeated the words they could understand, or stated whether or not they could identify the speech or its cadence. A frequency-weighted signal-to-noise measure has been found to be a superior predictor of the threshold of intelligibility than the articulation index (AI), the speech intelligibility index (SII), and the A-weighted level difference between speech and background noise. The A-weighted level difference is, however, a good predictor of the thresholds of cadence and audibility.
1. Introduction
At the position of a listener outside of a room containing a talker, the level of speech security can be described in terms of three thresholds: Threshold of Intelligibility (below which no words are intelligible), Threshold of Cadence (below which the cadence of the speech is not recognizable), and Threshold of Audibility (below which the speech is not audible).
Speech security can be related to objective measures computed from the spectra of the transmitted speech and of the background noise at the position of the listener [1]. Such measures include the Articulation Index (AI), the Speech Intelligibility Index (SII), the difference of A-weighted speech and noise levels, and a new weighted signal-to-noise ratio measure.
2. Experimental
procedure
Subjective listening tests were performed to evaluate the suitability of several objective measures for rating speech security. Individual subjects sat in a sound-isolated room facing loudspeakers that replayed English sentences [2] that had been filtered to represent
transmission through various types of walls. Background ventilation-type noise was also played at the same time as the sentences, through loudspeakers located above the ceiling over the subject’s head. Subjects were screened for minimal hearing loss, and were fluent in English. In total, 500 different combinations of speech level, wall type, and noise level and spectral shape resulted in a large range of simulated security conditions presented to each of 19 subjects. After each test sentence was played, the subject repeated the words they could understand, or stated whether the speech or its cadence was audible.
3. Objective
measures
Several objective measures were computed from spectral measurements of the “transmitted” speech and of the background noise. These included AI, SII, the difference of A-weighted levels of speech and noise, and a new measure: SII-weighted signal-to-noise ratio, computed as the weighted sum of 1/3-octave band signal-to-noise ratios, using as weights the band importance function coefficients from Ref. [3].
4. Results
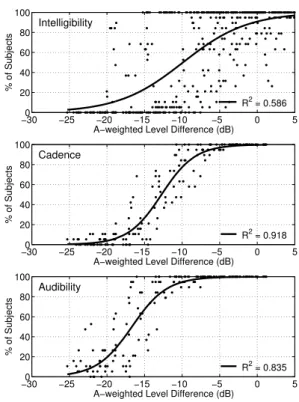
For each test sentence, the percentage of subjects able to identify: i.) at least one word, ii.) the cadence of the speech (including those identifying words), and iii.) the speech itself (including those identifying cadence or words) was computed. The results for the Intelligibility threshold only are shown in Fig. 1 plotted versus AI and SII. The results for all three thresholds are plotted versus A-weighted level differences in Fig. 2 and versus SII-weighted signal-to-noise in Fig. 3. The curve on each graph is the least-squares best-fit
Boltzmann function; the R2 is given for each. Higher
R2 indicates a stronger relationship between the
subjective responses and the objective measure.
Notice from Fig. 1 that AI and SII are well correlated with the Threshold of Intelligibility, but do not correspond to zero intelligibility at their minimum values of 0, nor do they provide any information below zero intelligibility. Fig. 2 indicates that the difference of A-weighted levels is poorly correlated with the Threshold of Intelligibility, but well correlated with those of Cadence and Audibility. From Fig. 3, notice
0 0.2 0.4 0.6 0.8 1 0 20 40 60 80 100
Articulation Index (AI)
% of Subjects Intelligibility R2 = 0.889 0 0.2 0.4 0.6 0.8 1 0 20 40 60 80 100
Speech Intelligibility Index (SII)
% of Subjects
Intelligibility
R2 = 0.904
Figure 1: Threshold of Intelligibility versus AI (top) and SII (bottom). AI and SII are not defined below 0. that SII-weighted signal-to-noise is well correlated with all three thresholds. For example, at a value of –15 dB, 91% of the subjects could hear the speech, 82% could hear the cadence, and 21% could understand at least one word. The sound insulation would have to be increased to drop this index to a value of –23 dB to ensure that the speech would be inaudible to all but 20% of the listeners.
5. Conclusions
AI and SII, which are good indicators of speech intelligibility in many situations, are not ideal for rating speech security of rooms. A-weighted level difference is a good predictor of audibility of speech or its cadence, but not of intelligibility. SII-weighted signal-to-noise ratio is much better for predicting security thresholds, especially that of intelligibility.
This new measure can be used to rate the speech security of existing rooms, or as a design criterion for new or renovated constructions.
6. Acknowledgements
Funding from Public Works and Government Services Canada and the Royal Canadian Mounted Police gratefully acknowledged. Thanks also to all the subjects who each volunteered several hours of their time.
7. References
[1] W. J. Cavanaugh et al., J. Acoust. Soc. Am., 34, 475-492 (1962).
[2] IEEE Trans. Audio and Electroacoustics, 227-246 (1969). [3] ANSI S3.5-1997 −300 −25 −20 −15 −10 −5 0 5 20 40 60 80 100
A−weighted Level Difference (dB)
% of Subjects Intelligibility R2 = 0.586 −300 −25 −20 −15 −10 −5 0 5 20 40 60 80 100
A−weighted Level Difference (dB)
% of Subjects Cadence R2 = 0.918 −300 −25 −20 −15 −10 −5 0 5 20 40 60 80 100
A−weighted Level Difference (dB)
% of Subjects
Audibility
R2 = 0.835
Figure 2: Thresholds versus A-weighted level difference of transmitted speech and background noise (dB). −300 −25 −20 −15 −10 −5 0 5 20 40 60 80 100 SII−weighted Signal−to−Noise (dB) % of Subjects Intelligibility R2 = 0.925 −300 −25 −20 −15 −10 −5 0 5 20 40 60 80 100 SII−weighted Signal−to−Noise (dB) % of Subjects Cadence R2 = 0.848 −300 −25 −20 −15 −10 −5 0 5 20 40 60 80 100 SII−weighted Signal−to−Noise (dB) % of Subjects Audibility R2 = 0.701
Figure 3: Thresholds versus SII-weighted signal-to noise-ratio (dB).