AnnoTool: Crowdsourcing for Natural Language Corpus
Creation
by
Katherine Hayden
B.A., Bennington College (2011)
Submitted to the Program in Media Arts and Sciences,
School of Architecture and Planning
in partial fulfillment of the requirements for the degree of
Master of Science in Media Arts and Sciences
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
@
Massachusetts
September 2013
Institute of Technology 2013. All rights reserved.
MASSACHUSETTS INSTITUTE -F TECHNOLOGY
JUL
14
2014
LIBRARIES
Signature redacted
Author ...
Projram in Media Arts and Sciences
September 10, 2013
Signature redacted
Certified by . . .
Catherine Havasi
Assistant Professor of Media Arts and Sciences
Signature redacted
Thesis Supervisor
Accepted by. ...
.
...
Patricia Maes
Associate Academic Head, Program in Media Arts and Sciences
AnnoTool: Crowdsourcing for Natural Language Corpus Creation
by
Katherine Hayden
Submitted to the Program in Media Arts and Sciences, School of Architecture and Planning
on September 10, 2013, in partial fulfillment of the requirements for the degree of
Master of Science in Media Arts and Sciences
Abstract
This thesis explores the extent to which untrained annotators can create annotated corpora of scientific texts. Currently the variety and quantity of annotated corpora are limited by the expense of hiring or training annotators. The expense for finding and hiring professionals increases as the task becomes more esoteric or requiring of a specialized skill set. Training annotators is an investment in itself, often difficult to justify. Undergraduate students or volunteers may not remain with a project for long enough after being trained and graduate students' time may already be prioritized for other research goals.
As the demand increases for computer programs capable of interacting with users through natural language, producing annotated datasets with which to train these programs is becoming increasingly important.
This thesis presents an approach combining crowdsourcing with Luis von Ahn's "games
with a purpose " paradigm. Crowdsourcing combines contributions from many participants
in an online community. Games with a purpose incentivize voluntary contributions by pro-viding an avenue for a task people are already incentivized to do, and collect data in the background. Here the desired data are annotations and the target community people anno-tating text for professional or personal benefit, such as scientists, researchers or the general public with an interest in science.
An annotation tool was designed in the form of a Google Chrome extension specifically built to work with articles from the open-access, online scientific journal Public Library of
Science (PLOS) ONE. A study was designed where participants with no prior annotator
training were given a brief introduction to the annotation tool and assigned to annotate three articles. The results of the study demonstrate considerable annotator agreement.
The results of this thesis demonstrate that crowdsourcing annotations is feasible even for technically sophisticated texts and presents a model of a platform that continuously gathers annotated corpora.
Thesis Supervisor: Catherine Havasi
AnnoTool: Crowdsourcing for Natural Language Corpus Creation
by
Katherine Hayden
The following people served as readers for this thesis:
Thesis Reader.
Signature red acted
Cynthia Breazeal
Principal Research Scientist
Media Lab
Signature redacted
Thesis Reader..
Sepandar Kamvar
Principal Research Scientist
Media Lab
Acknowledgments
My advisor, Catherine Havasi, for mentoring and inspiring me. From Principal Researcher
at MIT Media Lab to CEO of your own startup Luminoso, you demonstrate that with un-usual intelligence and unbelievable hard work, anyone can simultaneously succeed at mul-tiple challenging roles. Thank you for your ever-illuminating feedback and smart advice.
Cynthia Breazeal and Sep Kamvar who generously served as my readers. Your
guid-ance was critical and kept me on the right course.
Linda Peterson, for her saintly patience and practical impatience. Thank you for your
genuince care, excellent admin and heartwarming faith in me.
Joi Ito, for adopting the Media Lab two years ago and caring for its people like your
extended family. You have a heart of gold.
Friends from many communities: The particularly excellent crop of human beings that made up New Grads 2011, whose brilliance and playfulness made for delightful company. The community surrounding the MIT Triathlon and Cycling teams, where I found a side of my life I had been missing and heroes in my teammates. My roommates RJ Ryan and Zack
Anderson, who rubbed off on me in so many little ways, from allegiance to The One True
Editor to sharper peripheral vision for live wires.
Finally, my family, who encouraged me from afar and to whom I owe my next few holidays.
Contents
1 Introduction 11
2 Background 15
2.1 Data Quality. . . . .. . . . . 15
2.2 Games With a Purpose . . . . 17
2.3 ConceptNet . . . .. . . . . 18 3 Technology 21 3.1 Backend . ... . .. . . . .. . . . .. . . .. . .. . . . . 21 3.2 User Interface . . . .. . . . . 22 4 Study 27 4.1 Testers . . . . 27 4.2 Setup . . . . 28 4.3 Tags . . . . 29
5 Results and Conclusion 33 5.1 Study participants . . . . 33 5.2 Tag Usage . . . . 33 5.3 Time . . . 35 5.4 Feedback . . . . 36 5.5 Inter-Annotator Agreement . . . . 39 5.6 Conclusion . . . . 43
Chapter 1
Introduction
Technology is an ongoing march towards better and more impressive iterations of current tools and applications. Computer software has followed this trend since the 1950s, when the earliest group of professional programmers first secured access to slices of time to tinker with the cutting edge mainframe computers of the day and pioneers established the research field of Artificial Intelligence at a Dartmouth conference. Ever since, researchers in the field have been driven by questions such as, "How do we make a machine intelligent enough that a human conversing with it could mistake it to be not a machine, but a person?" Attempts to build such machines revealed the previously underrated difficulty of en-gineering a system that approached anything even resembling intelligence. However, the attempt to do has had beneficial outcomes. It has produced smarter applications, such as voice recognition software capable of recognizing and translating spoken into written speech. It has also spawned new fields, such as Natural Language Processing, the goal of which is to enable computers to derive meaning from human language.
The combination of these technologies produced natural language applications which take spoken user input, transcribe it to text and analyze its meaning using models of lan-guage developed through natural lanlan-guage processing. Although these programs' intelli-gence is limited to performing a specific range of tasks, they are certainly valuable tools, as evidenced by the increasing prevalence of their usage.
Apple iPhone 4s users have access to Siri [6, 52], Apple's intelligent personal assistant which is capable of answering questions and performing actions commanded by the user,
such as searching for local businesses and setting appointments on the phone's calendar. A study released in late March of 2012 found that 87% of iPhone 4s owners used Siri [11]. At that time Siri had been available for Q4 2011 and Qi 2012, in which 7.5 million iPhone units and 4.3 million were activated, respectively. That results in an estimate of 10.3 million Siri users by March 2012.
Web users have access to Wolfram Alpha, an online 'knowledge engine' that computes an answer directly from the user's query, backed by a knowledge base of externally sourced, curated structured data [65]. Wolfram Alpha can answer fact-based queries such as where and when a famous person was born. It can even decipher more complex queries such as "How old was Queen Elizabeth II in 1974?" Usage statistics for Wolfram Alpha estimate
2.6 million hits, or page visits, daily [67, 68].
In addition to these major players, there is continued investment in and development of many new natural language applications [17, 24, 36, 37, 55, 70].
However, despite the popularity of such applications, users have reported feeling dis-appointed in the gap between their expectations of these applications and their true perfor-mance.
Some argue that as a program presents itself with more human-like attributes, for exam-ple communicating in natural language, peoexam-ple become more likely to have unreasonable expectations of it to be as intelligent as a human and get frustrated when it doesn't perform with real intelligence.
Others argue that these applications were overly hyped and are angry enough to sue when they don't perform as advertised [32, 35].
Regardless of the source of these overly high expectations, there is a common theme of disappointment in the lack of sophistication: "And for me, once the novelty wore off, what
I found was that Siri is not so intelligent after all - it's simply another voice program that will obey very specific commands" [35].
People want natural language applications with more range in their knowledge of the world and more intelligence about how they can interact with it.
One effective way to create smarter natural language applications is to use supervised machine learning algorithms. These algorithms are designed to extrapolate rules from the
knowledge base of texts they are given in order to apply those rules to unseen circumstances in the future [45, 46]. Supervised machine learning algorithms take annotated text as input. This text has been augmented with metadata that helps the algorithm identify what are the important elements and the categories in which they should be classified.
This approach is effective but suffers from the bottleneck of creating a large number of annotated corpora, or bodies of text. Annotated corpora are expensive to make and they require someone to initiate creating them [8]. The result of this is that existing annotated corpora are concentrated in fields that are well-funded or of potential commercial interest. Fields that are not well-funded or seemingly lucrative lack annotated datasets. In gen-eral, this includes most scientific fields, with the exceptions of certain biomedical fields which are well-funded and for which there have been attempts in the past to create natural language applications to assist doctors. Examples include programs that operate assis-tive machines hands-free during surgeries, expert systems which assist reasoning through possible diagnosis, and software with virtual doctors who serve as automated assistants, pre-screening patients by having them first describe their symptoms prompting their doctor visit.
This lack of annotated corpora for certain fields is problematic. On one hand it renders it nearly impossible to create sophisticated natural language applications for those fields. But it also has the effect that any natural language application cannot achieve a certain level of general intelligence due to gaps in knowledge related to those unrepresented fields.
Therefore it is incredibly important, if we ever wish to have applications that are even more surface-level intelligent, to have datasets across a very wide range of fields. And to do that we need to figure out how to create them much more cheaply and easily.
This thesis focuses on not only increasing the number of annotated datasets for under-represented areas, but in demonstrating a model for doing so in an automated and nearly free manner.
Chapter 2
Background
2.1 Data Quality
Snow et al., in their influential and oft-cited study "Cheap and Fast - But is it Good?:
Evaluating Non-Expert Annotations for Natural Language Tasks" [49], address the issue of
data quality in crowdsourced annotations. They employ Amazon Mechanical Turk workers, also know as Turkers, to perform five natural language annotation tasks: affect recognition, word similarity, recognizing textual entailment, event temporal ordering, and word sense disambiguation [2]. Their results for all five tasks demonstrate high agreement between the Turkers non-expert nnotations and gold-standard labels provided by expert annotators. Specifically for the task of affect recognition, they demonstrate on par effectiveness be-tween using non-expert and expert annotations. Snow et al. conclude that many natural language annotation tasks can be crowdsourced for a fraction of the price of hiring expert annotators, without having to sacrifice data quality.
In addition to establishing the viability of non-expert crowdsourced annotators, Snow et al. address further improving annotation quality by evaluating individual annotator re-liability and propose a technique for bias correction. Their technique involves comparing Turker performance against gold standard examples. The Turkers are then evaluated using a voting system: When more than 50% accurate the Turkers receive positive votes, when the Turkers judgements are pure noise they receive zero votes, and Turkers whose responses are anticorrelated to the gold standard receive negative votes.
In addition to this more in-depth approach, they note that two alternate methods of con-trolling for annotator reliability are simply using more workers on each task or using Ama-zon Mechanical Turk's payment system to reward high-performing workers and demote low-performing ones. Crowdsourced natural language annotation systems with a human-based computation games approach preclude controlling for quality through a reward sys-tem. The implications for this are that quality will be controlled through a combination of annotator bias modelling and annotator quantity.
Finally, Snow et al. address training systems without a gold-standard annotation and report the surprising result that for five of the seven tasks, the average system trained with a set of non-expert annotations outperforms one trained by a single expert annotator. Nowak et al. corroborate this finding in "How Reliable are Annotations via Crowdsourcing: A
study about inter-annotator agreement for multi-label image annotation," and summarize
that "the majority vote applied to generate one annotation set out of several opinions, is able to filter noisy judgments of non-experts to some extent. The resulting annotation set is of comparable quality to the annotations of experts" [41].
Further work on annotation quality provides additional methods for screening data. Ipeirotis et al. argue that although many rely on data quantity and redundancy (one of the three data quality methods proposed by Snow et al.) for quality control, redundancy is not a panacea. They present techniques enabling the separation of a worker's bias and error and generate a scalar score of each worker's quality [31].
A collaboration between researchers at CrowdFlower, a crowdsourcing service like
Amazon Mechanical Turk, and eBay examined worker data quality beyond a single in-stance in an effort to ensure continued high data quality [33]. They concluded that the best approach consisted of an initial training period followed by sporadic tests, where workers are trained against an existing gold standard. More precisely, they demonstrate that the subsequent training tasks should follow a uniform distribution. Le et al. make the analogy of training a classifier to training human workers. They point out that both need a training set but that distributions of that training set differ in either case. A training set for a machine classifier uses a randomly selected training set which should approximate the underlying distribution. Using the same distribution for humans biases them towards the labels with
the highest prior. Therefore, training questions should predispose no bias and be uniform. From these studies on non-expert annotation have demonstrated the viability of using non-expert annotators to produce near-gold standard annotations and provided an array of methods, from bias correction to filtering, for further refining the quality of the annotations.
2.2
Games With a Purpose
Establishing the viability of using non-expert annotators to create quality annotated corpora is an important step to reducing the barriers to creating such datasets. Crowdsourcing ser-vices like Amazon Mechanical Turk and CrowdFlower make it easy to almost instantly find any number of workers to complete tasks. However, these services cost money. The cost is nominal, often hovering around minimum wage, yet is still an impediment to corpora-building efforts, especially when scaled to large-scale endeavors. It would therefore be desirable to find an alternative approach to hiring annotators.
"Games with a Purpose (GWAP)," also known as human-based computation games,
attempt to outsource computational tasks to humans in an inherently entertaining way. The tasks are generally easy for humans to do but difficult or impossible for computers to do. Examples include tasks which rely on human experience, ability or common sense [48, 63, 64]
Luis von Ahn, a Computer Science professor at Carnegie Mellon University created the paradigm. The first GWAP developed was The ESP Game, which achieved the task of la-beling images for content. The game enticed players to contribute labels by its entertaining nature; two randomly-paired online players attempt to label the image with the same words and get points only for their matches. The game is timed and provides a competitive factor, while simultaneously encouraging creativity in brainstorming appropriate labels.
A more recent and complex example of a GWAP, also by von Ahn, is the website
Duolingo [23, 40, 47, 61]. Duolingo provides a free platform for language learning, an
inherently desirable activity for many people, while achieving text translation. Users trans-late article excerpts as language learning practice. Translations are corroborated across many users, and translated excerpts are combined into fully translated articles.
Essentially, GWAPs are appropriate in circumstances where it would be desirable to outsource a computational task to humans and where it would be possible to do this in a way that would be satisfy a human need for a service or game. A web-based tool for scientific article annotation would fall under this category; It would gather annotations to compile in a dataset valuable for training future natural language applications while providing annotators with a service to conveniently annotate their research articles and share those annotations with collaborators. Importantly, such an annotation tool would create annotated corpora without requiring continuous funding for annotators. The upfront cost of building an annotation platform and the framework for collecting and refining the gathered data is an increasingly worthwhile investment the more the tool is used and the larger and more refined the annotated corpora grows [14, 38, 50].
2.3
ConceptNet
In addition to Games with a Purpose, another method for crowdsourcing the creation of knowledge bases is by simply asking for them from online volunteers. Open Mind Common
Sense (OMCS) is a project from the MIT Media Lab that recruits common sense facts about
the everyday world from humans, such as "A coat is used to keep warm" or "Being stuck in traffic causes a person to be angry." OMCS provides a fill-in-the-blank structure which pairs two blanks with a connecting relationship. OMCS provides relations such as "is-a,"
"made-of," "motivatedcby-goal" and many more. As an example, a volunteer could input
"A saxophone is used-for jazz" by selecting the "usedfor" relationship from a drop-down
menu and filling in the paired elements in the blanks [51].
A follow-up project by Catherine Havasi and other MIT researchers who were involved
with OMCS built a semantic network called ConceptNet [29] based on the information in the OMCS database. ConceptNet parses the natural-language assertions from OMCS, and creates a directed graph of knowledge with concepts as nodes and the relations as edges.
ConceptNet has developed to incorporate further resources such as WordNet, Wik-tionary, Wikipedia through DBPedia, ReVerb and more, all of which require personalized
parsing and integration into the ConceptNet semantic network. This structured information can be used to train machine learning algorithms.
Open Mind Common Sense is similar to an online annotation tool like AnnoTool in that they are both crowdsourced knowledge-acquisition platforms and different in that OMCS relies on volunteers rather than a GWAP approach. Like OMCS, AnnoTool's annotated corpora could be another data source which ConceptNet includes in its collection of
re-sources.
In conclusion, AnnoTool relies on gathering annotated corpora through non-expert an-notators, which previous research has shown to produce high quality annotations [41, 42, 43, 44]. Specifically, its annotator base is drawn not from paid crowdsourcing services like Amazon Mechanical Turk, but from users who are already inherently motivated to engage because the system offers them an avenue for their annotation and collaboration tasks. This aligns with a Games with A Purpose approach and allows the system to grow unlimited
by financial resources. Finally, similar knowledge bases, like that gathered by the Open
Mind Common Sense project, show a concrete example of how the results can be useful for contributing to systems which train machine learning algorithms.
Chapter 3
Technology
3.1
Backend
AnnoTool was built with the web framework Django [20, 21], version 1.5.4, and a Post-greSQL database, version 9.2. Django is an open source web framework that follows the model-view-controller archicecture. It is run in conjunction with an Apache server, version 2.4.6. The model designed includes three classes: Article, User and Annotation [18]. An-notations have a many-to-one relationship with a User meaning that each AnnoTool user has multiple annotations associated with their username. Similarly, Annotations are associ-ated with a specific Article. If in the future AnnoTool were extended to support annotations across documents, an Annotation object have a list of the Articles to which the instance re-ferred. After configuring Django to connect to the PostgreSQL database, a simple syncdb command updates the database to reflect the models.
Users interact with AnnoTool as a Google Chrome extension [26, 27]. Google defines Chrome extensions as "Small programs that add new features to your browser and person-alize your browsing experience."
Chrome extensions are built to provide extra functionality to Google's browser, Chrome, and can take the form of programs that run in the background, without the user's interaction beyond installing them, to new toolbfars or menus that appear when the user visits certain pages or clicks on an icon to open the tool.
AnnoTool in its current form is built so that it opens on three specific PLOS article pages for testing purposes, but in its final form will allowed to appear on any PLOS ONE article pages.
Upon saving an annotation, the Chrome extension makes an HTTP POST request to Django to write the annotation to the PostgreSQL database [19].
3.2 User Interface
After the user installs AnnoTool and navigates to an article on the Public Library of Science website, a toolbox appears in the upper right corner of the page. The toolbox appears on the page of any PLOS article and automatically disappears upon leaving a PLOS article page.
In order to use the tool, the user must log in with their username and password on the Options page, accessible through the Chrome extensions list at the url chrome: // extensions. In the test version, AnnoTool usernames and passwords are assigned rather than created by the users themselves. It is not possible to create a username/password pair without Django administrator privileges [56]. In the production version of the tool users will be able to create their own accounts and will only need to sign in once after installation. Once a new user successfully saves their login credentials in the Options page, they can return to the article and begin annotating. A user may have one of many differing annotation approaches. One user may wish to annotate the article in multiple passes, highlighting with one tag per pass. In the backend, all tags are represented as belonging to the same radio button set. The implications of this are that only one tag can be selected at a time and a tag remains selected until a different tag is chosen. What this means for "multiple pass" users is that they do not need to redundantly select the same tag for each new annotation. In the most streamlined scenario, they do not need to select an distinct more than once per article. One suggestion given during user feedback was to add a functionality whereby the user did not need to save after every tag. This is certainly a feature to be added in the production version of AnnoTool, further reducing the user's keystrokes to only the most necessary.
The presentation of the tags are separated into their respective groups (Figure 3.1). The terms within groups are listed by their acronyms, while the full text is given over mouse-over. The color of the tags' highlight is the radio button's border color. When a word or phrase is highlighted on the page, this is the color that will be used for the highlight. If a user wished to group tags differently, rename tags, change the highlighter color or add and delete tags or groups, they would navigate to the Options page to see an editable list of current groups and tags. The user's configuration is saved, so the user is able to truly personalize the tool to their annotation needs. Future versions would allow for downloading and uploading configurations. This would facilitate backup and sharing configurations.
Beneath the two tag groups is an input box for the highlighted text. The box itself is uneditable by hand. The way a user submits the desired highlighted text into the box is through a key shortcut: On a Windows operating system, the user holds down the Control key, while clicking and dragging over text with the mouse. They keep the Control key depressed until after they lift up on the mouse click. This transfers the highlighted text to the highlighted text input box. A Mac user would perform the same steps with one slight alteration- they would first highlight a phrase with their mouse, then while keeping the mouse depressed would select the Control key. Finally, the user would release the mouse key first before releasing Control, the same as on a Windows computer.
Underneath the input text is a larger text area for writing annotation notes. Although selecting a highlighted text string and a tag are both mandatory to save an annotation (and their absence on a save attempt will trigger an error alert), any additional notes are entirely optional.
In addition the toolbox the user interacts with when annotating articles, AnnoTool con-sists of an Options page where the user can add, delete, reorder and regroup tags, as well as specify a different highlighter color (Figure 3.3). In the current testing iteration, upon load a user is provided the current default tagset, consisting of two groups of tags, to be described thoroughly in the "Testing Setup" section.
Non invasive brain to-Broin Interface (BBI): Establishing Functional
Links between Two Brains
5so-g-Sk YWU hyugM Kim. Em-4 u F d , Sye JWW TaOWg .ss Uk P.
TE " F "1 1"" H M E M-88SE8 HidFi Abstract
Transcranial focused ultrasound (FUS) is capable of modulating
the neural activity of specific brain regions, with a potential role as
a non-invasive computer-to-brain interface (CBI). In conjunction
with the use of brain-to-computer interface (BC) techniques that
translate brain function to genierate computer comitands, we
investigated the feasibility ofusing the FUS-based CBI to
non-invasively establish a functional link between the brains of
different species (i.e. human and Sprague-Dawley rat), thus
creating a brain-to-brain interface (BBI). The implementation was
aimed to non-invasively translate the human volunteer's intention
to stimulate a rat's brain motorarea that is responsible for the tail
between regions. One was more frequent among SW Altaian
Kazakhs (haplotype #3). while the other appeared at low
14. frequencies in both locations (haplotype #1). Both of these
P.ft haplotypes belonged to haplogroup C3*. No other hapiatypes were
D-- shared when considering the full 17-STR profile.
r
is n .es asu ie r(seramm rGB bijatie * - -1e Media Coverage of This Article Posted by PLoSONEGroup rat's ass Posted by -. 0,1111MU 8TER sE M. E..aM,8 83FFgurr 2. Reduni uediaa-mediafJolfagaetwgrk of
Altalan Kaank ving 144[T aloyp.
do Ar1tq"Nasint.4WlOns
We also reduced the 17-STR profile to a 5-STR profile (DYS3891.
DYS390. DYS391, DYS392 and DYS393) to compare the Altaian
Kazakh data with published data sets (Figure 3). As a result of this reduction, the 51 Altaian Kazakh haplotypes were collapsed into 21 haplotypes, and the number of shared haplotypes increased
accordingly for haplogroups C3*. C3c and 03a3c*. Even so. RS
Figure 3.2: (A) AnnoTool sits at the top right corner of the web page. (B) As the user scrolls through the article, the toolbox alongside the article.
rum.rc. re e
A 'ai"" "
Figure 3.3: AnnoTool Chrome extension options screen, where groups can be created and highlighter colors set.
Chapter 4
Study
4.1
Testers
Study participants consisted of volunteers recruited through an email requesting testers and hired through Amazon Mechanical Turk. Amazon Mechanical Turk workers are referred to as Turkers in the Amazon Mechanical Turk documentation, on the official website and colloquially among the community. Of the eighteen total participants; eight of the partici-pants were volunteers and ten were Turkers. One of the Turker's results were not excluded after he made only one tag total.
Mechanical Turk requesters locate Turkers by posting a Human Intelligence Task (HIT) which describes what the task entails, the estimated time to completion and the compensa-tion pending a successfully completed task [3, 4].
The HIT for this study described an HIT testing a Google Chrome extension by anno-tating three selected science articles from the Public Library of Science. The Turkers would be required to spend 20 -30 minutes annotating each of the three articles. The overall
esti-mated time for the HIT was 1.5 hours. Compensation was offered at $15, amounting to a
$10 per hour wage. This hourly wage is higher than the average Mechanical Turk HIT, both
because of the complexity of the task and in light of discussions around ethical treatment of Turkers, highlighted for the computational linguistics community in particular by Fort et al. in their paper "Amazon Mechanical Turk: Gold Mine or Coal Mine" [ 1 ].
4.2
Setup
Testers were presented with a consent form approved through the Committee on the Use of
Humans as Experimental Subjects (COUHES). Upon agreement to participate in the study,
testers were redirected to an instructions page.
The instructions began with a brief explanation of the background of the study, namely that AnnoTool is an avenue for creating crowd-sourced annotated corpora using PLOS articles. This was followed by a high-level overview directing users to an approximately 3-minute video uploaded to YouTube demonstrating how to install AnnoTool in Chrome, common errors in setup, usage of the tool, and a brief overview of the articles to annotate and the collections of tags to use when annotating each article.
Testers were recruited through MIT students and contacts as well as Mechanical Turk workers. Once testers agreed to participate, I created a username and password for them through Django command line tools, which they entered in AnnoTool's Options page to sign in. Only once signed in were testers able to save highlights to the database and have the highlights appear on their article. Other built-in checks against data corruption ensured that the tester was required to highlight a term before saving (meaning no annotation notes were unaccompanied by a highlighted term or phrase) and that the highlighted text must have selected a tag by which to classify it.
Three articles were chosen for testing purposes:
1. "Inflated Applicants: Attribution Errors in Performance Evaluation by
Professionals" [54]
2. "Y-Chromosome Variation in Altaian Kazakhs Reveals a Common Paternal Gene
Pool for Kazakhs and the Influence of Mongolian Expansions" [22]
3. "Non-Invasive Brain-to-Brain Interface (BBI): Establishing Functional Links
between Two Brains." [7 1]
The articles were chosen by virtue of a number of factors: belonging to the "Most Viewed" category and so more likely to appeal on average to the testers, containing a wide variety of taggable words and phrases and for covering a span of separate fields.
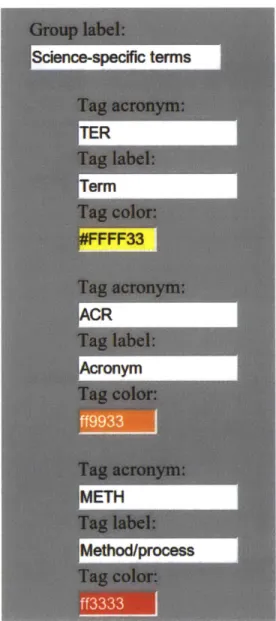
Testers were instructed to annotate each article with a different tagset. The first article was to be annotated with the tagset "Science-specific", the second with "Linguistic Data Consortium" and the third with a single tag; the "Term (TER)" tag.
4.3
Tags
The Linguistic Data Consortium tag group is based on the extended tag group proposed
by the Linguistic Data Consortium (LDC), "an open consortium of universities, companies
and government research laboratories" that "creates, collects and distributes speech and text databases, lexicons, and other resources for linguistics research and development purposes"
[52].
In Version 6.5 of "Simple Named Entity Guidelines" the LDC proposed a core set of tags including:
" Person (PER) " Organization (ORG) " Location (LOC) " Title/Role (TTL)
Complements to this core tagset include:
" Date (DAT)
* Time (TIM)
" Money (MON) " Percent (CNT)
which are included in the named entity tagset for the Stanford Parser.
The Science-specific tag group is an experimental set of tags created based on fquently identifiable terms and phrases observed in PLOS articles. This tagset can be re-fined based on usage statistics. Tags that are frequently used or that have a high degree of
agreement when used can be retained while less useful are replaced by user-supplied tags. In the first iteration, there are seven tags:
" Term (TER) * Acronym (ACR) * Method (METH) " Hypothesis (HYP) " Theory (THY) * Postulation (POST) * Definition (DEF)
The first tag is "Term." Term is used to identify a word or phrase particular to an article or scientific field. These are frequently easy to spot by appearing multiple times in the article, sometimes in slightly altered forms, or by being followed by an acronym in parentheses.
The "Acronym" tag is fairly self-explanatory and is used in the normal definition of the word. Acronyms are usually introduced in parentheses following the full text for which they stand.
The "Method" tag often references a phrase or even multiple sentences. Occasionally the usage will be obvious, when the paper includes phrasing like "Our method involved..." which specifically introduce the method. A synonym for method, algorithm, also identifies phrases where the Method tag is applicable. Otherwise the method will be described as a series of steps and experiment design, but not explicitly named.
The "Hypothesis" tag can reference both the experimenter's hypothesis and various hypotheses from related or background work. Similar to the Method tag, a phrase may be obvious by explicitly containing the word hypothesis.
The "Theory" tag represents an established hypothesis. Although appropriate instances to use this tag are more rare, they are also easily recognizable as Theory is often part of a capitalized phrase.
A postulation is something that can be assumed as the basis for argument. Therefore,
the "Postulation" tag is meant to identify one or more phrases that precede the experi-menters' assertion or hypothesis. This is an example of a more high-level tag.
Finally, the "Definition" tag is for a phrase where a new term is defined. Note that tags can exist within tags, and it is common to find a Term tag embedded within a Definition tag.
Chapter
5
Results and Conclusion
5.1
Study participants
Volunteers on average annotated far less thoroughly than Turkers. Of the eight volunteers, only four completed all four articles, as opposed to all of the Turkers. Turkers also gave thorough feedback in addition to an explicit request for time to completion estimates for each of the three separate tasks, discussed in the Feedback section below.
5.2
Tag Usage
In terms of usage, the least used tag was "Money (MON)." This is explainable by the con-tent of the articles themselves, as very few discussed money or finance in general. This supports the decision to create new, science-specific terms, as it is evident that the tradi-tional tagset under the "LDC" group heading are less applicable in the context of scientific articles from PLOS.
Following closely in the category of least-used terms are "Date (DAT)", "Title/Role (TTL)", "Percent (CNT)" and finally, "Theory (THY)." The first three all belong to the LDC category as well, quantitatively reinforcing the observation that the traditional tagsets are less applicable in this context, and that a tailored science-specific tagset is more relevant. The "Theory" tag is understandably less used, both because properly tagged phrases for
theory simply occur infrequently and because the term shares overlap with "Hypothesis (HYP)" tag.
On the end of the spectrum for heavily used tags was "Term (TER)," followed by "Pos-tulation (POST)", "Location (LOC)" and "Method (METH)" and "Person (PER)". Terms were ubiquitous in scientific articles, which reflects what linguistics have observed about academic language [ref to Academic Lang paper], that a specialized vocabulary performs an important function of expressing abstract and complex concepts, and is thus crucial and widespread.
Given the objective to present scientific studies and their conclusions so that they are both logically followed and accepted by the reader, explanations of logical axioms (Pos-tulations) and step by step processes (Methods) account for the frequency of POST and METH tags.
Although at first glance it seems curious that "Definition (DEF)" tags did not occur on par with Term's frequency, there is a plausible explanation. A term need only be defined once and is used many more times afterwards. Furthermore, although an article contains many scientific terms, as evidenced by the abundance of Term tags, most are assumed to be a standard part of the repertoire and unnecessary to define.
The term with the highest agreement was "Acronym (ACR)." This is the simplest tag and most easily identifiable through a series of uppercase characters. "Percent (CNT)" was also homogenous; although not all annotators tagged a specific percentage with the CNT tag, the ones who did were nearly unanimous in their identification of the term, without including extraneous surrounding characters.
In contrast, a tag like "Method (METH)" was much less predictable in what was in-cluded. This illustrates a trend that more high-level tags, or tags that might prompt the user to include more words on average also have more variance in the words and characters included. However, there is an identifiable "hot zone" of text that users agree upon in the general area that the tag encompasses, with less agreed upon words on either side of the confirmed term. When creating a gold standard annotated article, the system can take the approach of only including words and character above a certain averaged confidence level.
5.3
Time
Of the self-reported estimates for time spent on each article, the first took on average 40
minutes, the second took on average 20 minutes and the third, 15 minutes.
Most users found 30 minutes to be far too little time to finish tagging the first article with the Science-specific tagset, and so did not finish that article. However, four of the Mechanical Turk workers spent between 45 minutes and an hour and ten minutes on the first article before moving on.
The second two were consistently between 10 and 30 minutes, however, it is difficult to tell if that is because they second two tasks were simpler or if the testers were more experienced and faster after the first article.
From tester feedback, participants expressed that they felt more savvy even as soon as the second article but attributed most of the time spent on the first article to it being a more difficult task than the second two:
"The first one was the longest and most difficult. I spent about an hour on the first one before I decided to let it rest and move on to the second one."
Another participant elaborated that the complexity of the tags used with the first article is what made it the most difficult: "In retrospect I should have emailed for clarification on the science-specific tags. I'm kind of neurotic with things like this, so even with your description and examples for tags, a few of them (e.g., assertion, term) looked like they could be loosely applied ... all over the place. I did a few passes and moved on to the other articles." He later returned to the first article again and found that the second pass through caused "Way less stress."
In general, the consensus was that the first article task was most challenging: "...it confused me. The second one was much easier."
The second and third were seen as the easiest: "Those were significantly easier to work through."
In combination with the data on tag usage, it is reasonable to conclude that the first task was more involved than the other two. Comparing the first and third task, we have the first task requiring use of the complete first tagset group, while the third task requires the
user to use only one tag from the group. This makes the third task much simpler than the first. Similarly, the second task also uses an entire tagset, so the third task is less complex compared to the second task also.
Comparing the first and second task, we have tasks with two different tagsets of approx-imately the same number of tags (the first with seven, the second with eight). However, the second task used less of the tags in its group, as we saw when analyzing tag usage. Also, user feedback pointed to particular tags in the first task as causing difficulty: "I'm not gonna lie, methods and results were a bugger; entire sections seemed to apply." For the purposes of the study, it is clear that a tag like Method was an unnecessarily complicated addition. However it stands to reason that Method is still a valuable tag for AnnoTool for regular users. Unlike study participants, they will not be instructed to tag any instance of methods in the text, only ones that interest them or serve their particular research purposes. This will serve the individual user while the system can still collect the full range of identifiable method phrases through the combination of many users' highlights.
5.4
Feedback
In addition to feedback regarding article annotation time and difficulty level, participants volunteered feedback related to the tool's user interface, the ease of use and how interesting or enjoyable the task was in general.
Regarding the user interface, one tester went into detail and suggested an improvement: "Overall the add-on itself is very well designed but could benefit from things like having the definitions for annotations easily accessible on the page you are annotating. It's a functional extension that gets the ball rolling though and I didn't have any problems with it."
Another user offered a similar complaint regarding the lack of easily accessible defini-tions, forcing one to learn them all by memory. Referring to the first two articles, which were assigned tagsets with multiple tags: "Both Articles had many annotations to tag, the length of the articles and numbers of tags to keep memory of while going through tagging was very hard to keep up with." More explicitly: "Having 8 tags to keep memory of while
going through is extremely overwhelming for most people, unless the person has a second monitor to keep track of these things, and even then it would still be difficult."
The same user suggested an improvement to the study design, minimizing the number of tags: "I think keeping it to one tag is best. Assign different people different tags and you'd most likely get more accurate results quicker. If you wanted an even bigger sample, cut the article into smaller parts with maybe 1-3 tags and then assign them, making sure some of these assignments overlap so you get more accuracy because more people are doing it. I don't believe having people annotate giant research articles like shown with multiple tags to keep in your head is feasible. I think cutting it up into as small as you can and still get enough overlap to be accurate is best."
It's worth noting that the intuition behind this tip aligns with studies that emphasis redundancy as a data quality measure, as explained earlier in the Background section.
Other problems included the highlights disappearing upon refreshing the page, the lack of editing capabilities for already-saved annotations, and requiring saving after each new annotation: "The challenges: Not knowing what had already been annotated and trying to remember after having been signed out and signing back in and, of course, refreshing." "And, finally, the last challenge: not being able to un-annotate, meaning remove all or part of a selection." "Being able to redo tags or save periodically instead of every tag would be my one quality of life suggestion from the worker's POV."
There were two other surprisingly ubiquitous hitches. AnnoTool was designed with a keyboard shortcut to highlight text. Instead of requiring a user to first highlight text and then click a button to select this as the highlighted text each time they wished to create an annotation, a user would simply have to hold down Control while highlighting. Although this was demonstrated in the video and written in the instructions, many users had difficulty with this initially. Similarly, although users were instructed how to save the packaged Chrome extension tool for installation using a right-click and "Save as" procedure, many expressed initial difficulty with the installation process. "So I've tried every possible way to load the AnnoTool but Chrome will not let me load it. All I get is a paper, not an actual full file. I understand that it must be dragged to the extentions to be accepted by Chrome but Chrome refuses to even allow the download." "First technical problem: Chrome not
allowing the extension. It took me a while (grrrrrrrr!), but I figured out a work-around,
however others may not know how to do that." "I cannot download the annotool, it wont install the extension in chrome, any tips?"
However, both of these issues are easily solved. AnnoTool is currently hosted on a private server rather than the Chrome store while it is in a testing phase. After it is down-loadable through the Chrome store users will not have to deal with installation more com-plicated than selecting the program through the Chrome store. For highlighting, the user interface can add a button to select highlighted phrases for users who wish to avoid using keyboard shortcuts, or add an interactive tutorial that demonstrates usage.
One interesting observation is how many study participants continued annotating the
first article past the recommended 20 - 30 minute range, even though the instructions
ex-pressed it was acceptable to leave an article before finishing it and to do so in order to budget time for the others. Many comments reflected this: "Article 1 I spent over an hour on and I'm not even close to being done with it." "Alright. Well, I've been at this for two hours now. None of them are completely done. I think maybe I was being too much of a perfectionist with them." "I've been working on the first article for an hour and ten min-utes." "Sorry I went over. That's a lot to read." "I don't know how other people did it, or are doing it, but I read every single word. I realized by the third article that maybe it wasn't really necessary to do that... .but I'm also a bit of a perfectionist so what I struggled with may not be what others struggle with."
Of the annotators who did move on after 30 minutes, many felt the need to explain that
they did so, regardless of the fact that the instructions stressed there was no expectation to finish an article and no penalty:
"For a full job on these I believe it would take much longer than 20m." "...the assign-ments will need to be smaller or the time allotted/suggested will need to be higher." "Hey
the first article took me 45 minutes.I read almost everything and did my best." "It took
me 45 minutes to do the first one, I stopped half way through because it confused me." "I
finished the annotations to the best of my ability."
In the feedback regarding article completion, two Turkers explicitly mentioned being perfectionist and another explained a similar response to annotating; "I'm kind of neurotic
with things like this." It would be interesting to further study the psychological traits of annotators, especially in regards to how it correlates with annotation quality and quantity. There are too many factors to tease out in this particular study, but a few noteworthy points: Many annotators did not, perhaps could not, easily move on from an article that was un-finished. Turkers select their HITs, so this was a self-selected group. Furthermore, there was a qualification test, albeit a very simple and short one, that Turkers had to take before selecting this HIT, requiring a minor time investment on their part. Finally, apart from the apparent stress caused by self-proclaimed perfectionism, participants seemed to enjoy the task and experienced pride when gaining experience and confidence: "...you could read over the articles once or twice and feel pretty confident that most of the stuff you tagged was correct. I walked away from this I had done a better job than the last two in less time." "Thanks for the opportunity to do this HIT, I enjoyed the concept of it..." "Interesting tool to use..." "Once again thanks for letting me do the work, was some interesting reading."
5.5
Inter-Annotator Agreement
There were a number of factors that worked against annotator agreement. The testers were not professional annotators and were completely inexperienced with the system and the tagset. They were introduced to the system, given a short written overview of the tags with example usage, and asked to do their best, without the option to ask questions to confirm their interpretations or request feedback. They were not professional researchers who reg-ularly read academic papers. They were given three scientific journal articles to read and annotate, but not enough time to complete the articles. The instructions acknowledged that the time allotted per article was most likely not sufficient and to simply proceed to the next article after 30 minutes. However, many testers professed in their feedback that they had personalities which did not function well with leaving a task unfinished, and that this style of experiment caused them stress, potentially leading to lesser results.
Two of the tasks involved multiple tags per article. Annotators may have had different styles which contributed to different tagging results. One approach would be to make a pass through the article once for each tag. In this case, if the annotator was short on time,
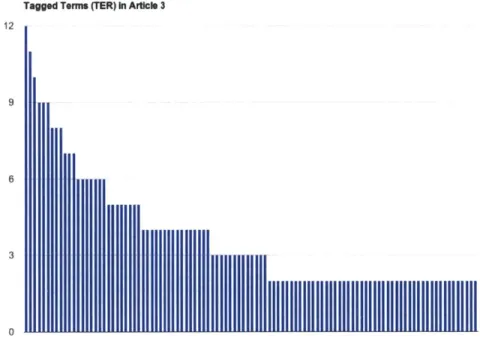
some tags might not even be used. Another approach is to go through the article once, using tags when they appeared. If short on time, this approach might have a more even distribution of tag usage, but have no highlighted phrases after a certain point in the article. The insufficient time allotment meant that agreement between varying approaches suffered. Despite these many factors, there was still noticeable agreement between annotations. Let us look at the third article assigned, "Non-Invasive Brain-to-Brain Interface (BBI):
Establishing Functional Links between Two Brains" [71]. The task for this article was to
use a single tag called "Term" for any words or phrases which could be paper or field-specific lingo.
To study the results of inter-annotator agreement, all highlighted terms were collected and paired with a count of how many annotators had tagged them. As annotators were instructed to tag a given term only once in an article, multiple highlights of the same term in an article did not count more than once.
Looking at the table of counts of agreed-upon terms gives a sense of the high data quality; All of the highlighted phrases are reasonable instances of the term (TER) tag.
A standard technique of calculating inter-annotator agreement is to use confusion
ma-trices. Those familiar with natural language annotation might wonder why this analysis approach was not used here. Confusion matrices have different, traditional assumptions, namely that the annotators intend to annotate thoroughly and highlight each instance of a tag. If a phrase is not highlighted, it implies that the annotator did not think it fit into a tag category. In contrast, here the assumption is that an annotator will not highlight every instance of a tag. Doing so would be redundant and provide them no extra value. Not highlighting a phrase does not imply anything. The same phrase may be highlighted else-where in the article. Or in real-world usage, users simply will not necessarily spend time highlighting what they already know, even if a certain tag is applicable.
For example, consider an article that contains the acronyms "BCI" and "fMRI". When using AnnoTool for my own research, I might tag fMRI because I have never heard the term before or because I am specifically annotating for procedures and technologies I could use in my own experiments. I refrain from tagging BCI, not because I do not think it is an acronym, but because I am already familiar with the term or because it is not appropriate
Terms (TER) Number
Transcranial focused ultrasound 12 computer-to-brain interface 11
brain-to-computer interface 10
Deep brain stimulation, Magneto-encephalography, Transcranial magnetic stimulation 9
brain-to-brain interface, functional magnetic resonance imaging, functional transcranial
doppler sonography 8
electroencephalogram, motor cortex, near infrared spectroscopy 7
epicortical stimulation, false negatives, false positives, multi-channel EEG acquisition,
Neural Coupling, pulse repetition frequency, steady-state-visual-evoked-potentials 6
Brain-to-brain coupling, optically-tracked image-guidance system, parameter optimization, single-montage surface electrodes, sonication, tone burst duration, true negatives, true
positives 5
accuracy index, baseline condition, caudal appendage, event-related desynchronization, ex vivo, F1-score, focused ultrasound, FUS-based CBI, implantable cortical microelectrode
arrays, neuromodulation, spatial-peak pulse-average intensity, spatial-peak temporal-average intensity, standard deviation, stereotactic guidance, temporal
hemodynamic patterns, Transcranial sonication of focused ultrasound 4 brain-machine-brain interface, data acquisition hardware, electroencephalographic
steady-state-visual-evoked-potentials, in situ, intracortical, intraperitoneal injection, mechanical index, navigation algorithms, peripheral nervous system, Sprague-Dawley rat,
steady-state visual evoked potential, stored-program architecture devices, ultrasound 3
acoustic energy, acoustic intensity, air-backed, spherical-segment, piezoelectric ultrasound transducer, astroglial systems, cavitation threshold, chemically-induced epilepsy, complex
motor intentions, computer-mediated interfacing, cortical electrode array, cortical microelectrode arrays, detection accuracy, detection threshold, EEG-based BCI, electro-magnetic stimulation, electroencephalographic, external visual stimuli, extracellular neurotransmitters, function generators, functional imaging, FUS, implanted cortical electrode
array, in vitro, intracortical microstimulation, linear power amplifier, Matlab codes, motor
cortex neural activity, neural activity, neural electrical signals, neuromodulatory, non-invasive computer-to-brain interface, piezoelectric ultrasound transducer, pressure amplitude,
sensory pathways, signal amplitude, signal fluctuations, slow calcium signaling, somatomotor, somatomotor areas, sonicated tissue, sonication parameters, spatial activation patterns, spatial environments, spatial patterns, Sprague-Dawley, square pulse,
stereotactic, ultrasound frequency, visual stimulation 2
Figure 5.1: The Terms from the third article with inter-annotator agreement, grouped by number of annotators who identified the term. The collection of highlighted phrases identified with the Term tag reveals a high quality collection.
Tagged Terms (TER) In Article 3
12
9
6
Tems
Figure 5.2: The distribution of agreed-upon Terms in the third article.
a 12 0
in the context of my specialized tagging task.
5.6
Conclusion
This study has shown the viability of using untrained, non-expert annotators to create anno-tated corpora using scientific texts. Researchers in crowdsourced natural language annota-tion studies demonstrated that non-expert annotators can produce high quality annotaannota-tions using non-technical text but this study showed that it is possible using highly technical text from scientific journal articles. The study design ensured a highly conservative as-sessment of inter-annotator agreement yet produced excellent quality results. It stands to reason that data quality will improve further with future versions of AnnoTool as a result of improvements to the user interface and removal of the study constraints that worked against annotator agreement. Additionally, acquiring an annotator base with experience using AnnoTool will remove practical obstacles to annotating faster and more thoroughly.
Chapter 6
Future Work
The study succeeded in showing that it was possible to use untrained annotators to annotate technical scientific articles. It is reasonable to assume that the self-selected group of users outside of the study scenario (those users likely to read and annotate scientific articles) would produce annotations at least as good or better.
It is also likely that improvements to the user interface would support better annotations. Explicit feedback from the users revealed the most important and necessary user interface improvements. Users need to be able to edit and delete annotations they made by accident or would like to alter. Users would appreciate a list of the annotations recently made, especially if those were able to be filtered by tag. In its current iterations annotations are cleared from the page (although not from the database) when the page is refreshed. Future versions of AnnoTool would reload all previous annotations and highlight the page accordingly.
What will be interesting to see next is if the tool gains a user base after being released in the Chrome store. Although there are many options for simple annotation tools, the out-spoken community around one tool in particular, Mendeley, reveals the strong desire for an open source annotation application specifically built for a scientific community. Mendeley is a program for organizing, annotating and sharing scientific research papers, available in both desktop and web form.
Ironically, its passionate user base was most apparent when vocally boycotting the program after its acquisition by Elsevier, a scientific publishing giant with a reputation