Regularized non-local Total Variation and application in image restoration
Texte intégral
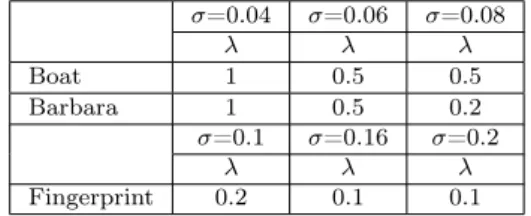
Figure
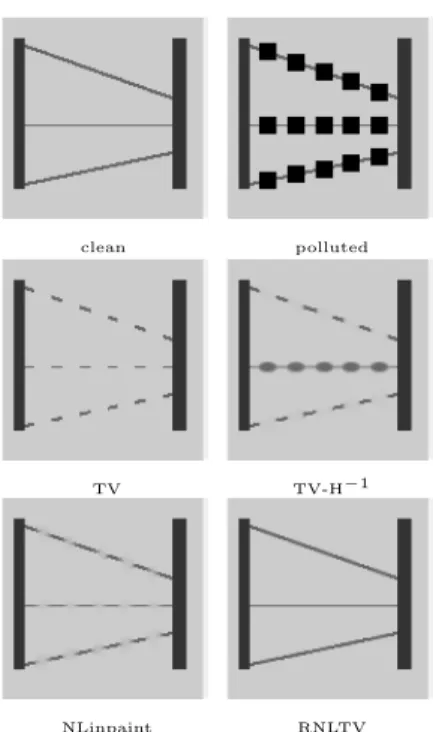
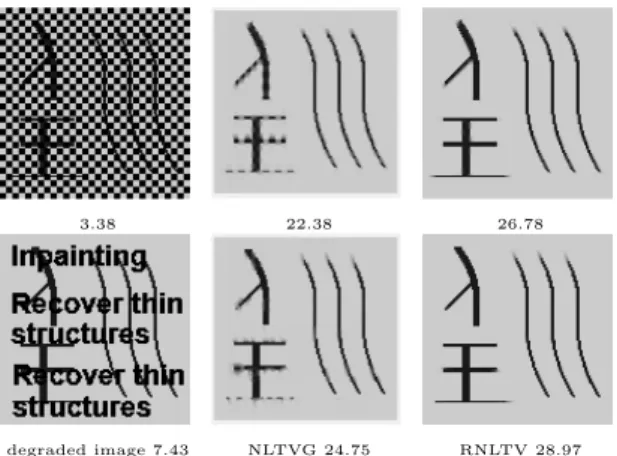


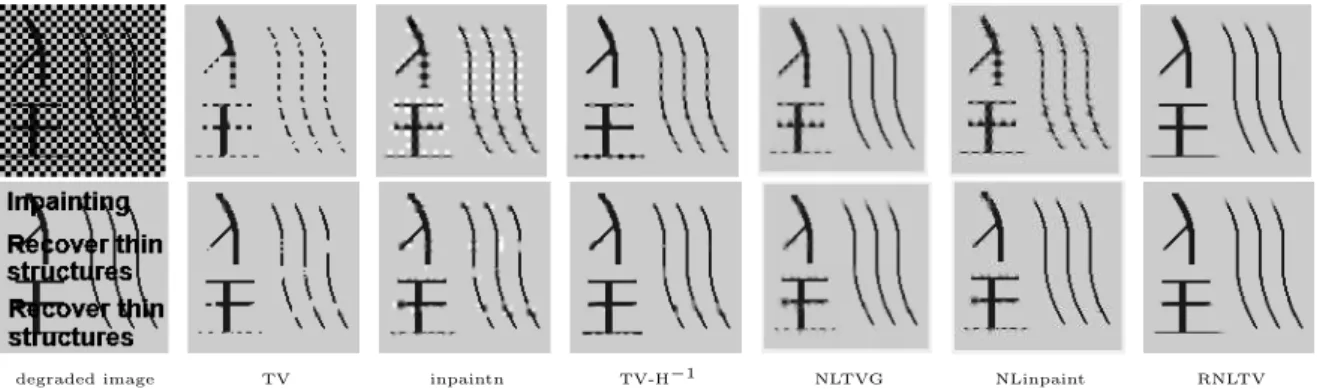



Documents relatifs
In the first part, by combining Bochner’s formula and a smooth maximum principle argument, Kr¨ oger in [15] obtained a comparison theorem for the gradient of the eigenfunctions,
The statistics major index and inversion number, usually defined on ordinary words, have their counterparts in signed words, namely the so- called flag-major index and
The CCITT V.22 standard defines synchronous opera- tion at 600 and 1200 bit/so The Bell 212A standard defines synchronous operation only at 1200 bit/so Operation
blurred cotton image and 4 kinds of algorithm recovery image after contour extraction The results of computing time on cotton images that computing time of four algorithms
In many systems, the observed image can result from the convolution of the true image and the point spread function (PSF) contaminated by noise from various sources. The goal of
As a final comment, we emphasize that simplicial LS-category is a new strong homotopy invariant, defined in purely combinatorial terms, that generalizes to arbitrary
the one developed in [2, 3, 1] uses R -filtrations to interpret the arithmetic volume function as the integral of certain level function on the geometric Okounkov body of the
The work presented here addresses an easier problem: it proposes an algorithm that computes a binary function that is supposed to capture re- gions in input space where the
