Deep Transformation-Invariant Clustering
Texte intégral
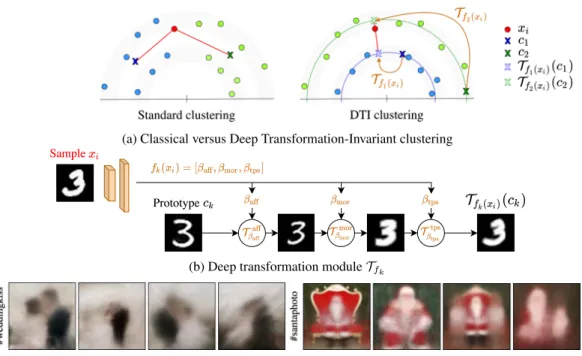
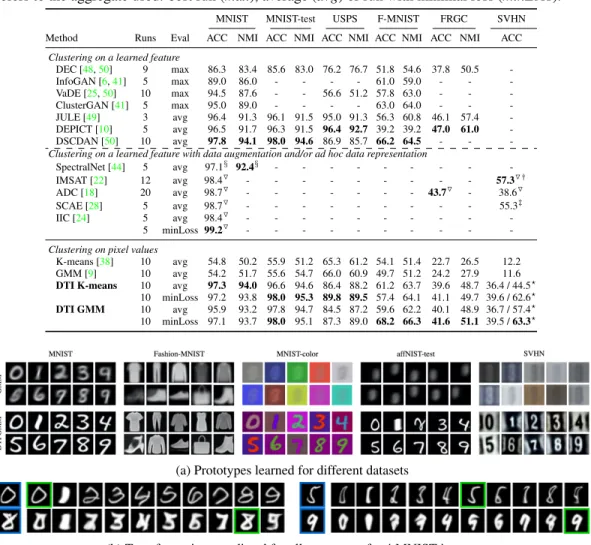
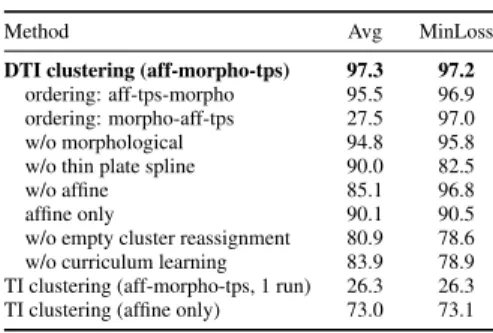
Figure
![Figure 3: Qualitative results on real photographs. (a) Clustering results from photographs of different locations in [35] (1,089 Sacre Coeur top-left, 1,688 Trevi fountain top-right, 2,625 Notre-Dame bottom-left) and 980 Baroque portraits from [26] (botto](https://thumb-eu.123doks.com/thumbv2/123doknet/14466966.521545/10.918.163.757.107.423/qualitative-photographs-clustering-photographs-different-locations-fountain-portraits.webp)
Documents relatifs
Enforcing a clustered structure in the latent space As autoencoders seem to naturally separate similar data in the latent space, we present in this section two methods to
In the present article we will present an augmented phase vocoder based SOLA algorithm that achieves high quality sig- nal transformations for time and pitch scale manipulation for
The frequency domain representation of the signal in the phase vocoder provides multiple advantages compared to the time domain SOLA algorithm: only the sinusoidal components will
To overcome these issues, we combine, in this work, deep reinforcement learning and relational graph convolutional neural networks in order to automatically learn how to improve
Je tiens à remercier Xavier Rodet et toute l’équipe Analyse-synthèse de l’IRCAM pour leur accueil, Axel Roebel pour sa disponibilité et son aide tout au long du stage,
Deep Learning models proposed so far [11] have used external informa- tion to enrich entities, such as synonyms from the ontology, definitions from Wikipedia and context from
We first introduce related works on clustering for time series and constrained clustering, respectively in section 2.1 and 2.2, then we present the deep constrained clustering
This paper investigates the research question: How can a semi-supervised approach learn to categorize short texts in a multi-label taxonomy using a small set of labeled data
