Safe screening for sparse regression with the Kullback-Leibler divergence
Texte intégral
Figure
Documents relatifs
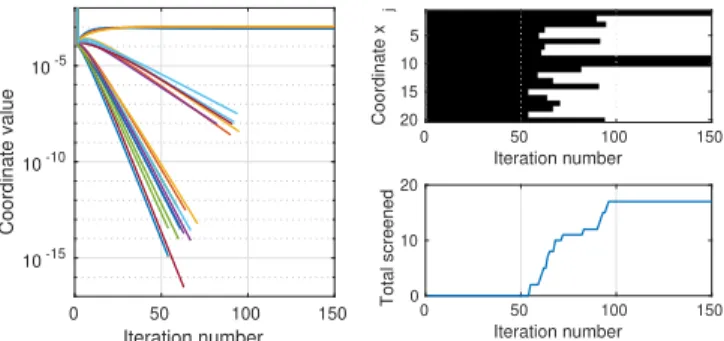
Value of the objective function at each iteration solving Problem (2) varying the number of iterations to solve each ND problem..A. We appreciate that setting the number of
and this during the dextral transpression in the simplon ductile shear zone (Fig. the folding of the schistosity, with the sW-directed stretching lineation, XII, can
Accelerating the solution of the Lasso problem becomes crucial when scaling to very high dimensional data. In this paper, we pro- pose a way to combine two existing
Abstract – Various strategies to accelerate the Lasso optimization have been recently proposed. Among them, screening rules provide a way to safely eliminate inactive variables,
The present observational and retrospective study aimed at evaluating the screening rate of cervical cancer between 2006 and 2011 by age, place of location and for 3-years period
En définitive, les proverbes de Monné, outrages et défis (1990), dans leur portée argumentative et pragmatique, font qu’il est possible de considérer ce texte
[r]
Fourth, it would be helpful, in particular for medical stu- dents and residents, if the authors could rank the relevance of the different topics within a chapter (e.g.,
