Converging for Effective Exploration: How to Learn Across Unique Successes
by
Carolyn J. Fu
M.S. Engineering and Management (2017)
Massachusetts Institute of Technology
M.S. Mechanical Engineering (2010)
Stanford University
B.S. Mechanical Engineering (2009)
University of Pennsylvania
Submitted to the Sloan School of Management
in Partial Fulfillment of the Requirements for the Degree of
Master of Science in Management Research
at the
Massachusetts Institute of Technology
Feborry 2020
© 2020 Massachusetts Institute of Technology. All rights reserved.
____Signature redacted
Signature of AuthorS
g
atred ce
Carolyn J. Fu
Sloan School of Management
17 January 2020
Signature redacted
Certified by
Accepted by MASSACHUSETTS INSTITUTE OFTECHNOLOGY-MAR 112020
LIBRARIES
>Z
z
[
(
Ray Reagans
Alfred P. Sloan Professor of Management
A-A ItThesis
Supervisor
Signature redacted
Catherine Tucker
Sloan Distinguished Professor of Management Science
Professor of Marketing
Chair, MIT Sloan PhD Program
MITLibraries
77 Massachusetts Avenue
Cambridge, MA 02139 httpi/Iibraries-miteduask
DISCLAIMER NOTICE
Due to the condition of the original material, there are unavoidable
flaws in this reproduction. We have made every effort possible to
provide you with the best copy available.
Thank you.
The images contained in this document are of the
This page is intentionally left blank
Converging for Effective Exploration: How to Learn Across Unique Successes by
Carolyn J. Fu
Submitted to the Sloan School of Management
on 17 January 2020 in Partial Fulfillment of the Requirements for the Degree of Master of Science in Management Research
ABSTRACT
Organizations are often advised to engage heavily in exploration in order to succeed - casting a wide net for diverse solutions that are superior to what it currently exploits. However, what is the organization to do when the fruits of its exploration are not commensurate with one another? If all solutions appear beneficial, but each recommends differenth decisions for the same organizational choice, how should an organization learn from them? Unfortunately, such a mixed bag of learning opportunities is likely to be the case on a rugged learning environment, where solutions succeed not because of specific individual choices, but due to the complementarities between these choices. By applying the learning mechanisms in March (1991) onto an NK landscape, this paper is able to show that such a challenge is surprisingly surmountable - with March's algorithm performing almost as well on a rugged landscape as it does on a smooth one. While the rugged learning opportunities may initially stymie the organization, March's inherent process of mutual learning enables explorations to grow progressively similar, so as to converge upon a smooth locality. Onthis smoothed locality, valuable explorations then become salient enough to learn from. The counterintuitive takeaway is thus that in order to capitalize on diverse explorations, an organization must first engage in convergence.
Thesis Supervisor: Ray Reagans
Alfred P. Sloan Professor of Management
1. INTRODUCTION
Our understanding of organizational learning today is strongly rooted in the works of James March - in particular, the tradeoff he established between exploration and exploitation in March (1991). Based on this work, organizations have been encouraged time and again to engage in exploration - the search for "superior activities" (such as businesses processes or technological innovations) that may yield rewards greater than the organization's exploitation of current practices (p. 73). The organizational literature has since offered a multitude of ways to encourage exploration - through strategies such as crowdsourcing (Afuah & Tucci, 2012), alliance formation (Powell, Koput & Smith-Doerr, 1996; Rosenkopf & Almeida,
2003) or organizational structure (Fang et al., 2010; Csaszar, 2013) - as a fundamental means by which organizations can discover more valuable opportunities in the long run.
Central to March's recommendation, however, was the additional stipulation that organizations be able to reintegrate their explorations. Embedded within his stylized model of the organization is a mechanism by which a central "organizational code" is able to combine the bestfeatures of individual members'
explorations into an overarching set of best practices, which can then be disseminated to the rest of the
organization. The organizational code compares successful explorations, searching for commonalities in the choices they have made, and assumes these to be inherently valuable choices that can be added together to obtain the best of all explorations. Only through this 'exploitation of explorations' is the value of explorations then harnessed. Thus despite the typical conceptualization of exploration and exploitation as independent activities to be traded off, exploitation is in fact central to reaping the rewards of
exploration.
Unfortunately, subsequent research points to how non-trivial this task of exploiting explorations can be. Challenges arise when firms attempt to integrate innovations that are technology-oriented versus market-oriented (Khilji et al., 2006), that are premised on "make" versus "buy" (Cassiman & Veugelers, 2006), or that originate from geographically dispersed divisions (Singh, 2008). These studies represent cases in which the fruits of the organization's explorations, while individually valuable, cannot simply be
combined with one another in the manner that March suggests. Rather, these are cases in which individual explorations offer unique forms of value, with recommendations that can contradict one another - a situation commonly arising from the existence of complementarities in value. In such a scenario, explorations may be valuable not because of the specific decisions they entail, but because of valuable complementarities between these decisions, reducing the feasibility of an organization's attempts to decipher any underlying individual decisions that it should make.
Might March's organizational code then fail to seize the value of explorations if they lie on a rugged NK landscape (as adapted in Levinthal, 1997), where value derives from the complementarities between decisions rather than decisions themselves? One can expect that the organizational code would be hard pressed to integrate the value of explorations back into the wider organization, if it can no longer combine the best features of explorations in an additive way. Should the takeaway then be that March's
recommendations for the value of exploration are only valid in cases where explorations occur on a smooth problem landscape? If individuals' explorations are beyond the organization's ability to
comprehend, do these explorations ultimately prove worthless? Especially as organizational environments have become increasingly rugged today, do March's lessons, and thus our fundamental understanding of exploration and exploitation, run the risk of becoming obsolete?
Given this dilemma, I explore in this paper whether March's proposed value of exploration still holds in cases where the integration of exploratory knowledge is problematic - specifically, when explorations lie on a rugged landscape, rather than a smooth one as was assumed in March's original model. I do this by adapting March's original model to use fitness as a performance measure instead, to capture the impact of varying degrees of ruggedness on the overall eventual performance of the organization. Such an exercise is essential as it may expose a significant boundary condition to the recommendations for exploration and exploitation that have thus far been foundational to the field.
Ultimately, I find that March's recommendations for the value of exploration are in fact robust to the challenge of integrating explorations on a rugged landscape, in ways that were not made apparent in his original paper. Regardless of the degree of ruggedness, the organizational code is ultimately able to perform almost as well as on a smooth landscape. As much as the organization may experience great initial difficulty integrating the fruits of its individuals' explorations, the mutual learning that occurs between March's organizational code and its members allows for a process of convergence to ensue, bringing individuals' explorations closer to what the organization is capable of amalgamating in the end. The overall result is that even though the organization is no longer capable of finding the optimal hill on a landscape, it can come surprisingly close. Organizations that attempt to explore a rugged landscape still perform better than an organization that fails to explore at all.
Several important implications open up as a result of this exercise. A key revelation is the counterintuitive benefit of convergence as a means to capitalize on diverse explorations. While divergence may introduce more valuable explorations into the purview of the organization, the same divergence can affect the organization's ability to generalize lessons across them. Convergence is then a means by which explorations can become homogenized, so that what is valuable about them can become salient to the organization. In addition, the results demonstrate a worse-before-better dynamic, where the code must fall to a level that is necessarily low before the process of convergence can ensue. Organizations that are too quick to shun the seemingly poor initial returns from exploration might stop short the essential process of mutual learning, and thereby miss out on important opportunities that materialize down the road.
2. EXPLOITING EXPLORATIONS Revisiting March (1991)
The notion that exploitation is fundamental to (as opposed to coming at the cost of) exploration stems from the different ways in which exploitation is conceptualized in March (1991). In March's instantiation of the organization, two key variables inform the degree of exploration or exploitation taking place - pi,
the rate at which individuals learn from the organization; and P2, the rate at which the organizational code (i.e. central wisdom in the organization, or a central manager) learns from individuals.
The concept of exploration is represented by low values of pi, where "slow learning on the part of individuals maintains diversity longer, thereby providing... exploration" (p. 76). Freed to preserve their own unique forms of knowledge, individuals can develop them into ideas that ultimately prove useful to the whole organization. This is captured in March's original Figure 1 (included here as Figure 1), showing that the greater the individuals' exploration (i.e. the lower the value of pi), the greater the eventual value of average knowledge in the organization.
The notion of exploitation, on the other hand, is conceptualized in two ways in the model. The first is exploitation done by individuals, given by high values pi, which represent individuals who quickly absorb
knowledge disseminated by the organizational code and put it into practice. This high pi leads to a quick improvement in their individual competence; however, as established above, it comes at the cost of the discovery of more valuable long-term knowledge attained at a low pl. This leads to the common takeaway from March (1991) - that while individual exploitation may quickly improve individuals' competence, it trades off with their valuable long-term exploration.
Exploitation is also conceptualized in another way in the model - as that being done by the organizational code. This is given by a high P2, and represents the organization's ability to learn from the particularly valuable explorations that some individuals (whom March termed as "superiors") have discovered. Here, the organizational code attempts to aggregate superiors' explorations with one another, and subsequently determine the decision that the majority of them have made on a given decision. In so doing, the code seeks to learn what valuable underlying decisions might be, so as to potentially derive a set of best practices that can exceed the value of what individual explorations have produced. This set of best practices then becomes a standard that individuals learn from. Consequently, organizational exploitation
serves to both capitalize on and distribute valuable knowledge from superiors to the wider organizational population, raising the "average equilibrium knowledge" across all individuals that is the key outcome measure of the model.
As shown in March's Figure 1, the greatest equilibrium knowledge value is obtained when p, is low and
P2 is high - demonstrating that high individual exploration must be accompanied by high organizational
exploitation. This is hence the subtler message from March - that exploitation is necessary to make
exploration useful. As much as giving greater freedom to individuals would enable them to discover valuable explorations, the benefit of this for the organization as a whole rests on its ability to integrate this value for widespread use.
Developments in Exploration and Exploitation
Since March (1991), further work in the vein of exploration and exploitation has revolved around understanding how this balance shifts, and how to manage it. For example, studies have examined the roles played by organizational structure (Rivkin & Siggelkow, 2003; Siggelkow & Levinthal, 2005), cognitive limitations (Levinthal & March, 1993; Denrell & March, 2001), or incentive structures (Rahmandad, 2012) in causing individuals to focus on exploration or exploitation in turn. Other studies have examined strategies to manage this balance, encouraging firms to develop the ambidexterity to both free individuals to better explore for novel solutions, yet rein them in to exploit those solutions that appear promising. Such strategies include using external sources of exploration to complement the more exploitative work done by individuals in the organization (Laursen & Salter, 2006; Lavie & Rosenkopf,
2006) or managing the degree of individuals' exploration by modifying their network of communication
(Lazer & Friedman, 2007; Fang et al., 2010; Aral & Van Alstyne, 2011). In essence, these studies tackle the aforementioned dichotomy of individual exploration versus individual exploitation - what causes individuals to pursue one over the other, and methods to manage this balance.
In contrast, less attention has been paid to March's stipulated balance of individual exploration with
organizational exploitation - regarding the question of how organizations might make sense of the
various explorations its members have undertaken. Existing studies consider how a firm can manage to recognize the value that individual explorations bring (Koput, 1997; Knudsen & Levinthal, 2007; Csaszar
& Eggers, 2013) or have the necessary internal routines to capture such value internally (Rosenkopf &
Nerkar, 2001; Katila & Ahuja, 2002). However, the specific role that March (1991) proposed that organizations play in integrating and thereby capitalizing on the value brought by multiple valuable explorations has not been further investigated - even as March himself hinted at its potential risks. He
pointed to "the vulnerability of exploration", acknowledging that "what is good for one part of an organization is not always good for another part" (p. 73), recognizing the challenge firms might face in
attempting to integrate explorations on a rugged landscape. Indeed, other studies have echoed the likely difficulties in integrating individual explorations into a greater whole, when interdependence comes into play (Fleming & Sorensen, 2001; Zollo & Winter, 2002), due to the challenge of identifying the
fundamental causes of their value (Barney, 1985) - yet the extent to which this undercuts the value of exploration remains unaddressed.
Ultimately, March accounted for these challenges only to the extent of arguing why organizations might theoretically be less likely to engage in exploration - neglecting the impact that it would foreseeably have on the organization's ability to exploit the explorations of its individuals. By March's own reasoning, if individuals' explorations resulted in a "distribution of consequences across time and space", it should have "[affected] the lessons learned" (p. 73) by the organization. As it is, March's organizational code proves fully adept at integrating all manner of explorations, regardless of their nature.
3. MODEL
This paper thus seeks to incorporate more realistic challenges of integrating explorations on a rugged landscape into March's original model, so as to understand how this might change prevailing takeaways regarding the value of exploration versus exploitation.
Replicating March (1991)
This model preserves the original manner in which the organizational code and individual individuals learn from one another in March (1991). As in March's organization, the knowledge possessed by individuals or the code is represented as a set of binary choices on N dimensions, (X). These dimensions represent various choices that affect the overall performance of an organization, such as whether to use capital financing or not, or whether to expand multi-nationally or not. As individual individuals explore, they randomly toggle their choices on different dimensions, to varying degrees of success. The success of a choice on a given dimension x, depends on its match to an idealized choice in "reality", ml. A matching choice on any given dimension adds to the overall value of the string.
At the same time, the organizational code maintains its own string of choices, representing what it currently believes to be best practices. However, as it discovers individuals whose choice sets perform better than its own (i.e. "superiors"), it attempts to learn from them. It achieves this by comparing superiors on individual dimensions, and searching for commonalities in their choices. As such, if all superiors have chosen 'yes' on one dimension (such as whether to use capital financing), then the code decides that this is a likely common cause of the superiors' success, and adopts it as a best practice with some probability P2. The code thus attempts to learn from superiors' explorations by simply aggregating their actions; comparing them dimension-by-dimension and finding their most common features. The
cycle of mutual learning is completed as the rest of the individuals in the organization seek to learn from this set of best practices the code has identified, copying it with probability pl. Figure 2 demonstrates this
In March's model, decisions by the individuals or the organizational code on a given dimension i, xi, can take on values of -1, 0 or 1; while dimensions of reality, mi, can take on values of -I or 1. The value of the overall string,
O(X)
= 1 xi mi (Christensen & Denrell, working paper). Hence decisions on a givendimension add to the overall value of the string when they match with the respective dimension of reality.
learning in progress over the course of one simulation - where the code (given by the bold red line) steadily climbs to reap the value of its best employees' explorations (given by the blue dots).
One might recognize that such a learning strategy would be valuable on a smooth problem landscape -one in which there is a single correct decision to be made on every dimension, which is independent of the decisions made on others. In March's original model, this is indeed the case - as performance of a set of decisions [X) is given by the sum of the match between the decisions on individual dimensions xi, and the corresponding dimension in reality, mi. A matching choice on any given dimension thus adds to the overall value of the string, such that combining the best features from superiors indeed leads to a valuable amalgamation of decisions - permitting the organization to thereby exploit superiors' explorations.
Accounting for the Ruggedness of Exploration
However, as established above, superiors' explorations are unlikely to be situated on a smooth landscape, potentially stymying the organization's ability to learn from them. In particular, the notion that there is a single best decision to be made on every organizational dimension is simply unrealistic of the
explorations that an organization seeks to integrate. The current model hence introduces ruggedness into the problem landscape by valuing the performance of a set of decisions according to its fitness on an NK landscape instead.
The NK model, originally adapted by Levinthal (1997) to demonstrate the variation in levels of
organizational performance that can derive from the interdependence between the decisions it makes. N refers to the number of dimensions on which the organization has to make a binary decision, while K is the number of other decisions on which the focal decision's value depends. The greater the value of K, the more interdependent the decisions, and thus the larger the number of possible optimum on a performance landscape. Similar to March (1991), the value of a set of decisions is a function of the binary choices made on each decision, enabling an easy substitution of March's original measure of organizational performance.
However, despite their similarities, the valuation of performance in March cannot be replicated on an NK landscape. While March evaluates strings on the basis of their match with reality, they are valued here according to their fitness on an NK landscape. This results in a different distribution of values across the landscape. Where in March, the initial values of individual actors' strings are originally distributed uniformly between 0 and 1, they are distributed normally on an NK landscape. Additionally, where the maximum possible value on March's landscape is 1, the maximum on an NK landscape is about 0.7. Further subtle differences in valuation arise because of a distinction between beliefs and actions that is made in March's original algorithm - allowing for the code or individuals to be evaluted even if they may not have made a firm choice on all dimensions - that cannot be accounted for in the same way on an NK landscape. The details of these differences are provided n the appendix. Ultimately however, as shown in Figure 3, the current model is able to replicate the results of the original March model, for an NK
landscape where K=0 (i.e. a smooth landscape, as per March, 1991)2.
2 One might note that the returns to performance in the NK (K=0) replication are more clustered at lower
values of pi, compared to in March's original. In results not shown here, this difference can be attributed to a necessary reduction in the number of dimensions of organizational decisions (i.e. N). The simulations in this paper were performed at N = 10, so as to be computationally feasible at high K. Additional details
on the model's sensitivity to N, and other parameter choices, are available in the appendix.
4. RESULTS
Once ruggedness has been accounted for, one would expect that the superiors observed by March's organizational code would be difficult to compare against one another. The code is likely to come across two actors who have made opposite decisions to one another with regard to financing, but who both perform well regardless, because of the sets of other complementary decisions they have made. As identified above, superiors on a rugged landscape are wont to be successful not because of individual decisions, but rather because of the complementarities between sets of decisions. Thus, in attempting to uncover the single best decision for each dimension, March's code is likely to learn an individual decision that is ultimately irrelevant to success.
The results of the simulation showed, however, that the code was able to learn surprisingly effectively on a rugged landscape - unexpectedly capable of surmounting these challenges on its own. As shown in Figure 4, regardless of the level of ruggedness (i.e. value of K), the average eventual performance that the code and the actors in the organization converged on remained above 0.653.
These results (denoted in red circles in Figure 4) are obtained at March's idealized exploration and exploitation ratio of p1=0.1 and P2=0.9.To better contextualize the findings, the eventual performance obtained on a smooth landscape (i.e. K=0) at March's less ideal learning rates of p1=0.9 and P2=0.9
(denoted by the black crosses in Figure 4) is lower than the returns of. Furthermore, as shown in Figure 4, this advantage is sustained across all values of K. Hence a poor ratio of pi to P2 appears worse for learning than even the most rugged landscape. In other words, organizations that attempt to explore a rugged landscape are still capable of doing better than organizations that fail to explore at all.
Key Observations
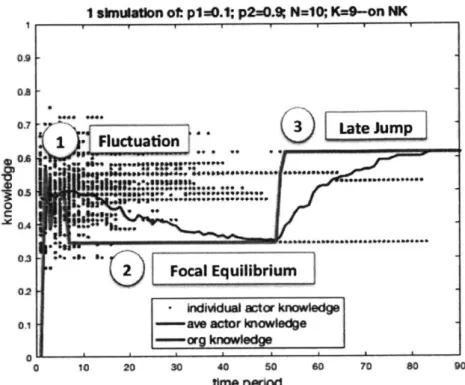
Examining one simulation in detail allows us to understand why the organizational code continues to perform well even on a rugged landscape. Figure 5 shows a sample of the organization's learning in action when K=9, where the bold red line indicates the code's value; the blue dots the value of individual actors; and the thin blue line the actors' average value. (Note that this sample simulation starkly contrasts the more straightforward learning scenario of a smooth landscape, shown in Figure 2.) Three significant phases are evident here, which correspond to the key dynamics involved in the rugged learning scenario of this paper.
1. Initial fluctuation: As expected from our prevailing intuition, the code does indeed have initial
difficulty learning across diverse superiors. Because superiors' success is more attributable to effective combinations of actions rather than individual actions, trying to copy the individual actions they have in common leads the code to learn irrelevant knowledge. As such, the value the code attains through copying superiors in this way fluctuates randomly.
2. Focal equilibrium: This fluctuation continues until the code becomes locked into a random set of
beliefs, indicated by the initial plateau in Figure 5. This lock-in occurs because the code attempts to copy
3 These results show the absolute fitness value eventually obtained by the organization. In results not presented here, the same advantage holds when the fitness value is normalized to the maximum possible value on the landscape. (The maximum possible value on an NK landscape increases as K increases, which is partially responsible for the increased fitness values at K>O.) The results in this paper were obtained at number of actors at M=50; the same as that originally in March. Each result was obtained from 500 simulations.
what the majority of superiors are doing on a given dimension; but at the same time, actors are copying the code, and thus reinforcing the majority of superiors. It is important to note that this occurs because the code has fallen to a sufficiently low value that even as superiors learn from it, they become more similar to the code without dropping out of the superior set. By persisting in the superior set, they only add to the majority that the code has already been learning from, creating a reinforcing loop of learning that locks the code into repeatedly yielding the same performance.
As such, despite being able to identify a set of superiors, the code plateaus as it is in fact already copying what it wrongly believes makes them successful. This is the challenge of a rugged landscape - that even though on every individual dimension, the code is doing what its best actors are, it cannot perform as well. As this period of false understanding continues, more and more superiors converge to the code's subpar set of beliefs, further dwindling its valuable learning opportunities. In summary, a "focal
equilibrium" is established, that locks the code into repeatedly yielding the same poor performance, and simultaneously attracts individuals to become more like it.
3. Late jump: However, despite this initially disappointing performance, it can be seen that later in the
simulation in Figure 5, the code appears to leap up to the value of the best actor in the organization. A snapshot of sample simulations at different values of K (Figure 6) shows that this dynamic is common across different values of K, as we can frequently see the code jumping to the highest performing actor midway.
Key Mechanisms
Indeed, as shown in Figure 7, this dynamic of late improvement holds true on average across multiple simulations. While there is initial discrepancy in the quality of the code across different values of landscape ruggedness, this gap in performance narrows over time. Overall, Figure 8 shows that despite the initial random fluctuation, the code eventually makes many more improvements than degradations over the course of the simulation. Not only is the code more likely to jump up on average, such
improvements are also able to capture the value of organizational members' explorations, where the code jumps up to the level of the top 16thpercentile of all individuals on average. These results imply that
instead of undergoing random fluctuations, the code is in fact able to execute specific improvements, which, as shown in prior figures, tend to appear later in the simulation.
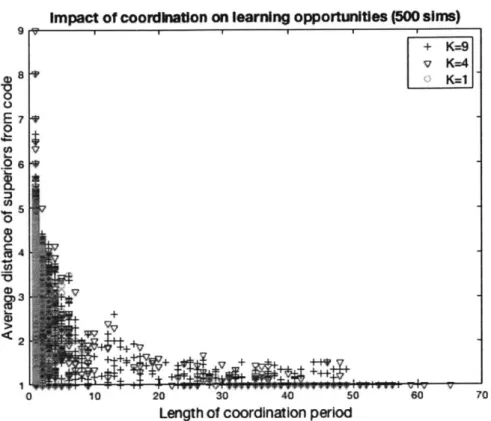
1. Convergence: The reason why such successful jumps can occur, and occur specifically at a late stage
in the simulation, is because of how the nature of superiors changes over time. Due to the period of lock-in, superiors become more socialized (via p1) to the code's focal equilibrium. In fact, as shown in Figure 9 below, with longer periods of convergence, the remaining superiors have socialized to the point of being
extremely similar to the code itself, eventually differing on only a single dimension.
Being only one dimension away means that the organizational code and its superiors are actually on the
same smooth landscape - explaining why the code is able to jump so successfully. In this smooth locality,
the problem of incompatibility no longer exists, because the code is indeed able to find a single best decision on every dimension, as it did in March (1991) originally. As mentioned, the similarity of these latent superiors is not surprising, as over time, the individuals have progressively been aligning
themselves more and more to the code.
4This count of improvements and degradations excludes cases where the code has not yet fully developed
its beliefs (i.e. where it is still NaN on some dimensions), as the value of the code will necessarily only improve from such a state.
It is important to note that what is critical here is not the similarity of the superiors to the code, but rather
their similarity to one another. March's code is designed such that regardless of where the code itself is, it is able to
jump
to whatever it deems to be the superiors' majority. What matters is not the distance of that jump, but rather the value of the majority it has determined. If all superiors were in exactly the sameposition on the landscape (i.e. yielding an average variance of 0), then copying the majority of their actions would yield the same value that they are individually able to capture, and the code does not face the challenge of potentially conflicting drivers of success.
Figure 10 clarifies that the learning challenge becomes more surmountable as superiors become more similar to one another. The distance between superiors is measured as the average of their variance on each dimension5. As shown in the figure, this distance is immaterial when the landscape is smooth (i.e. the curve for K=0)6. However as K increases, this increasing distance becomes fatal for the code, where its probability of improving (i.e. capturing the value of superiors) goes to 0 as superiors become directly orthogonal to one another (i.e. at distance of 0.5). Conversely, as the distance between superiors decreases (which increases the likelihood of their concentration around a smooth locality), the probability of the code capturing their value increases dramatically.
2. Valuable Innovation Post-Convergence: In addition to this process of convergence, equally crucial to
the code's success is the appearance of a valuable learning opportunity once convergence has occurred. Such opportunities appear either because superiors finally become close enough to one another (i.e. where they were originally different on many dimensions, they are now different on only one dimension that the code easily copies); or because inferior actors, who are already mostly similar to the code, undergo random mutations (due to the low pi) that offer superior solutions that are only one bit away. In organizational terms, this means that not only are superior performers offering solutions that are more proximate to what the code is able to interpret, but so are previously inferior performers learning where they can make improvements that will be salient to the code.
It is worth noting that these last-minute learning opportunities, obtained by changes in only one or a few bits, can be very valuable indeed. As shown in Figure 11, this is particularly so at high K, where the more rugged the landscape, the higher the expected value of a superior that is only one bit away. (Note that because the code only considers superiors, it would only consider those changes that offer a positive change in value, hence the higher expected value of any given superior.) Thus even as high K may increase the probability of the code locking into a poor focal equilibrium, a single-bit switch from this position yields a more valuable superior, the greater the value of K.
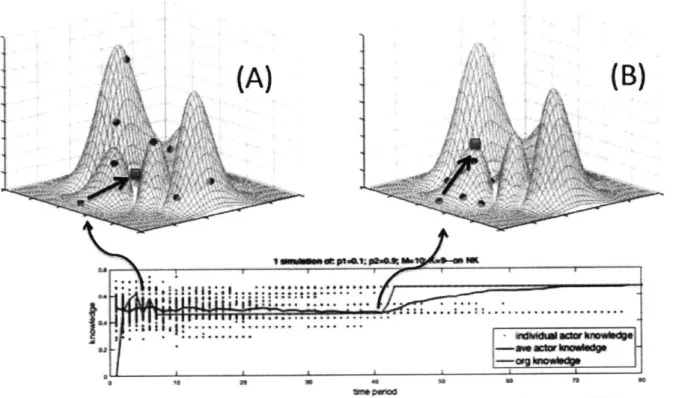
Coordinated hill climbing
Hence the code is able to solve the problem of rugged learning opportunities by in fact first making them smooth. Having found a variety of diverse superiors, the code simplifies its learning challenge by first coordinating these superiors through March's inherent process of mutual learning (i.e. the simultaneous
5 Distance between superiors, a (x) =, where S is the number of superiors, xij is the value of each superiorj on a given dimension i, pi is the mean value for dimension i across all superiors and N is the total number of dimensions.
6 There are no values at high distance between superiors as the code here jumps so quickly to the best of
superiors that in most cases there is only 1 superior available to learn from, obviating the challenge of learning across incongruent superiors.
action of pi and P2), such that they become more similar to one another. This dynamic is summarized in Figure 12 below - at (A), superiors (given by the blue dots) are spread across a rugged landscape, such that when the code (given by the red square) attempts to learn from them by 'averaging' across their successful decisions, it lands at a non-valuable position in the middle of them. However, in (B), once superiors have socialized to the code so as to be on the same hill as it, the code's methodology of learning
by 'averaging' takes it to the top of this local hill.
The focal equilibrium, which on first glance can appear potentially harmful because of the loss of superiors to an inferior organizational code, can instead now be seen as an essential process of
convergence. In fact, as established above, this equilibrium must occur at a necessarily low value in order to enable lock-in, and thereby engage the process of convergence. As much as valuable opportunities
might be lost during this stage, it is also a chance for individuals to socialize to the code, such that the learning opportunities they provide the code become more proximate over time. The initial sub-par value of the code thus becomes a location on the landscape around which actors in the organization can
converge. Having converged, towards the end of the simulation, any remaining opportunities now lie on the same local hill. The code and individual actors can then climb this hill, as they do originally in March
(1991), and potentially summit it.
5. DISCUSSION
The goal of this study was to understand how an organization might learn from a set of superiors who reside on a rugged landscape - where their success derives more from complementarities between their actions as opposed to individual actions themselves. Superiors are then likely to exhibit actions that appear incongruous with one another, and an organization that observes these superiors would be hard pressed to decipher and learn from their success.
This problem is represented here by applying March (1991) onto an NK landscape, as an attempt to better understand the challenges of exploiting such unique successes - only to discover that buried alongside it is also the solution to this challenge: the convergence mechanism enabled by mutual learning. It is shown that as challenging as the task of learning across diverse superiors might be, it becomes plausible if superiors are to first coordinate with the organization's state of knowledge.
The overall implication for organizations is therefore that letting individuals loose to explore is indeed critical, as it supersedes the returns of not exploring at all, across all degrees of landscape complexity. March's (1991) recommendations therefore hold even in a rugged landscape. However, exploration on such a landscape will only be valuable if the organization engages in constant convergence with its individuals - with the organization progressively learning from what its individuals have found, and individuals progressively aligning themselves with the organization's state of knowledge. Although this may result in an initial reduction in performance for the whole organization, it is a valuable phase of convergence that will eventually lead them to climb a common hill together.
Strategies for simplification
This paper adds to a set of studies that have proposed strategies to ease the organization's challenge of learning on interdependent landscapes, by first simplifying the task. One such study is Lounamaa &
March (1987), that highlights the causal ambiguity inherent in interdependent tasks, and proposes slowing the organization's learning attempts, so as to allow "one part of the system to learn while another part is held constant" (p. 122). Another such study is Ethiraj & Levinthal (2009), who address the tendency for
organizations to become trapped in local optimum, when trying to "improve performance on at least one goal without causing performance deterioration on the remaining goals" (p. 14). They propose a set of strategies that seek to overcome this challenge by simplifying the constraints that the organization must attend to - whether by pursuing only a subset of them, pursuing subsets in parallel, or pursuing subsets sequentially - which yields a higher performance than if the organization were to attempt to satisfy all of its goals at once.
These studies, however, seek to facilitate learning in which there is a single source of feedback. In the present study, the challenge of interdependence is further complicated by multiple sources of feedback, which come in the form of multiple superiors, each representing unique forms of value. This paper thus contributes a simplification strategy that applies to such a scenario.
Value of convergence vs. divergence
Lazer & Friedman (2007) and Fang et al. (2010) both come to a conclusion that differs from this paper's -where performance is improved by reducing the amount of convergence between agents, as opposed to encouraging it. They present a similar problem landscape of "parallel problem-solving", where "the agents in question are all wrestling with approximately the same problem", to which there are "many plausible solutions" (Lazer & Friedman, 2007, p. 668). In those papers, the recommendation is to reduce the amount of convergence between agents; proposing means of structural separation that will permit
localities of improved solutions to grow in isolation, as opposed to being overwritten by a subpar global solution early on. Conversely, this paper appears to defy their recommendations by promoting
convergence, so as to enable salient innovations to emerge.
The key reason for this difference is the presence of the code in the current simulation. In Lazer &
Friedman (2007) and Fang et al. (2010), individual agents are at liberty to learn directly from one another, rather than through a centralized organizational planner that is the code. Additionally, while the code
learns by amalgamating the actions of a group of superiors, agents in those papers learn only from the single best superior they are connected to. After identifying their best performing neighbor, agents emulate their actions (albeit with occasional error in replication), thereby executing a greedy learning
strategy. The value of convergence proposed here is thus to counter the confusion that the code can face through amalgamation - a confusion that will not occur in the other scenario. There, the impediment to performance is less confusion than it is the availability of learning opportunities, which is preserved through the use of network segregation. This is in fact comparable to the inherent value in agents' low rate of socialization in this paper, where they remain slow to conform to a global solution (i.e. the highest performance is always attained at low pi).
The findings in this regard are therefore compatible - that convergence can limit the availability of valuable innovations. But convergence can, on the other hand, be essential to simplify the learning challenges deriving from amalgamating on a rugged landscape, which were not incorporated into prior studies.
Mental representations in learning
This paper also contributes to the literature regarding the mental representation required to navigate a rugged landscape. By leveraging March's approach, the organization in fact maintains a faulty
representation in its search process - it assumes the landscape is smooth, and tries to learn as if it is so by identifying individual best decisions. Yet it is shown that this is in fact a route to success, as it enables convergence. It is only through this faulty approach of searching for majority actions on individual dimensions that it is possible for the organization to become stuck (as the search for the majority tends to
reinforce the majority), in a place that actors can then converge upon, in order to present a more local innovation. As such, the results here concur with Csazar & Levinthal (2016) - that "sometimes, incomplete representations are preferable to complete representations" (p. 2041).
Evaluation of innovations
Finally, the results here are applicable to how organizations might design their open innovation practices, or how they might structure their management practices around the evaluation of internal R&D.
This learning challenge in this paper is akin to an organization that conducts an open innovation
competition in order to yield solutions from a crowd. Such competitions tend to return solutions that are not only very different from what the organization is currently doing, but also very different from one another. Similarly, such a scenario applies to an organization trying to yield solutions from its own internal departments, who despite being potentially more aligned with that organization than external open innovation participants, may still present solutions that are likewise incompatible with one another. Regardless of the source of ideas, they will "[provide] no benefits to the firm if the firm cannot identify the relevant knowledge and incorporate it into its innovation activities" (West & Gallagher, 2006, p. 322). This simulation suggests that the solution is to conduct open innovation competitions, or internal R&D, through multiple rounds, rather than as one-off events, in order to allow innovators to become more coordinated with the organization over time. After a first round of innovation, innovators would receive feedback on how the organization has tried to inadequately incorporate what they have proposed. Innovators can then use subsequent rounds to bring their innovations gradually closer to what the
organization is currently doing, thereby providing something the organization is better able to incorporate. Such a recommendation is in fact similar to the findings of Truelove (2019), where internal R&D teams that coordinated more frequently with user innovators were better able to translate their ideas into a value product.
However, it is also worth noting from the results that this period of convergence may last for quite a while, during which the organizational code remains stuck in a focal equilibrium. One might expect that an organization without sufficient patience might not endure this interlude; especially in cases where superiors have entirely disappeared. This impatience would be justified as well, as the code undergoes between 20-30 periods in this interim plateau, and one can expect that an organization would be unwilling to tolerate middling results from the crowd or from an R&D division for quite so many cycles of
evaluation. Disappointed with the returns, the organization calls off the search, not realizing that a simple tweak from an inferior actor could return something remarkably more valuable in just the next period. Further work might thus identify strategies to speed up this process of convergence, while still preserving its benefits.
TABLES & FIGURES
I..
IA'
I"
Figure 1. Original Figu
0.9 oat 05 OA 02 0.l 0 re1 $4 U 1 3 1 *
Pouas1. Eect ofiLeni R i E*W(ps, Ep3) gEqwiisKmowhedge.
M 30 N - 50;0 sSatios.
from March (1991), comparing performance under varying values of exploration versus exploitation
1 simulation of: p1=0.1; p2=0.9
10 20 30 40 so s0 70 80 90 100
time period
Figure 2. One simulation of learning over time in a replication of March's organization
15 '34, '345 alactor knowledge r kowedge --
ae
acton
In
I.
am 0A2 O0M OM5 wL 84 W U W u U0.1 suAMusu We b4 F~m .U*~M. mtSt.m head.3qUA gw M-*-s 3.Ric oFigure 3. Replication of March (1991)
R"con of March919g 1, gNWID , Ka0 500bS)
02 0,3 0A 05 OS 0.7 02 09
p1
using a smooth NK landscape (i.e. K=O) Average Code Knowledge at Equlbium, 500ns
0 0 0 0 x x x x x x x x 00 p1=0.1, p2=0.9| |x p1=0.9, Ip2=0.91 0 1 2 3 4 5 6 7 8 g K
Figure 4. Eventual performance (measured by absolute fitness value) that the organization converges on, at different degrees of landscape ruggedness
16
"VI N-- - p~. - p.o N20 0.8 0.75rOM -ILOS
-055 OAS CA P"A OAS
-I sn*onot p=0.1; p2a.; NeO KP9-on NK
as-1
. FluctuationJ
03 .Qa'.**j'•••u'jen'n
2 Focal Equilibrium 02. dMdul ator knwedg
01 --- ave acr knowedge
--rgknowledge
0 10 20 30 40 50 00 70 00 90
*merod
Figure 5. One simulation of March's organizational code navigating a rugged landscape. Three phases of the code's learning are evident: (1) where the code initially fluctuates in value; (2) an
initial equilibrium that individuals' values regress to; and (3) a late jump to greater value.
tI A
K=0
K=1
K=2
~ K--3 K--4 K--5
K 6
K=7
K=8
Figure 6. Sample of single simulations at different levels of ruggedness
Normazed QuAty of Org. Code over Time, p1=0.1, p2=0.9, 500sIms
10 20 30 40 so 60
Time pedod
70 go 90 100
Figure 7. Normalized quality of organizational code over time, on landscapes of varying ruggedness. Values are normalized for easier visual comparison.
NumberaoWvmwwtsvs. degradrations .,1 2 3 4 6 7 9 K 0 07 066 16 is 05
QfaIty of org. code's Impmvement
1 2 3 4 a a 7 a
K
Figure 8. Likelihood and quality of code's improvements versus degradations
18
0.0 0.7 05 gas LLO 02 0.1 01. 0 -- MO --=4
SK=-9 C .03 j2 M 0• Improvments M * s 00 00 00 9Impact of coortiation on learning opportunites (500 lis)
+ K=9 * K=4a
e
oK=1
8 0 10 20 30 40 so so 70Length of coordination period
Figure 9. Change in superiors' distance (measured as Hamming distance: the number of elements on a superior's string that differ from the code's) as a function of coordination duration (i.e. the
time for which the code remains in a focal equilibrium)
Org. code jump qualty vs. dtance between superiors (1000 sns) I I I1 ++ + + K=9 c) K=1 0.5 E - ! OA -03 §02 0 C-& + + 0 OOS 0.1 0.15 02 025 03 035 OA
Distance between superiors
Figure 10. Learning quality as a function of Hamming distance between superiors, with regression lines overlaid.
Expected Impovement from changing 1 bit on an 0 2 NK landscape (1000 sims)
, 1 'p
9
C E 0.18 -0.16 0.14 0.12 0.1 o08 OBS 00D4 02 0 1 2 3 4 5 6 7 8 9 KFigure 11. Expected improvement in value resulting from a difference of one bit on an NK landscape.
20
I-+ + ++ + + +II
-Kom
11 .1 i
I-
mmarnwde
sa-- + teilg
I-.onss
as M fm
Figure 12. Summary of the learning dynamics on a simplified representation of an NK landscape: In (A), the code, in trying to copy the decisions that superiors have in common, will jump to an irrelevant position that lies in the middle of them. However, once superiors have socialized to be on
the same hill in (B), this 'average' position is now at the top of their local hill.
21
REFERENCES
Afuah, A., & Tucci, C. L. (2012). Crowdsourcing as a solution to distant search. Academy of
Management Review, 37(3), 355-375.
Aral, S., & Van Alstyne, M. (2011). The diversity-bandwidth trade-off. American Journal of
Sociology, 117(1), 90-171.
Barney, J. B. (1985) Information cost and the governance of economic transactions. In R. D. Nacamall &
A. Rugiadini (Eds.), Organizations and markets (pp. 347-372). Milan. Italy: Societa Editrice it
Milano.
Cassiman, B., & Veugelers, R. (2006). In search of complementarity in innovation strategy: Internal R&D and external knowledge acquisition. Management science, 52(1), 68-82.
Csaszar, F. A. (2013). An efficient frontier in organization design: Organizational structure as a determinant of exploration and exploitation. Organization Science, 24(4), 1083-1101.
Csaszar, F. A., & Eggers, J. P. (2013). Organizational decision making: An information aggregation
view. Management Science, 59(10), 2257-2277.
Csaszar, F. A., & Levinthal, D. A. (2016). Mental representation and the discovery of new strategies. Strategic Management Journal, 37(10), 2031-2049.
Denrell, J., & March, J. G. (2001). Adaptation as information restriction: The hot stove
effect. Organization Science, 12(5), 523-538.
Ethiraj, S. K., & Levinthal, D. (2009). Hoping for A to Z while rewarding only A: Complex organizations and multiple goals. Organization Science, 20(1), 4-21.
Fang, C., Lee, J., & Schilling, M. A. (2010). Balancing exploration and exploitation through structural design: advantage of the semi-isolated subgroup structure in organizational learning. Organization
Science, 21, 625-642.
Fleming, L., & Sorenson, 0. (2001). Technology as a complex adaptive system: evidence from patent
data. Research policy, 30(7), 1019-1039.
Grant, R. M. (1996). Prospering in dynamically-competitive environments: Organizational capability as knowledge integration. Organization science, 7(4), 375-387.
Katila, R., & Ahuja, G. (2002). Something old, something new: A longitudinal study of search behavior and new product introduction. Academy ofmanagementjournal, 45(6), 1183-1194.
Khilji, S. E., Mroczkowski, T., & Bernstein, B. (2006). From invention to innovation: toward developing an integrated innovation model for biotech firms. Journal ofproduct innovation management, 23(6),
528-540.
Knudsen, T., & Levinthal, D. A. (2007). Two faces of search: Alternative generation and alternative evaluation. Organization Science, 18(1), 39-54.
Koput, K. W. (1997). A chaotic model of innovative search: some answers, many questions. Organization
Science, 8(5), 528-542.
Lavie, D., & Rosenkopf, L. (2006). Balancing exploration and exploitation in alliance formation. Academy ofmanagementjournal, 49(4), 797-818.
Laursen, K., & Salter, A. (2006). Open for innovation: the role of openness in explaining innovation performance among UK manufacturing firms. Strategic managementjournal, 27(2), 131-150.
Lazer, D., & Friedman, A. (2007). The network structure of exploration and exploitation. Administrative
Science Quarterly, 52(4), 667-694.
Levinthal, D. A. (1997). Adaptation on rugged landscapes. Management science, 43(7), 934-950.
Levinthal, D. A., & March, J. G. (1993). The myopia of learning. Strategic managementjournal, 14(S2),
95-112.
March, J. G. (1991). Exploration and exploitation in organizational learning. Organization science, 2(1),
71-87.
Powell, W. W., Koput, K. W., & Smith-Doerr, L. (1996). Interorganizational collaboration and the locus of innovation: Networks of learning in biotechnology. Administrative science quarterly, 116-145. Rahmandad, H. (2012). Impact of growth opportunities and competition on firm-level capability
development trade-offs. Organization science, 23(1), 138-154.
Rivkin, J. W., & Siggelkow, N. (2003). Balancing search and stability: Interdependencies among elements of organizational design. Management Science, 49(3), 290-311.
Rosenkopf, L., & Almeida, P. (2003). Overcoming local search through alliances and mobility. Management science, 49(6), 751-766.
Rosenkopf, L., & Nerkar, A. (2001). Beyond local search: boundary-spanning, exploration, and impact in the optical disk industry. Strategic Management Journal, 22(4), 287-306.
Siggelkow, N., & Levinthal, D. A. (2003). Temporarily divide to conquer: Centralized, decentralized, and reintegrated organizational approaches to exploration and adaptation. Organization Science, 14(6),
650-669.
Singh, J. (2008). Distributed R&D, cross-regional knowledge integration and quality of innovative
output. Research Policy, 37(1), 77-96.
West, J., & Gallagher, S. (2006). Challenges of open innovation: the paradox of firm investment in open-source software. R&d Management, 36(3), 319-331.
Zollo, M., & Winter, S. G. (2002). Deliberate learning and the evolution of dynamic
capabilities. Organization science, 13(3), 339-351.
APPENDIX
A.1 Replication of March (1991)
The following are the key features of March (1991) that have been replicated here:
- Representation of the organization as a set of beliefs: The domain of the organization is
summarized as a set of binary beliefs it can make on N dimensions. Beliefs can also be withheld, such that a given dimension may not have a belief associated with it yet. In March (1991), these binary decisions are either 1 or -1, while the lack of belief is assigned a 0. However, in this paper, in order to implement March onto an NK landscape, the binary decisions that the code can make are either 1 or 0, and a lack of belief is designated as NaN.
- Individual versus organizational code beliefs: Each of the M individual actors in the organization
possesses their own string of beliefs. (E.g. If the number of dimensions N is 5, then an individual might have the string of beliefs "1 NaN 0 1 NaN", where 1 and 0 correspond to beliefs, and NaN corresponds to the lack of belief.) In addition, there is also an organizational code that has its own string of beliefs. This code can be thought of as a pool of centralized knowledge that captures the knowledge of individuals to some degree. The individuals and code learn from one another through a process of mutual learning described below.
- Turning beliefs into action: At every time period, these beliefs turn into action, and can be thought
of as being evaluated in the real world, perhaps akin to a prototype being built. For those dimensions on which a belief is held, the corresponding action is taken (i.e. if a belief of 0 is maintained on the first dimension, the action for that dimension is also 0.). However for those dimensions on which there is no belief (i.e. where the value is NaN), an action of 1 or 0 is randomly assigned. As such, beliefs differ from actions in that actions take a random value on areas where no belief is held, and
.7
correspond with belief otherwise .
- Valuation of action: In the same time period, these actions are valued. This can be thought of as
feedback being received on the prototype, where the organization obtains information about how well it performs. In March, there exists an ideal set of actions (which he terms as "reality"), and actions are valued based on the extent to which the actions match this reality - where the value of total set of actions is the average of the value of each action's match with reality. However, for this paper, value is now determined by a string's fitness on an NK landscape, as opposed to the matching of reality (to be described further below). This valuation is discussed further below. All individuals and the code are evaluated, such that their actions each have a corresponding value.
- Code learning from superiors: Given these valuations, there is a set of superior actors who prove to
perform better than the code. The code then attempts to decipher what in these superiors' sets of actions are the sources of their success. Going dimension by dimension, the code identifies the majority action being taken by superiors on that dimension. If this majority action differs from the code's pre-existing belief (or where it has no pre-existing belief) on that dimension, then it seeks to learn from the superiors' majority. However, despite identifying this desired learning, actual learning
by the code only occurs with probability P2, which increases as a function of the size of the majority.
- Actors learning from the code: Subsequently, each individual modifies their beliefs to match that of
the code with probability p1. Specifically, the belief of every dimension of every actor has the
7Note that in March (1991), this transformation of belief into action occurs only for individual
actors. The organizational code, on the other hand, is evaluated on the basis of its actions alone. As is explained below, this is unfortunately not replicable when implementing March on an NK landscape. In this paper's model, the code must likewise be turned into a set of actions (through random assignment of states where it has no pre-existing belief) before it can be evaluated.
probability p1 of copying that of the code's (if the code indeed has a belief on that dimension as opposed to NaN), where it differs from the code.
- Simulation progression: At the start of the simulation, the code has no pre-existing beliefs (i.e. all
values on N dimensions of belief are set to NaN), while the individual actors' beliefs are randomly assigned, where each dimension of their belief has equal probability of being assigned 1, 0 or NaN.
A2. Implementing on an NK landscape
Despite the similarity in structuring the organization as a string of binary decisions in both March (1991) and the NK landscapes, there are still some key changes that cannot be resolved when implementing one onto the other. While March evaluates strings on the basis of their match with reality, in this paper, they are valued according to their fitness on an NK landscape. This results in a different distribution of values across the landscape. Where in March, the initial values of individual actors' strings are originally
distributed uniformly between 0 and 1, they are distributed normally on an NK landscape. Also, where the maximum possible value on March's landscape is 1, the maximum on an NK landscape is about 0.7. Another necessary modification is the absence of punitive valuation. This mechanism of punitive valuation is not elucidated in March (1991), but is revealed in Christensen & Denrell's (working paper) replication of the original model. This is where an individual decision is in fact given a negative score when it fails to match reality. Hence the original valuation assigned to an individual bit (i.e. a single
dimension on the string) in March is either 1 (where it matches reality) or -1 (where it does not). This cannot be replicated on an NK landscape because just as there is no longer a universally correct decision for a given dimensions, there is also no longer a universally wrong one. Excluding this from March, however, affects only the absolute values of performance, not the relative values - which means the set of
superiors is still the same, and the dynamics of learning are preserved regardless.
In addition, as introduced above, while March allows for the code to be evaluated only on its beliefs (whereas the individual actors' beliefs must first be converted to actions), this cannot be done on an NK landscape. March's valuation can allow for certain dimensions to be excluded from the overall valuation of the string (which averages the values of individual bits), as each dimension is independent of the rest. On an NK landscape, however, the value of every dimension's action is assigned as a function of other dimensions', and there is no way to value a certain dimension when a neighbor's has a value of NaN. Hence, in order to value the code, it too must be converted from belief into action. The same method of
conversion for individuals is used for the code, where any lack of belief is randomly assigned a I or 0 before the whole string is evaluated.
A3. Sensitivity to number of individuals M, and number of dimensions N
One might note that in the attempted replication of March's results using the current model at K=0, the returns to performance in the replication are more clustered at lower values of pi, compared to in March's
original. In results not shown here, this difference can be attributed to a necessary reduction in the number of dimensions of organizational decisions (i.e. N). The simulations in this paper were performed at N=
10, so as to be computationally feasible at high K; unlike March's original model which comprised 30
dimensions. As shown in Figure 3, the impact of this is that the returns to individuals' explorations (i.e. low pi) are less sensitive to the code's degree of exploitation (i.e. P2). With higher N, individuals have more dimensions on which they can differ from the code, such that the variance in individuals'
explorations is greater at higher N. With a greater variance in individuals' returns, the organizational code must be quick to pick up the superior variations that are available (i.e. have high p2). However, with a
lower variance in individuals' returns, many other individuals are likely to have found the same valuable