Télécharger Cours Introduction au monde d'Unix pdf
Texte intégral
Figure

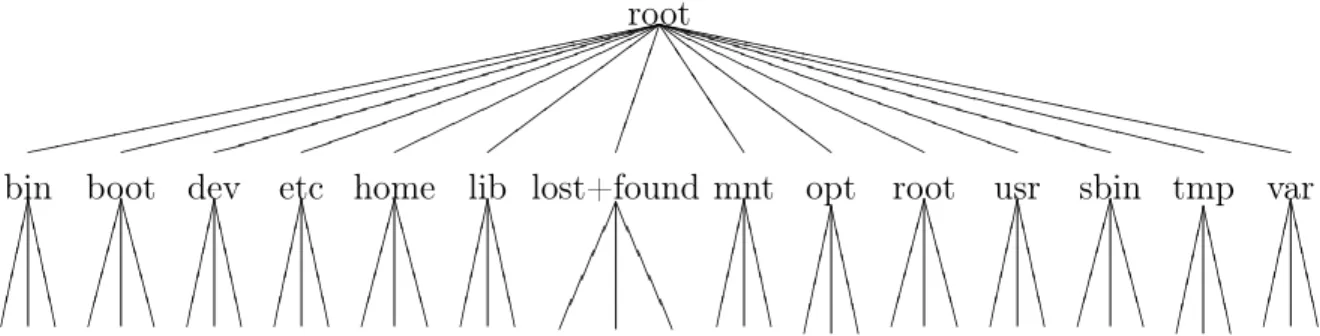
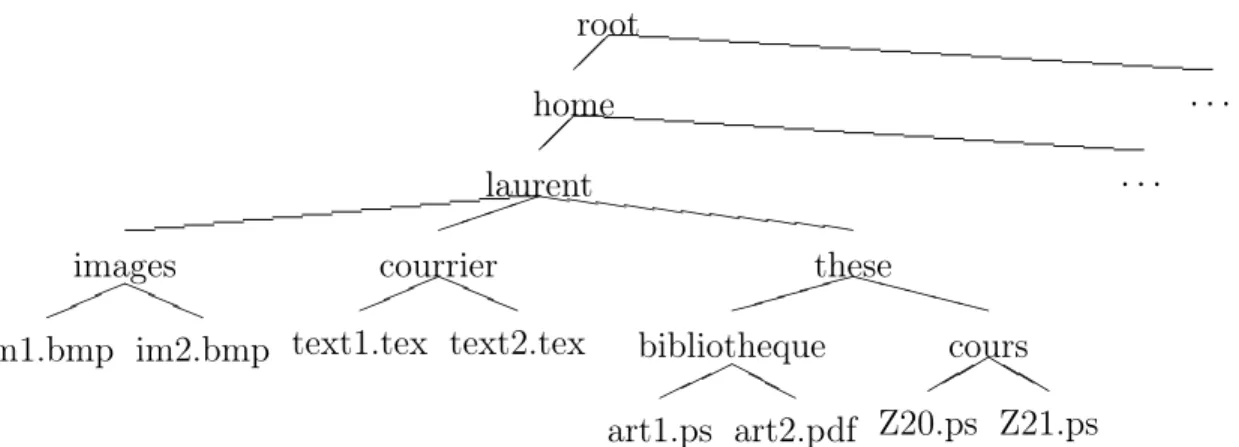

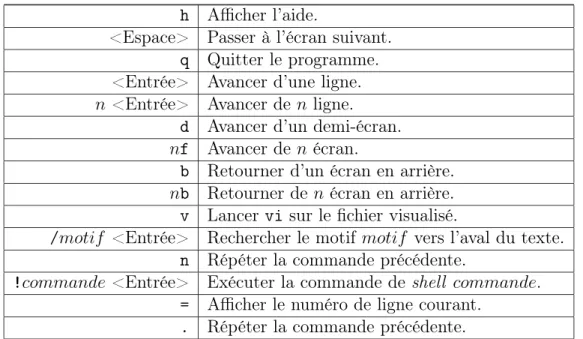
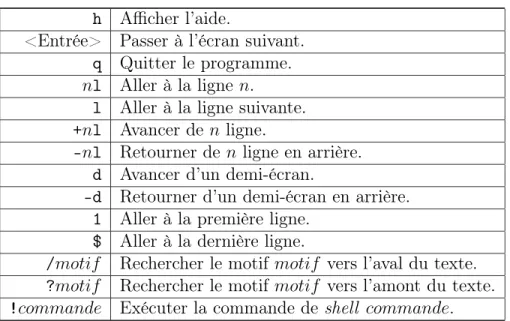
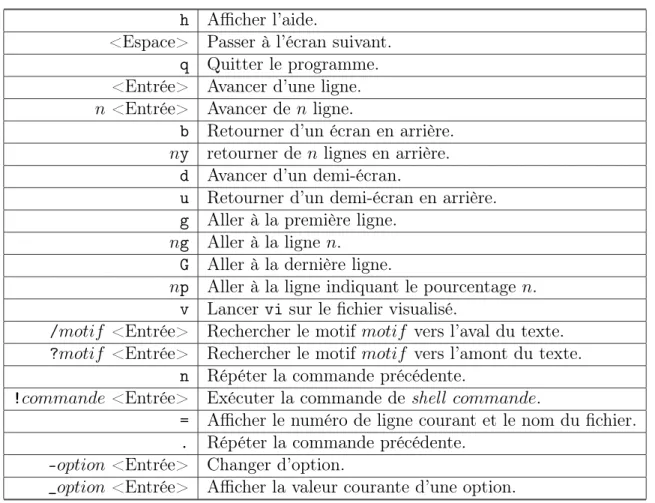
Documents relatifs
Les enquêtes de déplacements urbains : mesurer le présent, simuler le futur = Urban travel survey methods: measuring the present, simulating the future : Actes du colloque des
Ce que j'ai pu constater, et Fassin (1992) le souligne également, c'est que la cause et l'origine du mal sont le plus souvent extériorisées par l'individu et la société. En
Plusieurs conclusions émergent de cette modélisation séculaire du système de transport. • La relation de long terme entre la production industrielle et le volume total de trafic a
A la vue des préoccupations en termes de développement durable, une volonté de prendre en considération les questions d’équité sociale resurgit des discours des décideurs.
Bien que les intervenants en général s’entendent pour dite que les programmes nationaux ont leur place en médium pour les sentences vies, trois intervenants ( 2 ALC et un ACII
améliorer ses propres pratiques pour que les mouvements des marchandises se passent au mieux : un appel à la mutualisation, à la concertation visant un partenariat public-privé,
(2001), par une étude détaillée de la fréquentation et des pratiques liées à une ligne de transports collectifs desservant un quartier difficile de Marseille, montrent bien que
Pour ceux qui ont niveau d’éducation relativement faible (sans instruction, primaire ou moyen) les femmes ont une tendance plus marquée à ne pas être couvertes par
