Multiclass feature learning for hyperspectral image classification: sparse and hierarchical solutions
Texte intégral
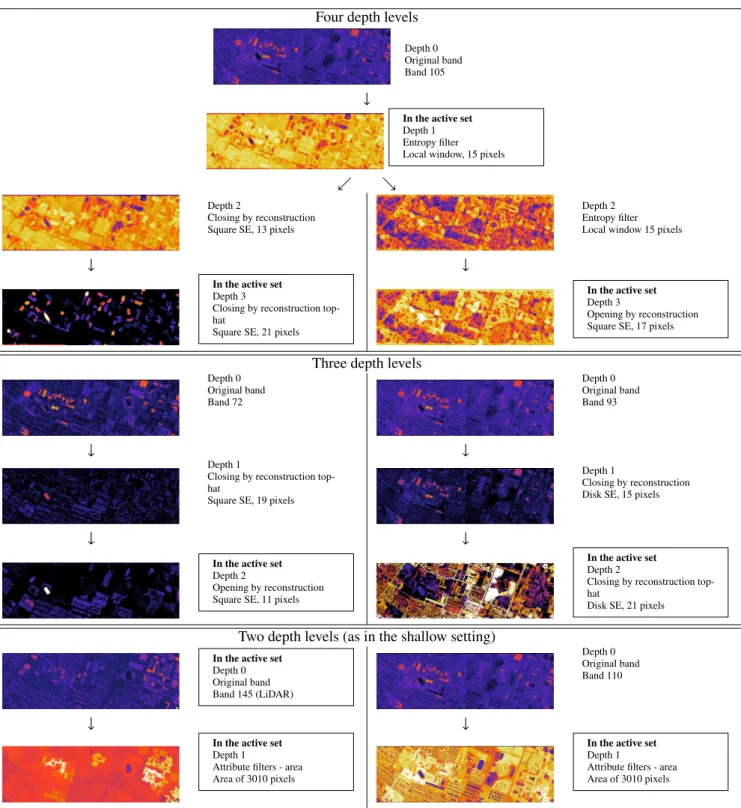
Figure
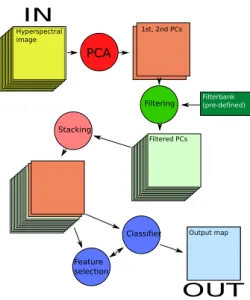
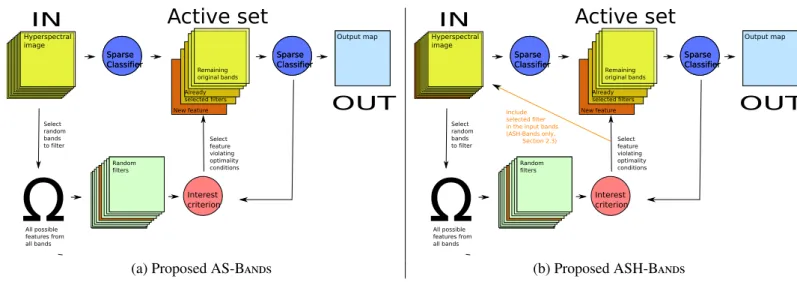
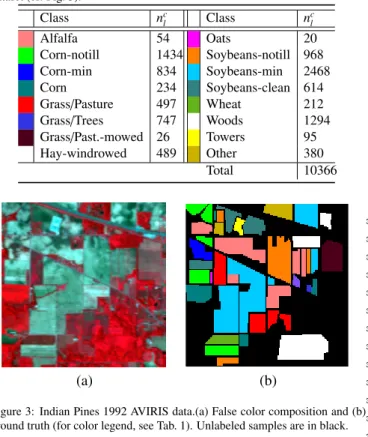

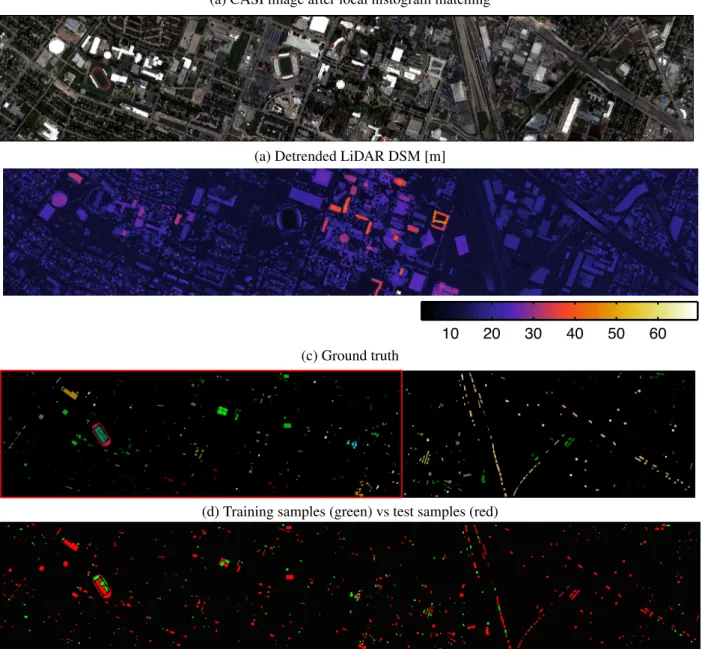
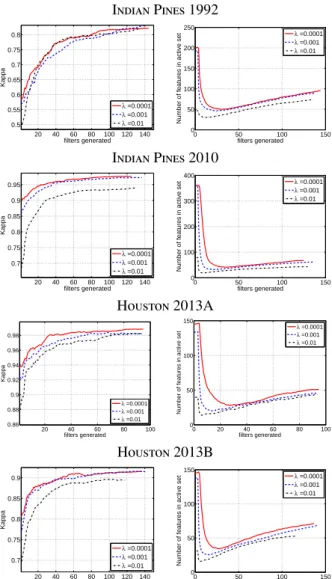
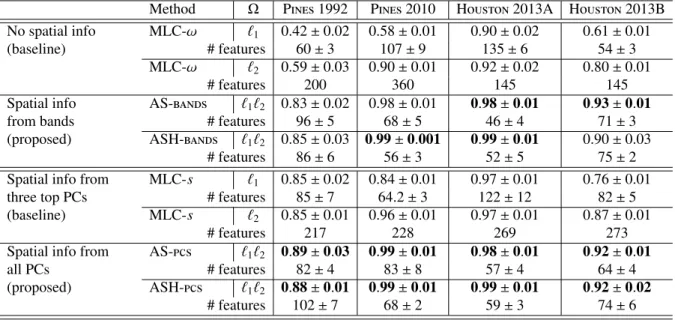
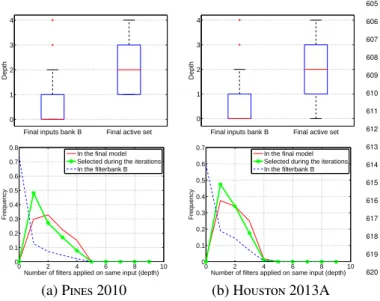
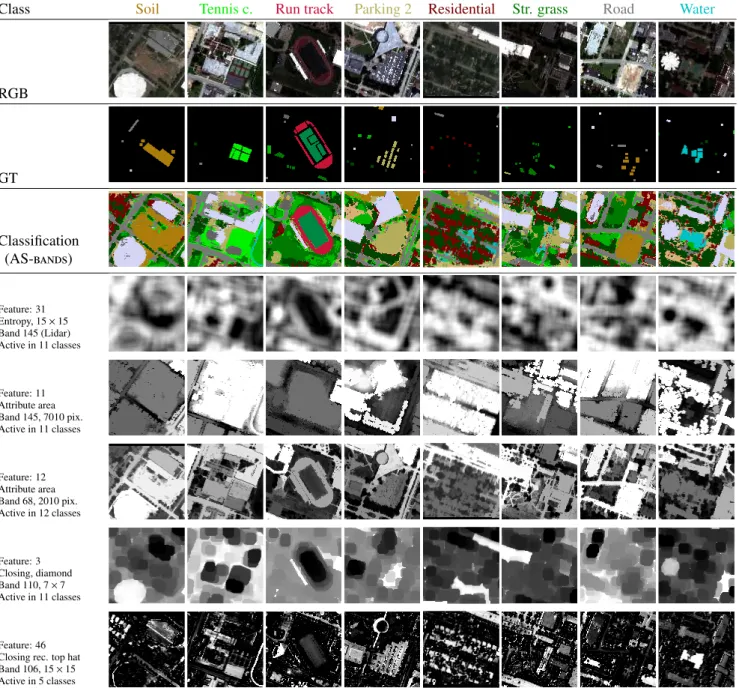
Documents relatifs
Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of
Such an exceptionally high in vivo targeting efficiency is due to an increased cell surface binding achieved by Nb-mediated interac- tion that compensates the reduced IFN
neighborhood effects on walking behavior tend to be greater than self-selection
Keywords: Stereo, hierarchical segmentation, robust regression model, waterfall, disparity map, densification..
The images (reference, HS, and MS) and the fusion results obtained with the different methods are shown in Fig. More quantitative results are reported in Table II. These results are
Results. We show that i) sparse reconstruction performs as well as CLEAN in recovering the flux of point sources; ii) performs much better on extended objects (the root mean
Similarly, for any given model
h des conditions climatiques similaires. Mots clts: charges de neige, neige glissante, toits inclines, Cpaisseurs de neige, densites de neige, rugositC de la surface,
