Tree mining: Equivalence classes for candidate generation
Texte intégral
Figure
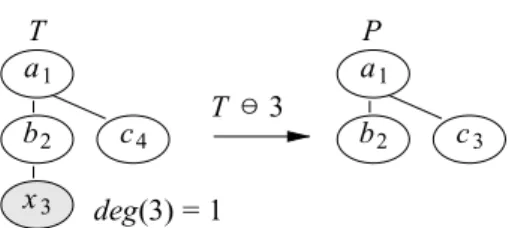
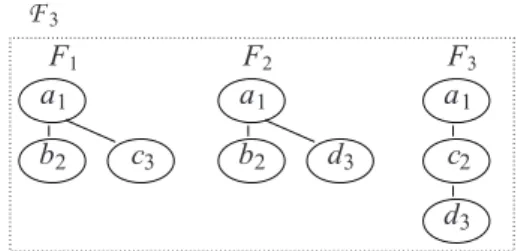
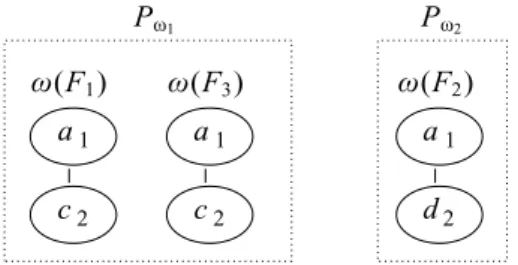
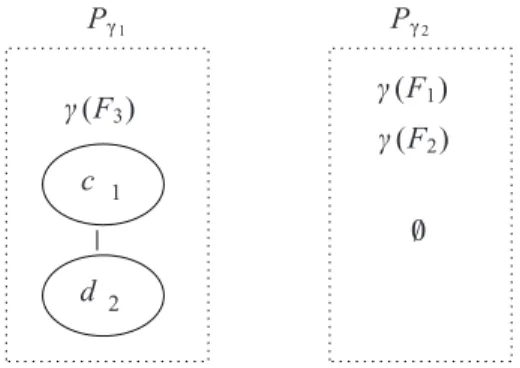
![Fig. 6. Candidate trees generated by the product operator applied on the class [P δ 1 ] and [P δ 2 ].](https://thumb-eu.123doks.com/thumbv2/123doknet/13951042.452321/9.892.242.619.135.813/fig-candidate-trees-generated-product-operator-applied-class.webp)


Documents relatifs
MICROSCOPE is a French Space Agency mission that aims to test the Weak Equivalence Principle in space down to an accuracy of 10 − 15.. This is two orders of magnitude better than
They focused their attention on the interval logic AB of Allen’s relations meets and begins extended with an equivalence relation, denoted AB ∼ , interpreted over finite linear
However, it is important to avoid building the complete trie, but only some upper part of it, so that the nodes (i.e. their root paths) represent reasonable candidates for
surjectives) et la troisi` eme est surjective (resp... D´ eterminer la classe d’´ equivalence
The definition given here it is the natural analogue of the concept of Cartan algebra for von Neumann algebras, introduced by Feldman and Moore [1]... We assume that U in Definition
Then, we show that the équivalence problem for linear and non-deleting letter to letter top-down transducers can be reduced to the équivalence problem for relabelings (section 4)...
First we construct an infinite sequence of rational curves on a generic quintic V such that each curve has negative normal bundle.. Then we deform to quintics with nodes in such a
In this paper, we propose a practical method, given a strict triangular norm with a convex additive generator, for deriving a fuzzy equivalence relation whose reflexivity
