Do branch lengths help to locate a tree in a phylogenetic network?
Texte intégral
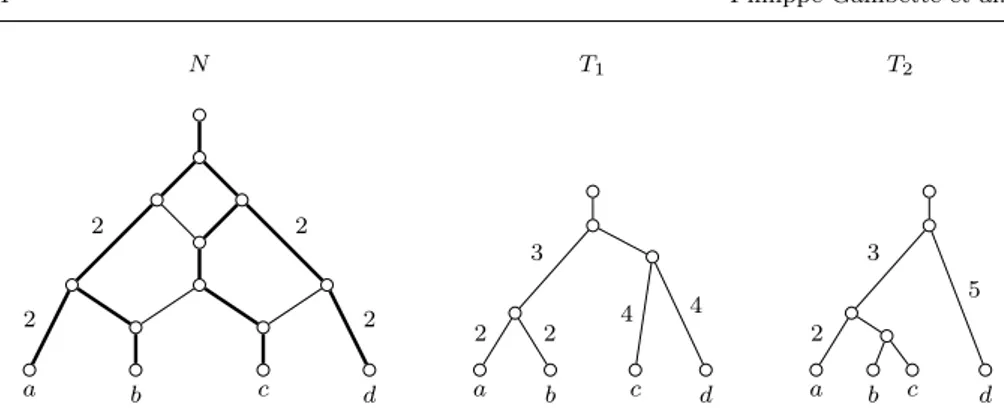
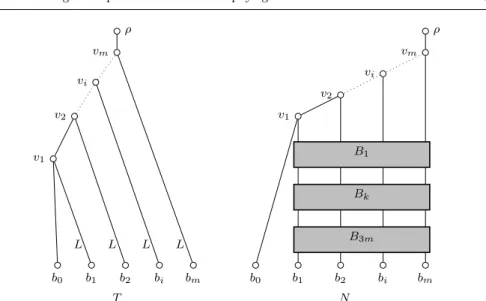
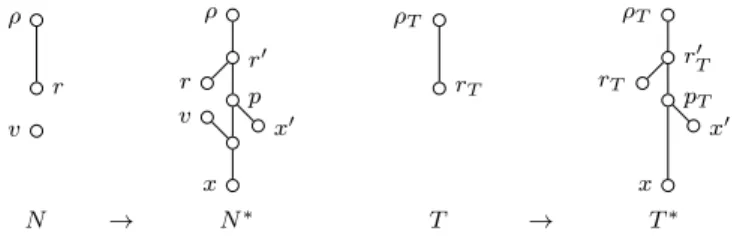
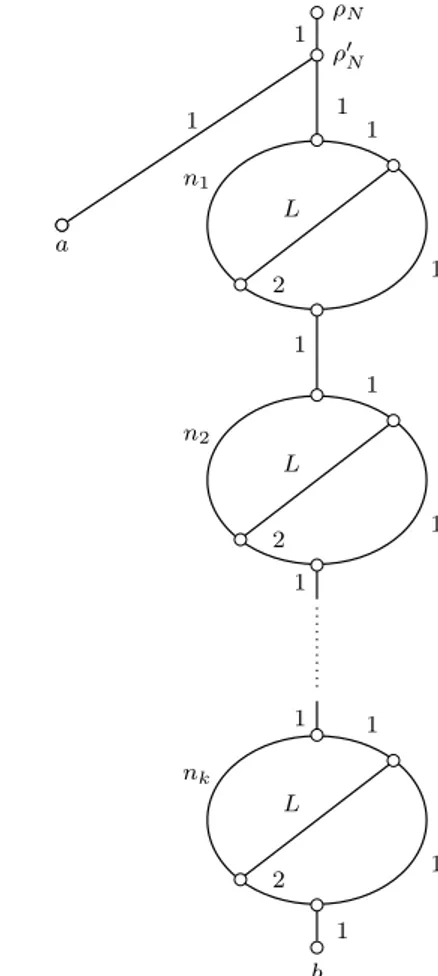
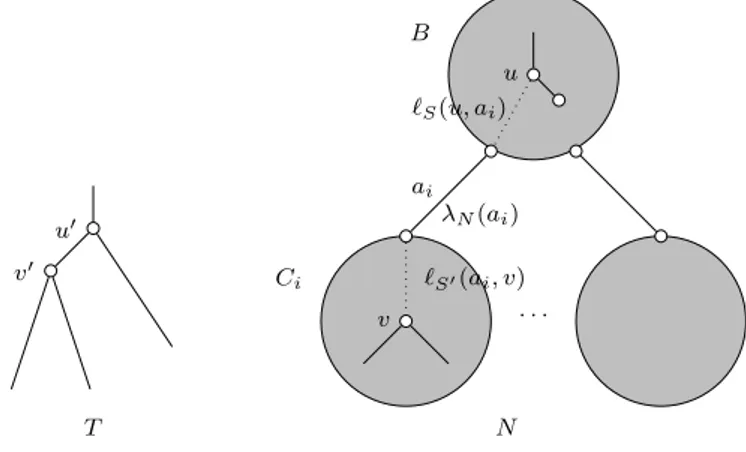
Figure

Documents relatifs
This provides a simple means of using the TRAP-TYPE macro to represent the existing standard SNMP traps; it is not intended to provide a means to define additional standard
These criteria assume that an organization which meets this profile will continue to grow and that assigning a Class B network number to them will permit network growth
The IR or the registry to whom the IR has delegated the registration function will determine the number of Class C network numbers to assign to a network subscriber based on
e) Incompatibilities between overlapping SPD entries and NAT. Where initiating hosts behind a NAT use their source IP addresses in Phase 2 identifiers, they can
Once this constraint is lifted by the deployment of IPv6, and in the absence of a scalable routing strategy, the rapid DFZ RIB size growth problem today can potentially
A third way to build dynamic mappings would be to use the transport mechanism of the routing protocol itself to advertise symbolic names in IS-IS link-state PDUs.. This
In particular, bundles including the optional metadata block would be protected in their entirety for the duration of a single hop, from a forwarding node to an
Potential action items for the W3C included investigating the formation of a privacy interest group and formulating guidance about fingerprinting, referrer headers,
