Change-centric improvement of team collaboration
249
0
0
Texte intégral
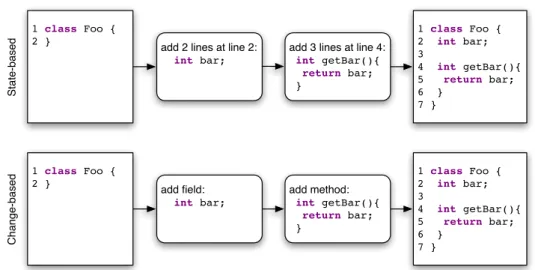
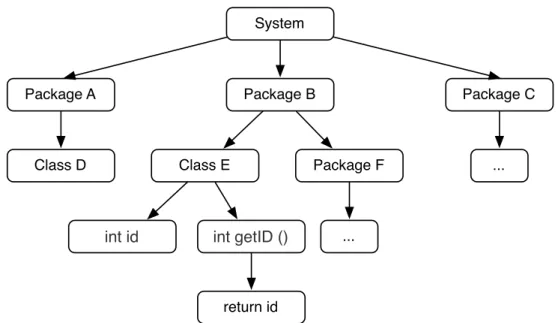
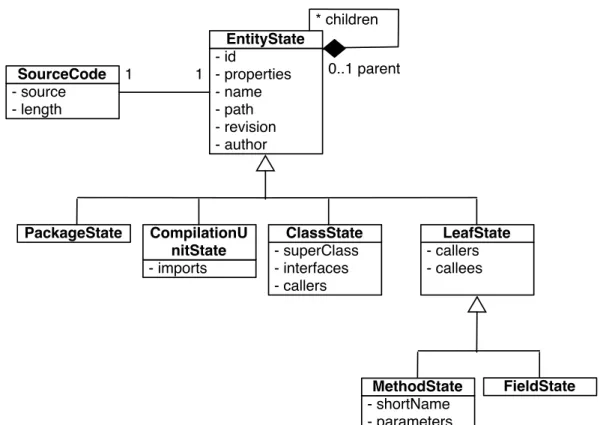
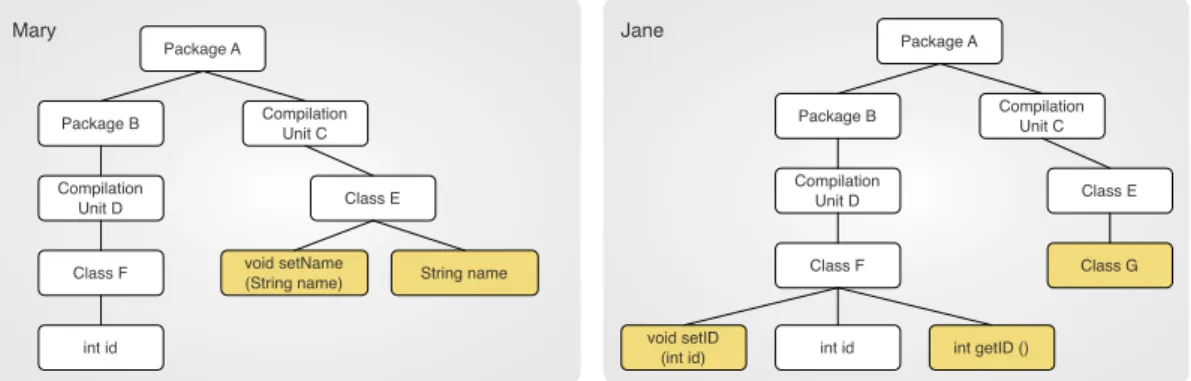
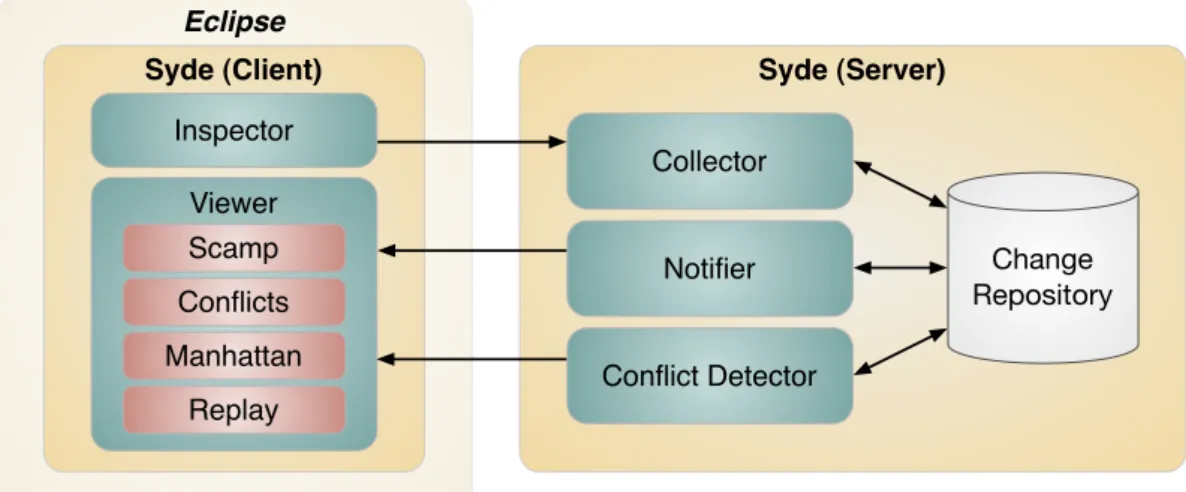
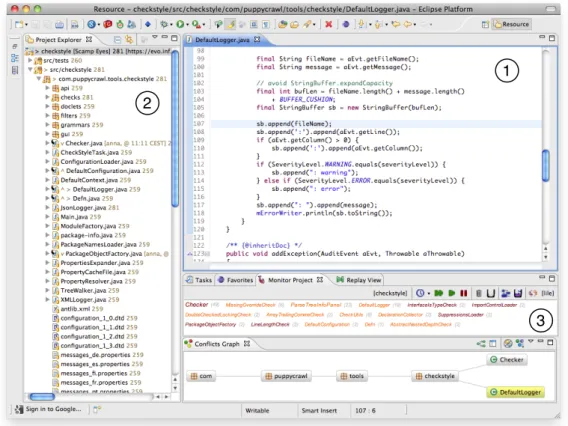
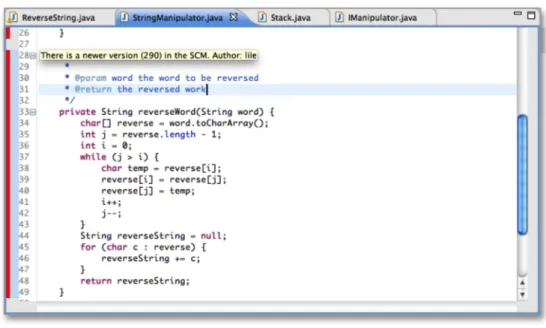
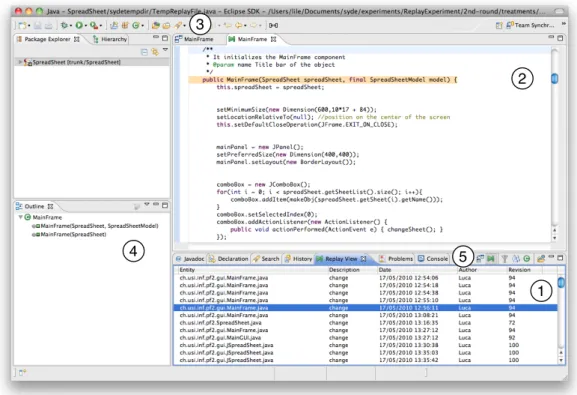
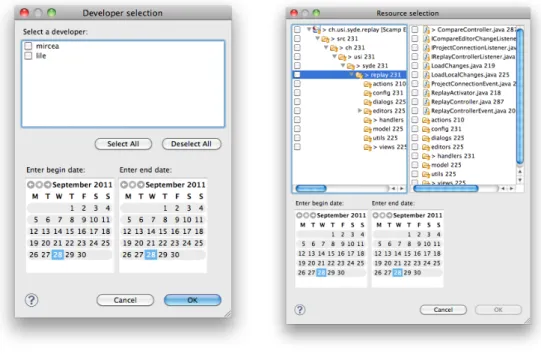
Figure
+7
Documents relatifs