Énergie, Matériaux et Télécommunications (EMT)
MÉCANISME DE PROTECTION RAPIDE POUR UN RÉSEAU ETHERNET DE CLASSE OPÉRATEUR CONTRÔLÉ PAR LE PROTOCOLE IS-IS
Par
Marcelo Nascimento dos Santos
Mémoire présenté pour l’obtention du grade de Maître es Sciences, M.Sc.
en télécommunications
Jury d’évaluation
Examinateur externe Prof. Brunilde Samsò
École Polytechnique de Montréal
Examinateur interne Prof. Martin Maier
INRS-EMT
Directeur de recherche Prof. Jean-Charles Grégoire INRS-EMT
Depuis sa création, la technologie Ethernet a évolué d’une technologie de réseaux locaux jusqu’à être utilisée dans les réseaux d’accès métropolitain et de transport. Plusieurs mécanismes sont utilisés pour que les nouveaux réseaux Ethernet soient capables d’offrir les caractéristiques d’un réseau de classe opérateur (Carrier-class). Pour le contrôle du réseau, l’utilisation d’un protocole à état de liens (link-state) à la place du Rapid Spanning Tree Protocol (RSTP) est l’une des améliorations utilisées par les nouvelles technologies Ethernet telles que le Provider Link State Bridging (PLSB), le Transparent Interconnection of Lots of Links (TRILL) et le Shortest Path Bridging (SPB); ces technologies utilisent le protocole Intermediate System to Intermediate System (IS-IS) qui était déjà utilisé comme protocole de routage dans les réseaux sans connexion comme IP. Pourtant, pour que ces nouveaux réseaux Ethernet puissent atteindre le niveau de performance d’un réseau de classe opérateur, comme pour les réseaux Time-division Multiplexing (TDM) traditionnels, il faut que de nouveaux mécanismes spécifiquement adaptés à ce genre de réseau soient développés. Le temps de convergence élevé des protocoles de contrôle Ethernet est un des problèmes rencontrés tant dans les réseaux traditionnels que de nouvelle génération. L’objectif de notre recherche est donc la proposition d’un mécanisme de recouvrement capable d’utiliser des chemins alternatifs préconfigurés pour améliorer la vitesse de recouvrement des réseaux Ethernet qui utilisent le protocole IS-IS dans le plan de contrôle. Dans ce mémoire nous présentons une analyse du temps de recouvrement des protocoles de contrôle utilisés dans les réseaux Ethernet. Nous développons aussi un mécanisme de recouvrement rapide pour un réseau Ethernet de classe opérateur contrôlé par un protocole à état de liens. Des simulations sont utilisées pour montrer l’avantage de l’utilisation de ce mécanisme en relation au mécanisme de recouvrement global du protocole IS-IS.
Mots-clés Ethernet, Classe opérateur, Recouvrement Rapide, IS-IS
Ethernet has evolved from a use in local area networks to a technology that can be used in metro access as well as long-haul transport networks. Several mechanisms have been created to adapt the Ethernet control plane to the requirements of a Carrier-class network. The use of a link-state routing protocol rather than the traditional RSTP is one of the improvements employed by technologies such as Transparent Interconnection of Lots of Links (TRILL) and Shortest Path Bridging (SPB) to achieve better and more predictable reliabi-lity levels. These technologies use the IS-IS routing protocol, which has already been employed as a routing protocol in IP networks. Unfortunately even with these improvements, new Ethernet networks still cannot achieve the level of reliability of traditional TDM-derived Carrier-class networks. In order to improve Ether-net reliability and availability performance, we need to develop new, specifically adapted mechanisms. More specifically, the high convergence time of control protocols can cause problems in both traditional and new generation Ethernet networks. The goal of our research is to present a local recovery mechanism capable of using preconfigured alternative paths to improve the speed of recovery. We will also present an analysis of the recovery time of two control protocols used in Ethernet networks, namely RSTP and IS-IS. Our fast recovery mechanism is adapted to a Carrier-class Ethernet network controlled by a link-state protocol. Si-mulations are used to show the advantage of the use of this mechanism in comparison to the global recovery mechanism of link-state protocols.
Keywords Ethernet, Carrier-class, Fast Recovery, IS-IS
Résumé iii
Abstract v
Table des matières vii
Liste des figures ix
Liste des abréviations xi
1 Introduction 1
2 Evolution des technologies Ethernet 5
2.1 Ethernet traditionnel . . . 6
2.2 Ethernet de Classe Opérateur . . . 7
2.2.1 Technologies « Carrier Ethernet » . . . 8
2.3 Les protocoles de gestion de liens . . . 11
2.3.1 Spanning Tree Protocol (STP) . . . 11
2.3.2 RSTP . . . 15
2.3.3 Multiple Spanning Tree Protocol (MSTP) . . . 16
2.4 Protocoles de contrôle dans les réseaux Ethernet de nouvelle génération . . . 17
2.4.1 Le IS-IS . . . 18
2.4.2 Technologies Ethernet basées sur le IS-IS . . . 20
3 La robustesse des réseaux 23 3.1 Les mécanismes de recouvrement . . . 23
3.1.1 Réseaux Synchronous Optical Networking (SONET)/Synchronous Digital Hierar-chy (SDH) . . . 25
3.1.2 Réseaux IP . . . 25
3.1.3 Réseaux Multiprotocol Label Switching (MPLS) . . . 27
3.1.4 Réseaux Ethernet traditionnels . . . 27
3.1.5 Réseaux Ethernet à état de liens . . . 29
3.2 Simulation I - Temps de convergence . . . 30
3.2.1 Méthode d’analyse . . . 31
3.2.2 Tests réalisés . . . 32
3.2.3 Résultats . . . 36
4 Mécanismes de Recouvrement Rapide 41 4.1 Mécanismes de recouvrement rapide . . . 41
4.2.1 Réseaux IP . . . 44
4.2.2 Réseaux Ethernet traditionnels . . . 45
4.2.3 Réseaux Ethernet à état de liens . . . 46
4.3 Planification des réseaux . . . 49
5 Proposition d’un mécanisme de recouvrement rapide 53 5.1 Description du mécanisme . . . 53
5.2 Problèmes . . . 54
5.3 Simulation II - Analyse du mécanisme de recouvrement rapide . . . 60
5.3.1 Méthode d’analyse . . . 62
5.3.2 Le mécanisme de recouvrement rapide . . . 63
5.3.3 Tests réalisés . . . 63
5.3.4 Résultats . . . 65
5.4 Simulation III - Coût du réseau . . . 69
5.4.1 Méthode d’analyse . . . 69 5.4.2 Analyses réalisées . . . 70 5.4.3 Résultats . . . 71 6 Conclusions 75 Annexe A Algorithmes I A.1 Algorithme 1 . . . I A.2 Algorithme 2 . . . III
2.1 Format de trame 802.1D/802.1Q [26] [25] . . . 6
2.2 Format de trame 802.1ad [26] [16] . . . 8
2.3 Format de trame 802.1ah [26] [17] . . . 9
2.4 Construction de la topologie . . . 13
2.5 Topologie MSTP . . . 17
2.6 Topologie MSTP (CST) . . . 17
2.7 Mécanisme d’inondation . . . 20
3.1 Exemple de protection et rétablissement . . . 24
3.2 Exemple de récuperation globale, locale et mixte . . . 24
3.3 Temps de convergence d’une topologie light-mesh [42] . . . 30
3.4 Temps de convergence (en ms) du protocole IS-IS [52] . . . 31
3.5 Les différentes topologies utilisées . . . 32
3.6 La topologie en anneau . . . 33
3.7 La topologie en grille . . . 35
3.8 Temps de convergence de la topologie en anneau . . . 36
3.9 Temps de convergence maximal pour la topologie en grille . . . 37
3.10 Temps de convergence moyen pour la topologie maillée . . . 38
3.11 Nombre moyen de paquets de contrôle par nœud . . . 38
3.12 Nombre de paquets de contrôle total dans le réseau et maximal dans un seul nœud . . . 39
4.1 Exemple des mécanismes Internet Protocol - Fast Reroute (IP-FRR) . . . 43
4.2 Exemple de p-Cycle . . . 44
4.3 Exemple de topologie . . . 46
4.4 Exemple de formation de boucle [64] . . . 47
4.5 Exemple de topologie [64] . . . 48
4.6 Exemple de solutions . . . 50
5.1 Exemple du mécanisme de protection . . . 54
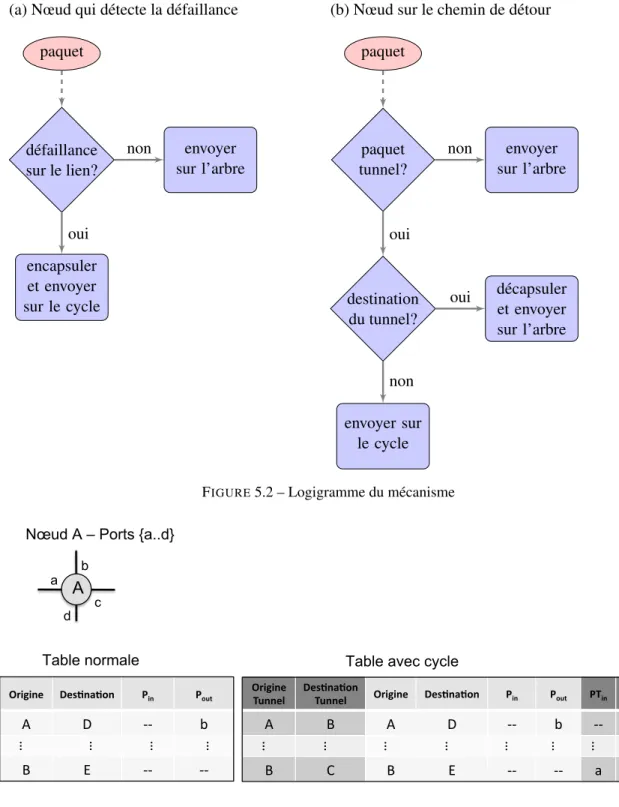
5.2 Logigramme du mécanisme . . . 55
5.3 Exemple de table . . . 55
5.4 Retransmission des paquets . . . 56
5.5 Transmission point-à-point . . . 57
5.6 Transmission point-à-multipoint . . . 58
5.7 Example de table point-à-multipoint . . . 59
5.8 Logigramme du mécanisme pour éviter les flots dupliqués (point-à-point) . . . 60
5.9 Logigramme du mécanisme pour éviter les flots dupliqués (point-à-multipoint) . . . 61
5.10 Construction des tables Tt . . . 62 ix
5.13 Topologie pour la simulation de diffusion . . . 64
5.14 Topologies en grille pour la simulation de diffusion . . . 65
5.15 Nombre de paquets perdus . . . 66
5.16 Nombre de paquets perdus pour host2 et host4 . . . 66
5.17 Corrélation entre le temps de convergence des commutateurs et Tc . . . 67
5.18 Nombre de paquets perdus station 2 et station 4 . . . 67
5.19 Nombre de paquets perdus pour chaque station . . . 68
5.20 Nombre total moyen de paquets perdus . . . 68
5.21 Topologie utilisée pour la simulation . . . 70
5.22 Trafic sur les liens . . . 71
5.23 Coût lineaire . . . 72
5.24 Coût modulaire et taux d’occupation . . . 72
100-GET 100 Gbit/s Carrier-Grade Ethernet Transport Technologies APS Automatic Protection Switching
ATM Asynchronous Transfer Mode
B-VID Backbone VID
BPDU Bridge Protocol Data Units
BRITE Boston university Representative Internet Topology gEnerator CBR Constant Bit Rate
CFM Connectivity Fault Management
CSMA/CD Carrier Sense Multiple Access With Collision Detection CSNP Complete Sequence Number Packet
EAPS Ethernet Automatic Protection Switching ECMP Equal Cost Multipath
ERP Ethernet Ring Protection
ERPS Ethernet Ring Protection Switching
ETNA Ethernet Transport Networks Architectures of Networking FIB Forwarding Information Base
FIB Forwarding Information Base
FRR Fast Reroute
FRR-TP Fast Rerouting-Transport Profile GFP Generic Framing Procedure GFP Generic Framing Procedure IETF Internet Engineering Task Force IGP Interior Gateway Protocol
IIH Intermediate System to Intermediate System Hello IP Internet Protocol
IP-FRR Internet Protocol - Fast Reroute
IS-IS Intermediate System to Intermediate System ISP Internet Service Provider
LAN Local Area Networks
LCAS Link Capacity Adjustment Scheme LSP Label Switched Path
LSPDU Link State Protocol Data Unit
LSPID LSPDU Identifier
MAC Medium Access Control MPLS Multiprotocol Label Switching
MPLS-FRR Multiprotocol Label Switching - Fast Reroute
MSTP Multiple Spanning Tree Protocol
OAM Operations, Administration and Maintenance
OSPF Open Shortest Path First
OTN Optical Transport Network
PB Provider Bridge
PBB Provider Backbone Bridge
PBB-TE Provider Backbone Bridge Traffic Engineering
PLSB Provider Link State Bridging
PSNP Partial Sequence Number Packet
QoS Quality of Service
RBridge Routing Bridge
RCB Root Controlled Bridging
ROM-FRR Optimized Multicast Fast Rerouting
RPF Reverse Path Forwarding
RPFC Reverse Path Forwarding Check
RPR Resilient Packet Ring
RRR Rapid Ring Recovery
RSTP Rapid Spanning Tree Protocol
SDH Synchronous Digital Hierarchy
SLA Service-level Agreement
SONET Synchronous Optical Networking
SPB Shortest Path Bridging
SPF Shortest Path First
STP Spanning Tree Protocol
TCN Topology Change Notification
TDM Time-division Multiplexing
TRILL Transparent Interconnection of Lots of Links
VCAT Virtual Concatenation
VID VLAN Identifier
VLAN Virtual Local Area Networks
Introduction
Traditionnellement, les réseaux de transport étaient basés sur une structure de type TDM; ainsi les ré-seaux SONET/SDH ont été utilisés pendant longtemps comme la principale technologie de transport dans le cœur du réseau. Le principal service sur ces réseaux était le transport de circuits de voix qui utilisaient une hiérarchie TDM [1].
Avec la croissance des applications Internet Protocol (IP) et des services de commutation par paquets tels que l’accès Internet à haut débit, la téléphonie IP et réseaux mobiles, le transport de données devient plus important pour les opérateurs de télécommunications. Cependant les réseaux de transport traditionnels SONET/SDH sont encore utilisés pour offrir le moyen de transport physique à plusieurs technologies de com-mutation de paquets. En principe une technologie TDM n’est pas très efficace pour le transport de données, ainsi des mécanismes d’adaptation comme le Generic Framing Procedure (GFP), Link Capacity Adjustment Scheme (LCAS), Virtual Concatenation (VCAT) et la technologie Optical Transport Network (OTN) ont été développés pour adapter la technologie TDM à la transmission de paquets. L’utilisation d’une technologie de commutation par paquets dans le réseau de transport présente certains avantages par rapport aux réseaux TDM traditionnels à cause du multiplexage statistique [2]; pour cette raison il existe déjà un intérêt à l’uti-liser comme remplacement à technologie SONET/SDH dans les réseaux de transport [3]. Il existe plusieurs technologies qui utilisent le multiplexage statistique, telles que le Asynchronous Transfer Mode (ATM), le IP, le MPLS et la technologie Ethernet qui a reçu beaucoup d’attention à cause de son omni-présence, son coût, sa simplicité et sa haute vitesse [4].
Les réseaux TDM traditionnels présentent des caractéristiques de performance adaptées au transport de services en temps réel. Ainsi historiquement ces réseaux ont été utilisés largement pour le transport des services de téléphonie, et certains standards ont été créés. Avec le développement des technologies qui utilisent le multiplexage statistique pour le transport, il a eu une nécessité d’adapter ces technologies pour qu’elles présentent les mêmes caractéristiques de performance que les réseaux TDM. Dans la littérature le terme « Classe Opérateur » (Carrier-class ou Carrier-grade) est utilisé pour décrire un réseau, équipement ou service avec des propriétés des réseaux de transport des gros opérateurs de télécommunications. La qualité de service (Quality of Service (QoS)), la robustesse, le recouvrement rapide et la gestion de services sont présentés dans [5] comme des propriétés caractéristiques d’un réseau de classe opérateur. Une description objective de ces propriétés n’est pas universellement adoptée, pourtant la haute disponibilité de 99,999% (« cinq neuf ») et un temps de recouvrement de 50 ms est cité dans plusieurs textes comme standard pour les réseaux de classe opérateur [6] [7] [8].
Donc, les réseaux de transport de nouvelle génération doivent avoir certaines caractéristiques spécifiques pour qu’ils puissent offrir des services aux clients avec la qualité désirée et aussi offrir aux opérateurs un réseau de coût réduit en termes d’implémentation et de gestion. La technologie utilisée pour le transport doit disposer de nouveaux mécanismes pour augmenter sa performance [9], ainsi des mécanismes de QoS, d’in-génierie du trafic, de gestion et de recouvrement équivalents à ceux existant dans les réseaux traditionnels, tels que les réseaux SONET/SDH, ont été développés. La création de mécanismes pour doter la nouvelle génération Ethernet de ces attributs présente un défi pour les nouvelles technologies [10] [11]. À travers sa version de classe opérateur, la technologie Ethernet est apparue comme une réelle alternative aux réseaux de transport traditionnels et l’état de l’art de la technologie Ethernet utilisé présentement (telles que les technologies Provider Bridge (PB), Provider Backbone Bridge (PBB), SPB, Provider Backbone Bridge Traf-fic Engineering (PBB-TE), Multiprotocol Label Switching - Transport Profile (MPLS-TP), Resilient Packet Ring (RPR) et Ethernet Ring Protection (ERP) présente des mécanismes qui permettent la création d’un réseau avec plusieurs des attributs désirés pour un réseau de classe opérateur. Dans le domaine de la re-cherche, des projets tels que Ethernet Transport Networks Architectures of Networking (ETNA) [12] et 100 Gbit/s Carrier-Grade Ethernet Transport Technologies (100-GET)[13] sont des exemples d’efforts qui ont été réalisés avec l’objectif de créer un réseau Ethernet de classe opérateur.
La combinaison des développements apportés par certaines nouvelles technologies telles que l’utilisa-tion d’un protocole de routage à état de liens dans le plan de contrôle utilisé par les technologies TRILL et SPB [14] [15], le format de trames utilisés dans les normes IEEE 802.1ad et 802.1ah [16] [17] dans le
plan de données et des mécanismes de gestion du réseau tels que le 802.1ag (Connectivity Fault Manage-ment (CFM))/Y.1731 [18] [19] peuvent apporter une partie des caractéristiques désirées pour un réseau de classe opérateur. Toutefois, pour obtenir un réseau qui combine les avantages des réseaux Ethernet avec la performance des réseaux TDM traditionnels, il est nécessaire également de développer de nouveaux méca-nismes, comme par exemple l’amélioration du temps de convergence du réseau à travers un mécanisme de réacheminement rapide Fast Reroute (FRR).
Les réseaux de transport sont sujets à une série de problèmes qui peuvent causer des interruptions du trafic des utilisateurs si le réseau n’offre pas des mécanismes de recouvrement efficaces. L’augmentation des services de temps réel et l’adoption des contrats de type Service-level Agreement (SLA), qui exigent une meilleure performance du réseau par rapport aux services de données traditionnels, ont augmenté l’in-térêt pour le développement de mécanismes qui puissent éviter les interruptions ou minimiser les problèmes causés par les défaillances. Dans un réseau Ethernet traditionnel, la robustesse du réseau est garantie par le protocole de contrôle et le temps de recouvrement dépend du temps de convergence de ce protocole; ainsi en cas d’une défaillance dans le réseau, le mécanisme de recouvrement doit créer une nouvelle topologie logique sans provoquer l’occurrence de boucles. Cependant, ce mécanisme peut présenter un temps de recouvrement assez élevé; c’est le cas du STP utilisé dans les premières versions de la norme IEEE 802.1D. Pour résoudre le problème du temps de convergence élevé, le RSTP a été créé mais ce protocole n’offre pas un recouvrement rapide au niveau d’un réseau de classe opérateur. Plusieurs solutions adoptées présentement par les techno-logies « Carrier Ethernet » sont similaires aux solutions utilisées dans les réseaux de transport par paquets traditionnels. Ainsi, les technologies PBB-TE et MPLS-TP, qui utilisent des circuits orientés connexion pour l’établissement des chemins dans le réseau, utilisent des mécanismes de protection similaires à ceux utilisés dans les réseaux MPLS et SONET/SDH. Le Internet Engineering Task Force (IETF) a décrit deux méthodes de réacheminement rapide pour la protection du trafic: P2MP Fast Rerouting-Transport Profile (FRR-TP) et Optimized Multicast Fast Rerouting (ROM-FRR). Certaines technologies utilisent une architecture phy-sique en anneau pour garantir un temps de recouvrement rapide. C’est le cas des technologies RPR, Ethernet Ring Protection Switching (ERPS) (ITU-T 8032), Ethernet Automatic Protection Switching (EAPS) et Rapid Ring Recovery (RRR) (proposé par [20]). Pourtant en utilisant une architecture en anneau ces technologies imposent une limite au niveau de la mise à l’échelle du réseau. D’autres solutions comme celles décrites en [21] [22] et [23] utilisent les arbres multiples du protocole MSTP comme alternative en cas de défaillance. Dans le cadre des réseaux Ethernet contrôlés par un protocole à état de liens nous n’avons pas trouvé dans
notre revue de littérature l’existence d’un mécanisme de réacheminement rapide spécifique pour ce type de réseau, et cela a donc été une des motivations pour le développement de ce mécanisme dans notre travail.
Les objectifs de notre recherche sont de:
— Réaliser un état de l’art des technologies dérivées d’Ethernet et identifier les avantages de leur utili-sation pour le transport;
— Examiner les technologies utilisées pour l’Ethernet de nouvelle génération et les mécanismes de recouvrement;
— Analyser l’impact de l’utilisation du protocole IS-IS sur le temps de recouvrement du réseau; — Proposer un mécanisme de recouvrement rapide pour un réseau Ethernet contrôlé par le protocole
IS-IS.
Notre travail est structuré de la façon suivante:
— Chapitre 1: Ce chapitre a décrit l’évolution des technologies de transport et l’importance de la robus-tesse du réseau;
— Chapitre 2: Le deuxième chapitre fait une description des technologies Ethernet traditionnelles et de nouvelle génération, ainsi que des protocoles de contrôle utilisés dans ces réseaux.
— Chapitre 3: Dans ce chapitre, nous présentons une description des mécanismes de recouvrement utilisés dans les réseaux de transport et aussi une analyse du temps de recouvrement des réseaux Ethernet traditionnels et des réseaux contrôlés par un protocole à état de liens.
— Chapitre 4: Dans le quatrième chapitre, nous faisons un survol des mécanismes de recouvrement ra-pide déjà utilisés dans les réseaux IP et du problème de formation de boucles causé par le changement de la topologie physique du réseau.
— Chapitre 5: Dans ce chapitre nous présentons un mécanisme de recouvrement rapide pour les ré-seaux Ethernet contrôlés par un protocole à état de liens et faisons une analyse de performance de ce mécanisme à travers des simulations.
— Chapitre 6: Le sixième chapitre est la conclusion du travail.
À travers l’étude et les analyses présentées, ce travail est une contribution au développement d’un réseaux Ethernet de nouvelle génération. L’utilisation des nouvelles technologies avec le mécanisme de recouvrement rapide proposé permet la création d’un réseau qui possède la robustesse exigée pour les réseaux de transport de classe opérateur.
Evolution des technologies Ethernet
La technologie Ethernet est la plus utilisée dans les réseaux locaux. Son coût et sa simplicité sont des facteurs qui ont fait augmenter sa popularité. Sa capacité d’expansion et d’adaptation sont des éléments es-sentiels pour son utilisation dans différents réseaux et architectures et aujourd’hui elle est employée aussi dans les réseaux métropolitains et étendus. La technologie Ethernet de base est décrite dans la norme IEEE 802.3 (méthode d’accès Carrier Sense Multiple Access With Collision Detection (CSMA/CD) et des spécifi-cations pour la couche physique Ethernet) et dans la norme IEEE 802.1D (architecture pour interconnexion des réseaux locaux en utilisant des « MAC Bridges »). La popularité, la simplicité et le coût des réseaux Ethernet ont fait augmenter l’intérêt pour son utilisation dans les réseaux étendus, ainsi que des mécanismes tels que le Q-in-Q/MAC-in-MAC (IEEE 802.1ad/802.1ah) qui permettent d’améliorer la mise à l’échelle, les mécanismes de Operations, Administration and Maintenance (OAM) IEEE 802.1ag/ ITU-T Y.1731 qui améliorent la robustesse du réseau et les mécanismes de synchronisation (IEEE 1588 et ITU-T Synchronous Ethernet - SyncE) qui permettent la distribution d’une horloge de référence à travers le réseau. Au niveau des protocoles de contrôle, le RSTP est le protocole de contrôle le plus utilisé dans les réseaux Ethernet traditionnels. Pourtant il existe d’autres solutions utilisées pour le contrôle des réseaux de nouvelle généra-tion. Le protocole IS-IS est un exemple. Dans les prochaines sections nous présentons une description des technologies Ethernet et des protocoles utilisés dans le plan de contrôle. À la fin du chapitre nous faisons une analyse du temps de recouvrement des protocoles RSTP et IS-IS dans différentes topologies de réseau.
2.1
Ethernet traditionnel
La norme IEEE 802.1D spécifie l’opération des commutateurs Medium Access Control (MAC) utilisés pour l’interconnexion de réseaux locaux [24]. Un commutateur réseau permet la séparation des domaines de collision où chaque port correspond à un domaine de collision unique. Dans cette norme est aussi défini le protocole STP, conçu pour résoudre les problèmes causés quand les réseaux locaux utilisent des connections redondantes. La norme IEEE 802.1Q spécifie l’opération de commutateurs qui supportent les réseaux locaux virtuels (Virtual Local Area Networks (VLAN)s) [25]. Selon la norme IEEE 802.1D, dans un réseau connecté par des commutateurs on a un seul domaine de diffusion (broadcast), et ainsi tous les éléments du réseau reçoivent les datagrammes transmis. Un VLAN est un groupe de segments logiques Ethernet qui partagent le même réseau physique, et dont les équipements (stations) dans chaque groupe peuvent communiquer comme si elles opéraient dans un réseau privé. On peut ainsi définir un VLAN pour un certain groupe d’équipements et ce groupe aura son propre domaine de diffusion. Pour établir l’appartenance des équipements à un VLAN spécifique, on peut déterminer les ports du commutateur ou les adresses MAC qui font partie du groupe. Les commutateurs ajoutent une étiquette à l’entête de la trame Ethernet pour identifier les différents réseaux virtuels. Pour la définition des classes de service dans une trame Ethernet 3 bits de l’étiquette VLAN 802.1Q (code de priorité) sont utilisés; de cette façon on peut avoir jusqu’à 8 classes de service avec des priorités de trafic différentes. La figure 2.1 montre les formats des trames 802.1D et 802.1Q.
DA SA DA SA VLAN Identifier PCP CF I VLAN TAG (81-00) TPID TCI Tag 4 Octets Bits 6 6 46-1500 Data T/L FCS SA T/L FCS 2 4 Octets 16 3 1 12 DA – Adresse de la destination SA – Adresse de la source T/L – Type\Longueur Data – Données du client FCS – Séquence de vérification de trame 802.1D 802.1Q TPID – Identificateur du protocole d’étiquette
TCI – Information de contrôle
d’étiquette
VLAN TAG – Étiquette VLAN PCP – Code de priorité CFI – Identificateur de format
canonique
VLAN Identifier –
Identificateur de VLAN
2.2
Ethernet de Classe Opérateur
Pour que la technologie Ethernet continue à évoluer et puisse être adoptée comme technologie de trans-port, elle doit être capable d’offrir les caractéristiques d’un réseau de classe opérateur. Le Metro Ether-net Forum (MEF) définit le « Carrier EtherEther-net » comme « un service omniprésent de classe opérateur, normalisé et caractérisé par les cinq attributs qui le différencient de l’Ethernet basée sur Local Area Net-works (LAN)s » [27]. Les cinq attributs définis par le MEF pour le « Carrier Ethernet » sont les suivants:
— Services normalisés; — Mise à l’échelle; — Fiabilité;
— Qualité du Service (QoS); — Gestion des services.
Dans la définition du MEF, le « Carrier Ethernet » est un service de transport de trames Ethernet avec les attributs cités, en permettant la création d’un réseau Ethernet étendu. Pourtant, dans cette définition, la technologie utilisée pour le transport des trames Ethernet n’est pas forcément celle définie par les normes de la famille IEEE 802.1/802.3 puisque les services de transport de trames Ethernet peuvent utiliser aussi des technologies de transport à longue portée.
Du point de vue de l’Ethernet normalisé par le IEEE le développement des technologies « Carrier Ether-net » comme technologie de transport a été fait progressivement à partir des technologies déjà existantes, d’abord pour son utilisation dans l’accès et agrégation et plus récemment pour le cœur du réseau de trans-port. Une série de normes ont été créées pour ajouter des mécanismes qui permettent son utilisation dans les réseaux de transport. Cela rend possible l’utilisation du mécanisme de création de classes de service et de ré-seaux virtuels de la norme IEEE 802.1Q, pour offrir la QoS ainsi que différents VLANs dans le réseau. Aussi, les mécanismes « Q-in-Q » et « MAC-in-MAC », les technologies 802.1ad (Provider Bridges) et 802.1ah (Provider Backbone Bridges) améliorent la mise à l’échelle et facilitent la gestion des services. Pourtant, bien que ces technologies fassent partie de la famille « Carrier Ethernet », elles ne possèdent pas tous les at-tributs définis par le MEF. Particulièrement, concernant les atat-tributs de fiabilité et gestion de services, le plan de contrôle n’est pas encadré dans les normes qui décrivent ces technologies. Dans la suite, nous présentons une brève description des technologies « Carrier Ethernet » les plus populaires.
2.2.1 Technologies « Carrier Ethernet »
IEEE 802.1ad (PB)
La norme IEEE 802.1ad est un document modificatif de la norme IEEE 802.1Q. Le PB modifie le format de trame de base pour créer une séparation entre les domaines de VLAN des clients et du fournisseur de service. Dans la norme IEEE 802.1Q l’étiquette est un champ de 4 octets qui contient 12 bits pour identifier les différents VLANs (VLAN ID), permettant ainsi la création de 4096 instances (dont 4094 utilisables). Du point de vue du fournisseur ce nombre est limité, pas seulement à cause du nombre de VLANs possibles mais aussi parce que différents clients qui utilisent déjà un réseau 802.1Q ne peuvent pas utiliser les mêmes VLAN IDs. Dans le PB les VLANs du réseau administré par le client reçoivent le nom de Customer VLANs (C-VLAN) et celles du réseau administré par le fournisseur sont les Service VLANs (S-VLANs). Le domaine de service est créé à travers l’ajout d’un nouveau champ dans la trame, le Service TAG (S-TAG). Dans le S-TAG il existe un champ de 12 bits pour la définition des S-VLANs du domaine de fournisseur de services. Pourtant le mécanisme d’apprentissage des commutateurs fait que dans un réseau PB, toutes les adresses MAC des clients doivent être connues par le réseau du fournisseur. Cela pose un problème de mise à l’échelle et également de sécurité puisqu’un client peut envoyer un nombre illimité d’adresses vers le réseau de service, ce qui peut provoquer l’épuisement des tables et l’augmentation des diffusions de trames dans le réseau. La figure 2.2 montre les formats des trames 802.1ad.
DA SA
DA SA
VLAN Identifier PCP DEI
S-VLAN TAG (88-a8)
TPID S-Tag TCI S-Tag 4 Octets Bits 6 6 46-1500 Data T/L FCS 2 4 Octets 16 3 1 12 DA – Adresse de la destination SA – Adresse de la source T/L – Type\Longueur Data – Données du client
FCS – Séquence de vérification de trame
802.1Q
802.1ad
C-Tag – Étiquete de client
TPID – Identificateur du protocole d’étiquette S-Tag TCI – Information de contrôle d’étiquette
de service
S-VLAN TAG – Étiquette VLAN de Service PCP – Code de priorité
DEI – Admissibilité d’écart
VLAN Identifier – Identificateur de VLAN
Tag
4
C-Tag T/L Data FCS
IEEE 802.1ah (PBB)
La norme IEEE 802.1ah modifie la norme IEEE 802.1Q de façon à résoudre le problème de mise à l’échelle existant dans le PB. Ainsi le PBB spécifie un nouveau champ nommé Backbone Service Instance tag (I-TAG) qui encapsule les adresses du client et un nouveau champ de 24 bits, le Backbone Service Instance Identifier (I-SID) qui crée des instances de service. Un champ Backbone VLAN tag (B-TAG) est aussi défini; ce champ joue le rôle du S-TAG des réseaux PB. Dans un réseau PBB, il existe une séparation entre les domaines d’adresses du client et du fournisseur, et ainsi les champs B-SA et B-DA représentent les adresses MAC utilisées dans le réseau du fournisseur de transport et les champs C-SA et C-DA représentent les adresses du client. La figure 2.1 montre les formats des trames 802.1ah.
C-DA C-SA C-DA C-SA I-PCP I-D EI BS-ITAG (88-e7)
I-Tag TPID I-Tag TCI/SID S-Tag 4 Bits 6 6 46-1500 Data T/L FCS 2 4 Octets 16 3 1 24
C-DA – Adresse de la destination du client C-SA – Adresse de la source du client T/L – Type/Longueur
Data – Données du client
FCS – Séquence de vérification de trame PCP – Code de priorité
TPID – Identificateur du protocole d’étiquette DEI – Admissibilité d’écart
VLAN Identifier – Identificateur de VLAN
802.1ad
802.1ah
B-DA – Adresse de la destination du réseau B-SA – Adresse de la source du réseau B-Tag – Étiquette VLAN du réseau I-Tag – Étiquette d’instance
TPID – Identificateur du protocole d’étiquette TCI – Information de contrôle d’étiquette SID – Identificateur du service
BS-ITAG – Étiquette d’instance de service de réseau I-PCP – Code de priorité d’instance
I-DEI – Admissibilité d’écart d’instance
C-Tag 4 C-Tag T/L Data FCS S-Tag U C A R ES1 R ES2 I-SID B-DA B-SA 1 2 1 B-Tag I-Tag VLAN Identifier PCP DEI
VLAN TAG (88-a8)
B-Tag TPID B-Tag TCI
16 3 1 12
TPID/TCI/SID
6
6 4 6
FIGURE2.3 – Format de trame 802.1ah [26] [17]
Les normes PB et PBB représentent une évolution en termes de mise à l’échelle et de gestion des services, mais pas en termes de fiabilité conforme aux standards des réseaux de transport traditionnels puisque ces technologies n’impliquent pas de mécanismes de contrôle améliorés par rapport à ceux utilisés dans les LANs. Dans un réseau PB/PBB l’utilisation du RSTP/MSTP dans le plan de contrôle et les mécanismes de diffusion et apprentissage des commutateurs posent des problèmes pour la performance du réseau [28]. De nouvelles solutions telles que les protocoles TRILL (proposé par le IETF) et le SPB (proposé dans la norme IEEE 802.1aq) offrent une solution à certains problèmes en utilisant le protocole IS-IS pour la construction de la topologie logique du réseau. Pourtant, le mécanisme de recouvrement du protocole IS-IS ne garantit
pas un temps de recouvrement idéal conforme aux standards des réseaux de transport de nouvelle génération (< 50 ms) [6]. D’autres technologies telles que le Resilient Packet Ring (RPR) défini dans la norme IEEE 802.17 et le Ethernet Ring Protection (ERP) défini dans la norme ITU-T G.8032, peuvent être utilisées pour offrir une garantie de recouvrement attendue, mais cependant ces technologies imposent l’adoption d’une topologie en anneau et une limitation du nombre de nœuds dans le réseau [29].
Dans le cœur des réseaux « Carrier Ethernet », le mécanisme de commutation de circuits virtuels est normalement proposé comme solution pour garantir la QoS et la fiabilité. Ce mécanisme offre une approche semblable à celle utilisée par la commutation de circuits traditionnelle, où les services sont offerts à travers la construction de circuits point à point. Présentement les deux technologies qui utilisent ce mécanisme sont: le MPLS-TP et le PBB-TE [30].
MPLS-TP
Le MPLS-TP utilise quelques éléments de la technologie MPLS comme base pour créer un réseau avec les caractéristiques Carrier [31]. L’utilisation des trames MPLS dans le plan de données permet que la commu-tation et le transport des services s’accomplisse de la même façon que dans les réseaux MPLS traditionnels. Les mécanismes de d’exploitation, de gestion et de maintenance (OAM) du MPLS et d’autres extensions sont aussi utilisés; ces mécanismes possèdent des fonctionnalités similaires à celles du SONET/SDH. Des trames OAMsont utilisées pour la surveillance du réseau à plusieurs niveaux. La garantie de la QoS et l’ingénierie du trafic sont faites à travers l’utilisation des circuits virtuels orientés connexion, et des mécanismes tels que le contrôle d’admission (CAC) et « DiffServ » peuvent être appliqués. Les mécanismes de protection sont aussi définis pour offrir des services similaires aux mécanismes utilisés par le SDH et ainsi garantir le temps de recouvrement maximal de 50 ms (MPLS Fast Re-route-FRR).
PBB-TE
La technologie Provider Backbone Bridges - PBB-TE (802.1Qay) est une évolution de la famille IEEE 802.1; elle est dérivée du PBB et utilise le même format de trame spécifié par la norme IEEE 802.1ah dans le plan de données, ce qui permet l’isolation des plans du client et du réseau en ce qui concerne l’utilisation des VLANs et des identificateurs MAC. Tout comme le MPLS-TP, le PBB-TE utilise des circuits virtuels orientés connexion pour garantir la QoS et aussi pour faciliter l’ingénierie du trafic [32]. Le mécanisme de
OAMest défini par les normes ITU-T Y.1731 et IEEE 802.1ag, qui présentent une série de fonctions pour la surveillance des fautes et mesure de performance. Les normes ITU-T G.803/G.8032 peuvent être utilisées comme mécanisme de protection.
2.3
Les protocoles de gestion de liens
Le STP, le RSTP et le MSTP sont les protocoles de gestion de liens des réseaux Ethernet traditionnels. Le STP, conçu en 1985 par Radia Perlman, a pour objectif principal de permettre la connectivité dans un réseau Ethernet interconnecté par commutateurs à travers la création d’une topologie logique en arborescence. Le protocole/algorithme STP construit un chemin logique unique entre les stations éliminant l’occurrence de boucles [24]. Bien que l’algorithme STP soit capable de construire cette topologie et d’éviter les boucles, son temps de convergence est trop élevé (pouvant atteindre jusqu’à 50s) [33]. Pour solutionner ce problème, le protocole RSTP a été développé; ce protocole est défini dans la norme IEEE 802.1D pour les réseaux Ethernet [24]. En théorie le RSTP peut avoir un temps de convergence de quelques millisecondes, mais ce temps est très variable et dépend de la topologie adoptée. Dans certains cas (comme par exemple une défaillance du commutateur racine « Root Bridge ») il peut même atteindre l’ordre de quelques secondes [34]. Le MSTP est une extension du RSTP utilisé pour améliorer la performance du réseau à travers la création de multiples instances de contrôle pour les différentes VLANs. Dans cette section nous décrivons le fonctionnement de ces protocoles.
2.3.1 STP
Pour construire la topologie active sans boucle, le STP établit différents états de ports. Dans chaque com-mutateur les ports qui participeront à la transmission et à la réception des trames sont en état de transmission (Forwarding State) et les ports qui ne font pas partie de cette topologie logique restent bloqués (Blocking State). On choisit également un commutateur racine parmi les commutateurs du réseau. La topologie logique du réseau ainsi construit fonctionne de façon à ce que chaque LAN dans le réseau ait un chemin unique vers le commutateur racine à travers un port désigné (Designated Port) qui fait partie d’un commutateur désigné Designated Bridgeauquel le LAN est connecté.
Pour définir la topologie et choisir le rôle de chaque élément, le protocole utilise des identificateurs pour les commutateurs (Bridges) et ports. Chaque commutateur possède un identificateur Bridge Identifier
(BridgeID) qui lui est associé. Le BridgeID est composé d’un identificateur de priorité (Bridge Identifier Priority) modifiable et d’une addresse (Bridge Address), l’adresse MAC unique du commutateur qui peut être l’adresse d’un de ses ports (dans la norme l’utilisation de l’adresse la plus basse est recommandée). Les ports possèdent une valeur de coût de chemin vers le commutateur racine (Root Path Cost), un coût de chemin (Path Cost) avec des valeurs defauts selon la capacité du lien, et un identificateur Port Identifier. Dans le réseau, le commutateur avec le meilleur BridgeID (valeur numérique la plus basse) est choisi comme commutateur racine. Le Root Path Cost associé à chaque port est défini comme l’addition des valeurs du Path Costde chaque port dans le chemin avec le coût minimal jusqu’au commutateur racine. Pour chaque LAN, le Designated Port est défini comme le port avec la valeur du Root Path Cost la plus basse; dans le cas de deux ports avec le même coût, le Bridge Identifier et le Port Identifier sont utilisés pour les départager. La transmission des informations sur la topologie est faite à travers la transmission de trames appelées Bridge Protocol Data Units (BPDU)entre les commutateurs; l’algorithme Spanning Tree utilise des informations transportées pour définir le rôle et l’état des ports du commutateur. La figure 2.4 montre un exemple de topologie avec 3 commutateurs dont le commutateur 1 est le commutateur racine. Le calcul de la topologie active est fait de la façon suivante:
— Chaque commutateur, au début de sa routine, prend le rôle de commutateur racine et génère des « messages de configuration » (Configuration BPDUs). Les BPDUs sont transmis dans un intervalle fixe (Hello Time) et portent les valeurs de Root Identifier, du Root Path Cost et de la priorité du commutateur et des ports. À ce moment tous les ports du commutateur racine sont des Designated Ports(port qui connecte le LAN au commutateur racine). La figure 2.4(a) montre cette étape. — La priorité relative de chaque commutateur par rapport aux autres est calculée à partir de la
compa-raison entre les valeurs du commutateur et les valeurs reçues à travers les BPDUs. Un commutateur qui reçoit une BPDU avec une information de priorité relative supérieure (valeur numérique plus basse) retransmet cette information aux autres LANs. Dans la figure 2.4(b) les commutateurs 2 et 3 considèrent l’information transmise par 1 comme de priorité supérieure.
— Un commutateur qui reçoit une information inférieure dans un port considéré comme Designated Portrépond avec des BPDUs qui portent leurs propres informations (informations de priorité relative supérieure). Dans la figure 2.4(b) le commutateur 1 retransmet ses BPDUs après la réception des BPDUs des commutateurs 2 et 3.
— Si la topologie physique est stable, à la fin de la convergence du protocole le réseau possède un seul commutateur racine, et chacun des autres commutateurs possèdent un seul port racine (Root Port)
qui offre un chemin unique vers le commutateur racine aux LANs attachés à ses Designated Ports. La figure 2.4(b) montre les états des ports à la fin de la procédure et la figure 2.4(c) la topologie logique finale. 1 3 2 1 3 2 Je suis le « Root »! Je suis le « Root »! Je suis le « Root »! 1 est le « Root »! Je suis le « Root »! Commutateur port racine port désigné port bloqué Commutateur Root
Topologie logique
T = 0
T = t
FIGURE2.4 – Construction de la topologie
Chaque port possède aussi un état d’opération (Port State) qui règle la transmission des trames et le mécanisme d’apprentissage d’adresses (learning). La topologie active est composée des ports dans l’état Forwarding, ces ports transmettent et reçoivent les trames et réalisent l’apprentissage. Les ports qui ne parti-cipent pas à la topologie active sont dans l’état Blocking. L’algorithme peut changer les états des ports dans le cas de modification de la topologie physique du réseau. Ainsi un port peut passer de l’état Forwarding à l’état Blocking et vice versa. Pour passer de l’état Blocking à l’état Forwarding, les ports doivent passer par deux états intermédiaires, soit Listening et Learning. Ce mécanisme est utilisé pour éviter l’occurrence de boucles pendant la période de convergence. Un administrateur peut attribuer aussi l’état Disabled à un port pour qu’il ne participe pas à la topologie.
Les trames BPDU utilisent une identification de groupe MAC spéciale (01:80:C2:00:00:00) comme des-tination. Elles peuvent transporter des messages de configuration et de changement de topologie. Pour sé-lectionner le commutateur racine et le meilleur chemin les commutateurs échangent des informations dans
les messages de configuration (Configuration Messages). Les informations échangées reçoivent le nom de vecteurs de priorité (priority vectors) composés par:
— Root Bridge Identifier — Root Path Cost — Bridge Identifier
— Port Identifier du port à travers lequel le message a été transmis — Port Identifier du port à travers lequel le message a été reçu
Ces informations sont utilisées par l’algorithme dans chaque commutateur pour choisir le meilleur mes-sage parmi tous les mesmes-sages reçus et définir les états des ports, ce qui va définir la topologie du réseau.
Dans un réseau qui utilise le STP seulement, le commutateur racine transmet des BPDUs, les autres renvoient seulement les BPDUs reçus (après la modification de quelques informations champs spécifiques). Le Router Bridge transmet des BPDUs à travers ses Designated ports dans un intervalle fixe configuré dans le commutateur par le variable Hello Time (2s par défaut).
Il existe aussi deux autres types de BPDUs: — Topology Change Notification (TCN)
— Topology Change Notification Acknowledgment
Ces BPDUs sont utilisées dans les cas de changement de la topologie physique du réseau.
S’il survient un problème dans un lien ou commutateur, le STP réagit à travers les mécanismes pour recalculer la topologie à travers la procédure suivante:
— Les BPDUs de configuration (Configuration BPDUs) possèdent un temps de vie limité Message Age qui est transmis avec le message et est incrémenté a chaque saut; après sa réception le temps en secondes de stockage de l’information est aussi compté. Si le temps de vie est écoulé pour un message reçu dans un Root port cela signifie que le commutateur a perdu son chemin vers le commutateur racine et doit chercher un nouveau chemin ou devenir le commutateur racine. Le temps d’expiration est configuré pour le commutateur à travers la variable Max Age (20s par défaut).
— Si un port dans l’état Blocking doit passer à l’état Forwarding, il doit attendre un certain temps pour que tous les autres commutateurs reçoivent l’information actualisée; ce temps entre les états
Listening et Learning est configuré dans le commutateur en utilisant le paramètre Forward Delay (15s par défaut).
Un commutateur avec une configuration par défaut pour les paramètres Max Age et Forward Delay doit attendre un temps total maximal de T = 2 × Forward Delay + Max Age = 50s et un temps minimal de T = 2 × Forward Delay = 30s pour s’adapter à la nouvelle topologie (cette variation est causée par l’attente d’expiration du temps de vie d’un message).
Le mécanisme d’apprentissage utilisé par les commutateurs permet que les informations sur la locali-sation des stations soient stockées dans les tables d’adresses et ainsi d’éviter la diffusion des trames. Dans l’opération normale du réseau il n’y a pas de changements fréquents de localisation et les tables utilisent un temps d’expiration relativement long pour retenir ces informations.
2.3.2 RSTP
Comme pour le STP, le RSTP configure l’état des ports de chaque commutateur et établit une connectivité stable entre les LANs individuels attachés, tout en assurant une topologie logique libre de boucles. Le RSTP a été conçu pour éliminer le problème du temps de convergence élevé du protocole STP. La norme établit que la topologie active doit se stabiliser dans une courte période de temps (non spécifié), en diminuant le temps dans lequel le service est indisponible. Pour réaliser cette tâche, des modifications à l’opération du STP ont été faites avec l’addition de nouveaux mécanismes. Le mécanisme utilisé par le RSTP fonctionne de la façon suivante:
— Si un commutateur cesse de recevoir des BPDUs, il attend un intervalle de 3 Hello Time pour dé-terminer que le port a perdu la communication. Si le commutateur perd sa communication avec le commutateur racine il doit chercher un nouveau chemin à travers son Alternate Port ou, si le chemin est inexistant, il va lui-même devenir le commutateur racine.
— Un port dans l’état Discarding peut passer à l’état Forwarding immédiatement, dans le cas d’un Alternate Portqui devient un Root Port après que l’ancien soit passé à l’état Disabled ou est devenu un Alternate Port.
— Un Designated Port qui n’est pas dans l’état Forwarding peut proposer la transition d’état à son port correspondant dans le commutateur voisin; la transition est faite immédiatement après la réception d’un message d’accord.
Le mécanisme de calcul de la topologie dans le RSTP n’a pas été modifié par rapport au STP, ainsi le choix du commutateur racine, des Root Ports et Designated ports est fait de la même façon. Pourtant, dans le RSTP, il existe deux nouveaux rôles pour les ports:
— Alternate Port - offre un chemin alternatif vers le commutateur racine;
— Backup Port - offre un chemin alternatif au chemin offert par un Designated Port attaché à un même LAN.
Dans le fonctionnement normal d’un réseau avec une topologie logique stabilisée, ces ports restent blo-qués; dans ce cas ils sont dans l’état Discarding.
Contrairement au STP, où seulement le commutateur racine crée des BPDUs, dans le RSTP tous les commutateurs transmettent des BPDUs à chaque intervalle Hello Time et aussi dans le cas de changement de l’information transportée. Pourtant, il existe une limite à la quantité de BPDUs transmises par seconde. Cette limite est configurée à travers le paramètre Transmit Hold Count (6s par défaut). Le temps de convergence du RSTP peut arriver à quelques centaines de millisecondes en fonction des conditions du réseau [33].
2.3.3 MSTP
Le MSTP est défini dans la norme IEEE 802.1Q. Ce protocole/algorithme permet aux trames qui appar-tiennent à différents VLANs de suivre différents chemins dans le réseau. Le protocole est compatible avec le STP et le RSTP, donc un réseau peut avoir des commutateurs qui communiquent au moyen de ces différents protocoles. Un réseau MSTP peut être constitué de plusieurs régions. Dans chaque région les trames pos-sédant des VLAN Identifier (VID) spécifiques sont attribuées à une Multiple Spanning Tree Instance (MSTI) indépendante qui utilise l’algorithme spanning tree pour le calcul de la topologie active de ces VLANs. Dans une région MSTP chaque MSTI utilise des paramètres internes (Regional Root Identifier, Internal Root Path Cost, Internal Port Path Cost) pour construire son arbre. Les différentes régions peuvent être interconnectées et peuvent aussi connecter des commutateurs qui utilisent le STP/RSTP; le MSTP voit ce réseau comme une seule instance qui s’appelle Common and Internal Spanning Tree (CIST) composé de tous les commuta-teurs du réseau. Le commutateur CIST Root est élu parmi tous les commutacommuta-teurs et est celui qui possède la meilleure valeur BridgeID. Dans chaque région interconnectée il existe un ou plusieurs commutateurs de bordure qui connecte les régions. Celui qui possède le meilleur chemin vers la racine CIST est élu comme le CIST Regional Root. Le meilleur chemin est calculé en utilisant le External Root Path Cost. Le Common
Spanning Tree est un arbre qui connecte toutes les régions et commutateurs qui n’utilisent pas le MSTP; cet arbre voit chaque région comme si elle était un seul commutateur. Les figures 2.5 et 2.6 montrent un diagramme des topologies physiques et logiques d’un réseau MSTP composé de plusieurs régions.
1 2 3 4 11 8 10 12 13 9 5 6 7 1 2 3 4 11 8 10 12 13 9 5 6 7 Région 1 Région 2 Région 3 Région 4 Commutateur « CIST Root » Commutateur « Regional Root »
Topologie physique Topologie logique CIST
FIGURE2.5 – Topologie MSTP 4 11 12 13 Région 3 Région 4 Région 1 Région 2 1 2 3 MSTI1 1 2 3 MSTI2 1 2 3 MSTI3 RÉGION 1 Commutateur « MSTI Root » Topologie logique CST FIGURE2.6 – Topologie MSTP (CST)
2.4
Protocoles de contrôle dans les réseaux Ethernet de nouvelle génération
Les nouvelles technologies Ethernet ont apporté plusieurs innovations pour améliorer la performance du protocole originel. Au niveau du plan de données l’utilisation d’identifiants de VLANs spécifiques dans
le réseau de l’opérateur (« Q-in-Q ») est décrite dans IEEE 802.1ad, l’isolation du réseau du client et de l’opérateur est aussi complétée par l’utilisation d’un espace d’adresses MAC diffèrent (« MAC in MAC »), le mécanisme utilisé par le IEEE 802.1.ah. Pourtant, ainsi que les réseaux Ethernet traditionnels qui utilisent le RSTP/MSTP, ces technologies n’apportent pas de changements dans le plan de contrôle. Les limites d’utili-sation des liens sont un problème des protocoles STP/RSTP, où le mécanisme de blocage des ports pour la construction des arbres est un limitant pour l’utilisation de toute la capacité du réseau. Pour contourner ce problème il existe des solutions telles que l’utilisation du MSTP. Ce protocole permet en effet l’utilisation de VLANs pour distribuer le trafic entre plusieurs arbres qui ont comme racine différents commutateurs, ainsi les points de concentration du trafic de chaque VLAN peuvent être utilisés comme racine. Le MSTP a été proposé comme protocole de contrôle de la technologie SPB; dans cette solution chaque commutateur du réseau possède une MSTI et fonctionne comme commutateur racine [35]. Le protocole Per-VLAN Spanning Tree(PVST) est une solution propriétaire de Cisco qui utilise aussi ce mécanisme. Le protocole Viking utilise une approche similaire et il est proposé en [23] comme une solution aux problèmes d’ingénierie du trafic. Pourtant le mécanisme de recouvrement du MSTP est le même que celui du RSTP, et chaque instance du MSTPfonctionne comme un mécanisme RSTP indépendant pour la construction de la nouvelle topologie. Contrairement à ces technologies, le PLSB, TRILL et SPB utilisent le protocole IS-IS dans le plan de contrôle pour la construction de la topologie logique en arborescence. Le SPB est spécifié dans une modification à la norme IEEE 802.1Q et utilise le protocole IS-IS avec des extensions (IS-IS-SPB) pour la construction des Shortest Path Trees (SPT). Les SPTs construits dans chaque commutateur SPB possèdent les chemins les plus courts vers les autres commutateurs du réseau et ce chemin est utilisé dans les deux directions. Le SPB possède un mécanisme pour briser l’égalité entre des chemins calculés par l’algorithme; de cette façon le meilleur chemin calculé par deux commutateurs sera toujours le même. Comme mesure de prévention des boucles, les tables de routage ne sont peuplées que quand le nœud est synchronisé avec le prochain saut, le mécanisme assurant que la trame sera renvoyée seulement si le voisin est prêt pour l’accepter. Le mécanisme de réduction de problèmes provoqués par les boucles utilise le filtrage des trames qui arrivent aux commuta-teurs; et ainsi une vérification est faite pour garantir que la trame suive bien le chemin établi (Source Based Routing).
2.4.1 Le IS-IS
Le protocole IS-IS est un protocole de routage de type état de lien, où chaque nœud du réseau IS-IS calcule les routes en utilisant l’algorithme du plus court chemin à partir des informations reçues de chacun
des autres nœuds. Ce protocole, défini pour la première fois dans la norme ISO 10589 est largement utilisé dans les réseaux IP, notamment dans le coeur du réseau des gros fournisseurs de service Internet [36]. Il s’agit d’un protocole facilement extensible et qui ne dépend pas de l’encapsulation IP puisqu’il se trouve directement au dessus de la couche liaison de données, et donc son utilisation ne se restreint pas aux réseaux IP, ce qui a été un facteur important pour son choix comme protocole de contrôle des technologies TRILL et SPB. L’utilisation de l’IS-IS dans les commutateurs Ethernet pour la construction des arbres de routage offre des avantages par rapport au RSTP, par exemple la meilleur utilisation des ressources et la construction de chemins optimisés entre chaque commutateur du réseau.
Construction de la topologie
Le premier pas pour la construction de la topologie dans un réseau qui utilise le IS-IS est la découverte des voisins à travers la procédure de handshaking qui peut être accomplie en deux ou trois étapes (2-way et 3-way handshake). Deux types de liaisons physiques entre les éléments du réseau peuvent être utilisés: point à point (p2p) et diffusion générale (broadcast). Tous les messages utilisés par le protocole IS-IS utilisent des identificateurs MAC connus (0180:c200:0014 ou 0180:c200:0015), dont les messages Intermediate System to Intermediate System Hello (IIH)sont utilisés pour la découverte des voisins. Ces messages sont identifiés à travers un champ spécifique dans l’entête IS-IS (PDU Type) (les liaisons p2p et broadcast utilisent des PDU Typesdifférentes). Les IIHs sont envoyés à travers l’interface physique par un nœud du réseau (commutateur ou routeur) dans un intervalle de temps régulier et les voisins attendent un temps maximal (Holding Time) pour la réception de ce message; si aucun message n’a été reçu après ce temps le voisin est déclaré « mort ». L’intervalle de temps pour l’envoi des messages IIH est une fraction du Holding Time configuré à travers une constante « Hello multiplier ». Par exemple pour une valeur Holding Time de 30 secondes (valeur typique), si le Hello multiplier est 3 donc l’intervalle d’envoi des messages sera de 10 secondes. Les voisins sont identifiés par une adresse de 6 octets (Source ID) transportée par le message IIH. Après la procédure de handshakinget la découverte des voisins, le réseau est prêt pour l’échange des informations sur la topologie; pour cet échange le IS-IS utilise le Link State Protocol Data Unit (LSPDU) responsable de la distribution de la base de données (les états des liens vers les autres éléments du réseau). A partir des informations reçues il est donc possible de calculer les chemins à travers le réseau. Puisque toutes les informations sont diffusées à travers le réseau, tous les éléments possèdent la même base de données à la fin du processus. Les LSPDUs possèdent un temps de vie maximal et doivent être envoyés régulièrement pour que le réseau maintienne une base de données actualisée. Ils possèdent aussi un numéro de séquence qui est vérifié à la réception et qui
permet de s’assurer que seulement les nouvelles informations soient diffusées. Le IS-IS possède aussi des Protocol Data Units (PDU) pour la synchronisation des bases de données: le Complete Sequence Number Packet (CSNP) (envoyé régulièrement et qui contient une liste des LSPDUs existants dans la base de données) et le Partial Sequence Number Packet (PSNP) (utilisé pour solliciter des LSPDUs ou confirmer sa réception). Pour maintenir une base de données distribuée à travers tout le réseau, les protocoles à état de liens utilisent le mécanisme d’inondation (flooding). Ainsi les LSPDUs sont envoyés à partir du nœud d’origine vers tous leurs voisins et un nœud qui reçoit un LSPDU doit vérifier son identité à travers le LSPDU Identifier (LSPID) (qui identifie l’origine) et le numéro de séquence; dans le cas d’un LSPDU plus jeune ou inexistant dans la base de données locale, il sera installé et rediffusé à travers tous les liens sauf celui par lequel le LSPDU a été reçu. Si le LSPDU est plus ancien ou s’il existe déjà dans la base de données il sera ignoré. La figure 2.7 montre un exemple du fonctionnement du mécanisme d’inondation. Le nœud A envoie un nouveau LSPDU vers ses voisins B et C; E reçoit deux copies de ce même LSPDU, mais seulement une sera acceptée et installée dans sa base de données; il doit donc ignorer celle qui arrive en dernier et renvoyer la première à son voisin G; G reçoit trois copies du même LSPDU, et installe la première reçue dans sa base de données, ce qui termine la diffusion de cet LSPDU à travers le réseau est donc finie.
A E G F C B D LSPDU
FIGURE2.7 – Mécanisme d’inondation
2.4.2 Technologies Ethernet basées sur le IS-IS
Le TRILL
Le protocole TRILL, décrit dans un Internet Draft de l’IETF [37], a été conçu pour contourner les pro-blèmes des protocoles STP tout en conservant les caractéristiques du réseau commuté [14]. Ainsi, il utilise le protocole IS-IS pour construire les tables de commutation qui vont déterminer les chemins entre deux
éléments du réseau. Les commutateurs qui composent ce réseau et implémentent le protocole TRILL sont nommés Routing Bridge (RBridge). Le chemin optimal entre deux éléments du réseau est calculé à travers les informations du protocole à état de liens, les trames sont délivrés selon l’adresse de destination et celles qui ne possèdent pas d’adresse de destination connue sont envoyées à travers le mécanisme de diffusion. Une vérification des trames à l’entrée des commutateurs à travers le mécanisme de Reverse Path Forwar-ding Check (RPFC)permet la prévention des boucles. Pour atténuer les problèmes causés par la formation de boucles temporaires les trames possèdent un champ hop count. À l’entrée du réseau TRILL, le premier RBridge(commutateur d’entrée) encapsule la trame Ethernet avec l’en-tête TRILL qui possède une indication du dernier RBridge (commutateur de sortie). Chaque RBridge reçoit un pseudonyme de 2 octets construit à partir du IS-IS ID; ce pseudonyme est l’indication utilisé dans l’entête TRILL comme indication des RBridges d’entrée et sortie.
LeSPB
Le SPB est spécifié dans une modification à la norme IEEE 802.1Q et utilise le protocole IS-IS avec des extensions (IS-IS-SPB) pour la construction des Shortest Path Trees (SPT) [15]. Les SPTs construits dans chaque commutateur SPB possèdent les chemins les plus courts vers les autres commutateurs du réseau. Ces chemins sont utilisés dans les deux directions. Le SPB possède un mécanisme pour le bris d’égalité entre des chemins calculés par l’algorithme, et de cette façon le meilleur chemin calculé par deux commutateurs sera toujours le même. Tel que le TRILL, le SPB utilise le mécanisme de prévention de boucles par filtrage à l’entrée de chaque commutateur à travers le RPFC. Pour établir les chemins le IS-IS-SPB peut utiliser aussi les identificateurs de VLAN (VIDs) et les identificateurs de service (Service identifiers (I-SID)) utilisés par la norme IEEE 802.1ah. Il existe deux modes d’opération SPB, le SPBV utilise le shortest pathVID (SPVID) pour identifier les SPT et le SPBM utilise les adresses MAC pour l’identification des SPTs.
Dans ce chapitre nous avons présenté les technologies Ethernet traditionnelles et de nouvelle génération. On a vu que la popularité de l’Ethernet a provoqué le développement de nouvelles technologies qui per-mettent son utilisation dans les réseaux étendus. Pourtant, le concept du « Carrier Ethernet » exige quelques attributs qui ne sont pas encore existants dans les réseaux Ethernet utilisés présentement. Au niveau des protocoles de contrôle, l’utilisation de protocoles traditionnels comme le RSTP peut limiter la capacité du réseau, puisqu’ils n’ont pas été conçus pour être utilisés dans ce type de réseau. L’utilisation du protocole
IS-ISpour le contrôle des réseaux Ethernet de nouvelle génération a été adoptée pour les technologies SPB et TRILL, ce qui permet de résoudre les problèmes décrits plus haut, puisque ce protocole était déjà utilisé avec succès dans les réseaux IP.
La robustesse des réseaux
Les réseaux de transport doivent présenter une haute fiabilité, mais pourtant les défaillances du réseau ne sont pas un événement rare. Les problèmes peuvent avoir plusieurs origines telles que des interruptions dans le moyen physique, défaillance d’équipements ou des tâches de manutention. Pour diminuer les problèmes causés par les interruptions il est nécessaire d’implémenter des mécanismes pour augmenter la robustesse du réseau. Bien que ces mécanismes puissent être implémentés dans différentes couches du réseau, un mé-canisme au niveau optique ne sera pas capable de détecter une défaillance dans une interface électrique d’un routeur par exemple [38]. Pour cette raison l’utilisation de mécanismes de recouvrement dans une couche supérieure, voire à chaque niveau, présente des avantages. Ce chapitre fera une description des mécanismes de recouvrement utilisés dans les réseaux de transport et Ethernet.
3.1
Les mécanismes de recouvrement
Pour contourner les problèmes causés par les interruptions dans le moyen physique et ainsi garantir la robustesse du réseau, plusieurs mécanismes de recouvrement ont été développés. Une façon de classifier ces mécanismes consiste à distinguer les mécanismes de protection et de rétablissement [39]. Les mécanismes de protection offrent un chemin alternatif qui est établi avant l’occurrence de la défaillance, alors que les méca-nismes de rétablissement offrent le chemin alternatif après l’occurrence de la défaillance [40]. La figure 3.1 monte un exemple de cette classification.
Protection Restauration Chemin principal Chemin secondaire Direction du trafic Lien défectueux
FIGURE3.1 – Exemple de protection et rétablissement
Une autre classification utilisée pour les mécanismes de recouvrement est la distinction entre recouvre-ment local et global. Un mécanisme de recouvrerecouvre-ment local produit un détour seulerecouvre-ment autour de l’élérecouvre-ment défectueux, alors que dans un mécanisme de recouvrement global le chemin alternatif n’utilise pas d’élé-ments communs au chemin principal, sauf à l’origine et à la destination. Les chemins principal et alternatif peuvent aussi utiliser une partie des éléments communs, ce qui serait une solution intermédiaire (mixte) entre les deux solutions [39]. La figure 3.2 montre des exemples.
Protection Globale Direction du trafic Protection Locale Protection Mixte Lien défectueux
FIGURE3.2 – Exemple de récuperation globale, locale et mixte
Le mécanisme de contrôle de recouvrement peut utiliser un système centralisé, quand un contrôle central est responsable pour les actions, ou un système décentralisé ou distribué, quand les éléments du réseau
initient la procédure de recouvrement d’une façon autonome. Nous présentons maintenant une introduction aux technologies utilisées dans les réseaux de transport et quelques mécanismes de recouvrement usuels.
3.1.1 Réseaux SONET/SDH
Les réseaux SONET/SDH sont utilisés pour offrir le médium de transport physique pour plusieurs tech-nologies de commutation de paquets comme Ethernet, ATM, IP et MPLS. En principe une technologie TDM n’est pas très efficiente pour le transport de données, mais des mécanismes d’adaptation tel que le GFP, LCAS, VCAT et la technologie OTN ont été développés pour adapter la technologie à la transmission de paquets. Le mécanisme de recouvrement le plus utilisé dans les réseaux SONET/SDH est un mécanisme de protection qui utilise le protocole Automatic Protection Switching (APS), ce mécanisme peut garantir un recouvrement rapide sur une topologie en anneau (Ring Protection) ou sur un lien entre deux équipements (Linear Protection). La topologie et la longueur des liens peuvent influencer le temps de recouvrement. Pour illustrer ceci, à partir des exemples montrés en [39] on peut obtenir une équation du temps maximal néces-saire pour que l’APS puisse compléter la procédure de recouvrement dans une topologie en anneau:
Tmax= 3 × (N − 1) × 0.875 × L × 10−2,
où N est le nombre de nœuds et L est la longueur de l’anneau en km; le délai de propagation du médium physique est de 8.75 µs par km. Ce temps maximal correspond à trois fois le délai de transit et n’intègre pas le temps de traitement des messages du protocole. L’ITU-T définit un temps maximal de 50 ms pour une topologie en anneau avec un nombre maximal de 16 nœuds et une longueur maximale de 1200 km [41].
3.1.2 Réseaux IP
Les réseaux IP traditionnels utilisent un protocole de routage interne (Interior Gateway Protocol (IGP)) pour transporter les informations qui permettront l’établissement des routes. Les protocoles IGP les plus utilisés comme le Open Shortest Path First (OSPF) et le IS-IS présentent un temps de convergence variable. En prenant compte du temps de détection d’un problème, du temps pour recalculer la nouvelle topologie dans le routeur qui détecte la défaillance, du temps de génération et distribution des annonces de changement et
du temps de calcul dans les autres routeurs du réseau, le temps total peut totaliser de l’ordre de quelques centaines de millisecondes ou même plusieurs secondes [42]. On trouve dans [43] une analyse des facteurs qui affectent le temps de convergence de ces protocoles. En utilisant le IS-IS, le temps de recouvrement dépend de la synchronisation des tables de chaque commutateur pour garantir la gestion de la topologie logique du réseau. En cas d’altération de la topologie physique c’est le temps nécessaire pour synchroniser les tables qui va déterminer le temps de convergence. La détection d’un problème dans un lien physique peut être faite par la couche physique (par exemple à travers les mécanismes du SONET/SDH), par l’utilisation d’un protocole de gestion (keep alive checking), ou par l’expiration du temps d’attente des messages IIH. Une fois que le niveau de contrôle du nœud est informé du changement d’état, il produit un nouveau LSPDU pour diffuser l’information aux autres nœuds du réseau, et ainsi chaque nœud peut mettre à jour sa base de données avec la nouvelle information et calculer la nouvelle topologie.
La convergence du protocole IS-IS a été étudiée dans plusieurs travaux dans le cadre des réseaux IP. Dans [43] [44] les facteurs qui influencent le temps de recouvrement dans un routeur sont identifiés, et cette équation montre la caractérisation du temps de convergence (Tc) du protocole IS-IS (dans ce cas le temps de recouvrement du réseau):
Tc =D + O + F + SP T + RIB + DD (3.1)
où D est le temps de détection de la défaillance qui selon l’étude présentée est accompli en moins de 20ms dans la majorité des cas; O est le temps pour générer le LSPDU (moins de 12ms selon l’étude); F est le temps de diffusion à partir du nœud qui détecte la défaillance jusqu’aux nœuds qui doivent réaliser le changement dans leur base de données (ce temps est variable selon la topologie et l’utilisation de mécanismes comme le Fast Flooding); SPT est le temps pour le calcul de l’arbre, l’algorithme Shortest Path First (SPF) typique présente une complexité O(nlog(n)) qui peut diminuer à travers l’utilisation d’optimisations comme le Incremental SPF (iSPF) - l’étude a obtenu une valeur linéaire approximative de 45µs par nœud sans l’utilisation d’iSPF; RIB est le temps nécessaire pour remplir les tables, qui augmente avec le nombre de préfixes (IP) modifiés et dans l’étude il se trouve dans l’ordre des centaines de microsecondes par préfixe; DD est le temps de distribution des tables aux cartes de ligne, un temps moyen de moins de 50 ms dans l’étude. Dans l’article l’analyse du temps de convergence a été faite à travers la simulation de deux topologies réelles différentes (GÉANT et un Internet Service Provider (ISP) Tier-1) et le temps de convergence dans le cas de défaillance dans un lien pour la topologie ISP a présenté des valeurs entre 50 ms et 250 ms pour les diverses