How Old Do You Look? Inferring Your Age From Your Gaze
Texte intégral
Figure
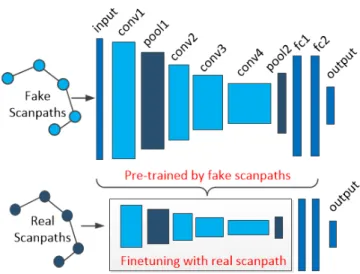
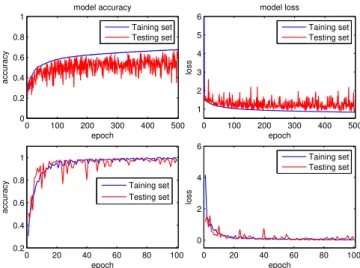
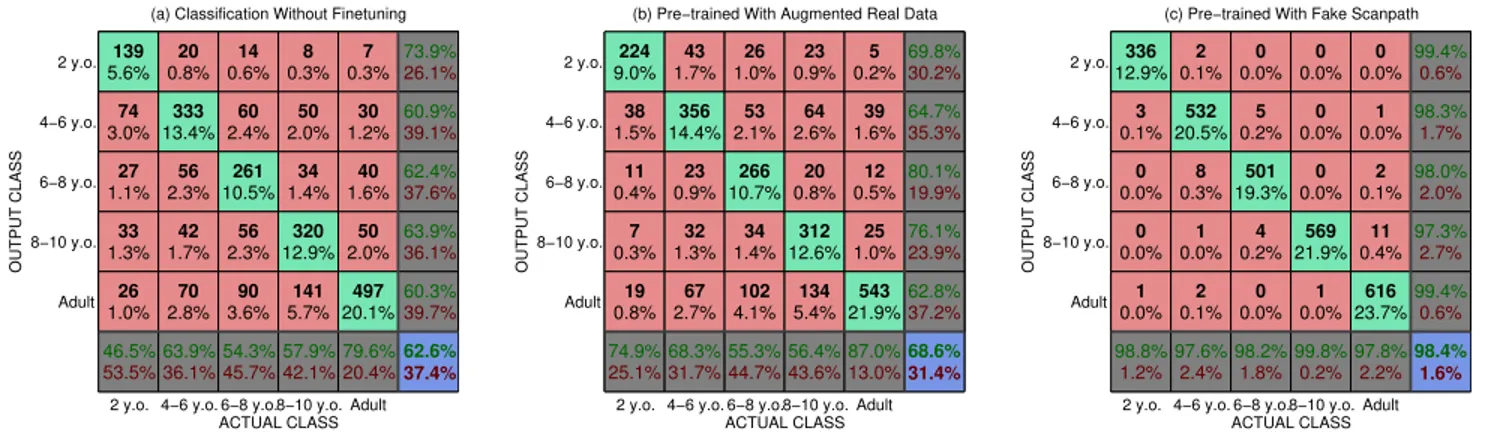
Documents relatifs
b) Para piscinas com válvulas de admissão e retorno, o nível da água deve de estar a 20 cm do borde superior da piscina; fechar as válvulas com o sistema de rosca de que estão
Esta posibilidad se emplea para revolver el agua si debe añadirse un producto en la piscina o si se debe efectuar alguna operación en el filtro, dado que en este caso el filtro
The role of adult pornography in child abuse is also recognised in the Sexual Offences Act 2003, which creates a new offence of causing a child to watch a sexual
Iago, as the prophet of this new creed, demonstrates its efficacy by suc- ceeding along the same lines as the political and military innovators catalogued by Machiavelli in The Prince
Michael Taft has refined Wilgus's re- cording-as-broadside equation in light of New- foundland popular music, arguing that sound recordings influence listeners in terms
b) Para piscinas com válvulas de admissão e retorno, o nível da água deve de estar a 20 cm do borde superior da piscina; fechar as válvulas com o sistema de rosca de que estão
Esta posibilidad se emplea para revolver el agua si debe añadirse un producto en la piscina o si se debe efectuar alguna operación en el filtro, dado que en este caso el filtro
Focusing on eye tracking data from observations of cartographic lines, in this paper we propose a new visualization of eye tracking data using polylines inferred from the analysis
