A probabilistic model to exploit user expectations in XML information retrieval
20
0
0
Texte intégral
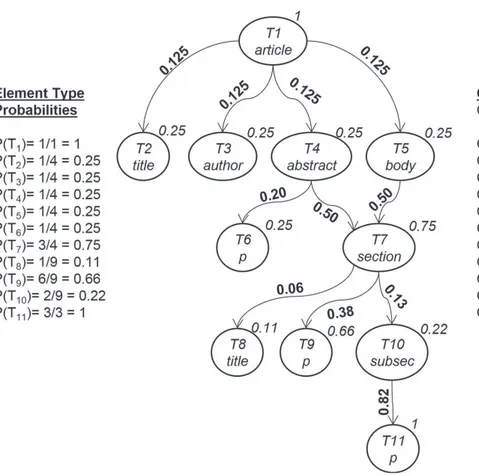
Figure


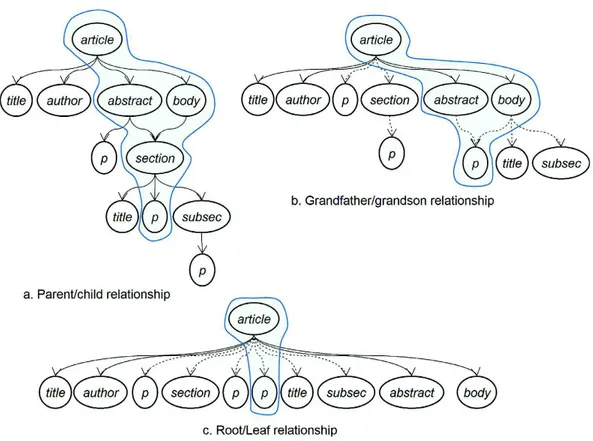
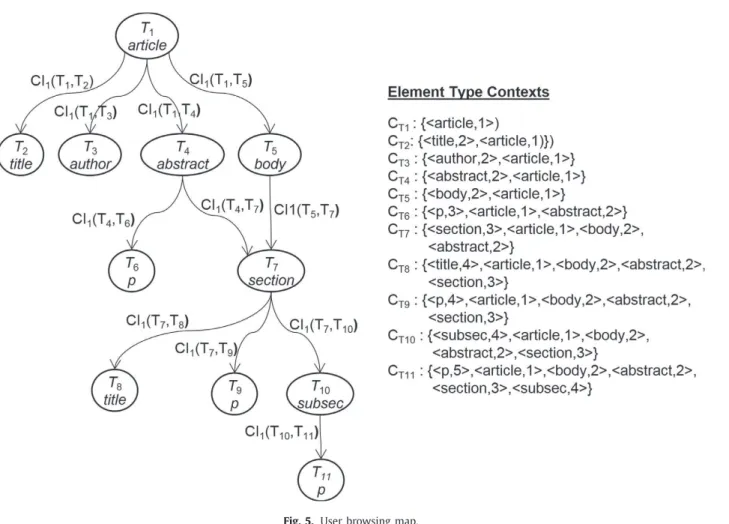
+7
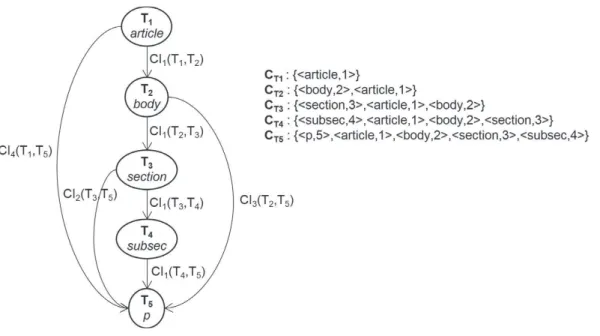
Documents relatifs
