Sloshing in the LNG shipping industry: risk modelling through multivariate heavy-tail analysis
Texte intégral
Figure
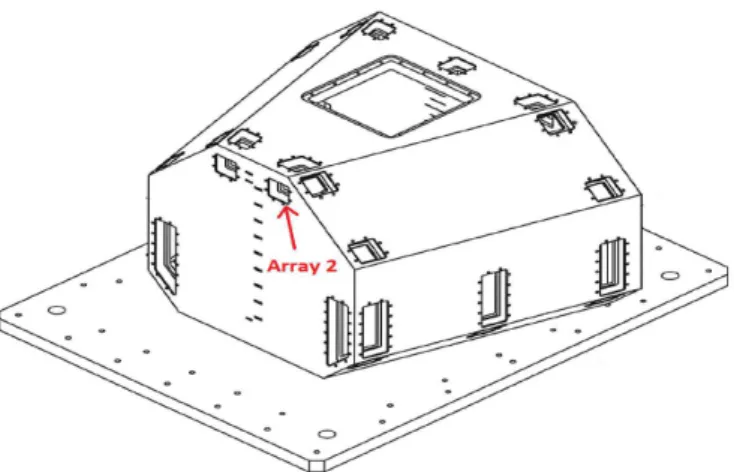






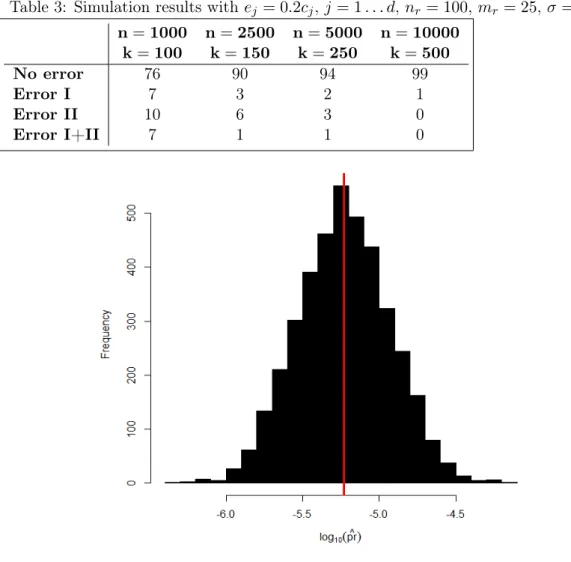
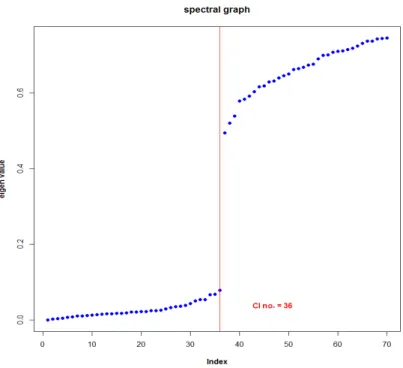
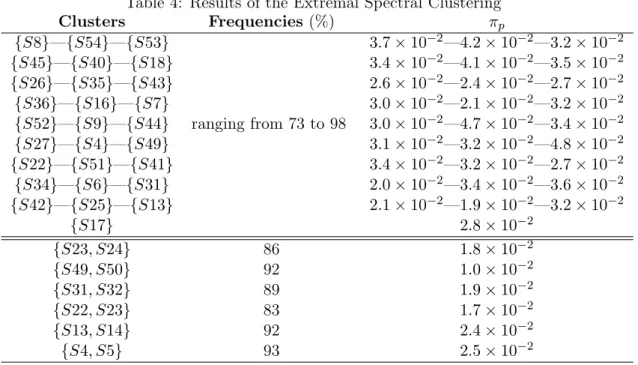
Documents relatifs
Given a learning task defined by a space of potential examples together with their attached output values (in case of supervised learning) and a cost function over the
Additionally, the desynchronization between on-board technologies with Clockspeed and strict security regulations create further obstacles in the aeronautical sector,
In the case of moderately high Froude / Reynolds numbers, the big buoyancy-driven structure opens the tip of the flame which is virtually pushed outside the computational domain
Alternatively and further magnified by the results presented in the next section, limitation of microwave heating by application of the intermittent drying mode and combination with
fMRI studies have located prediction error (PE) signals in dif- ferent brain regions, such as the ventral striatum and ven- tromedial prefrontal cortex (vmPFC) for reward versus
If IT is a global worldwide priority, China enjoys now a predominant position, with the manufacture of a large percentage of IT products, the emergence of national corporations
The results of recent investigations of the effect of high pressures on grain boundary diffusion and grain boundary migration in Aluminium are compared. The activation
The proposed approach for implementing risk management taking into account the stakeholders interactions and their potential to cause risks for a project or organization,
