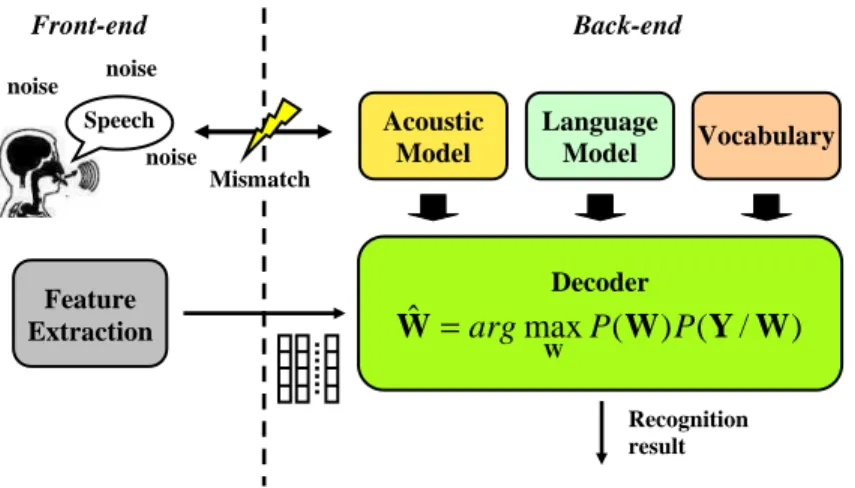
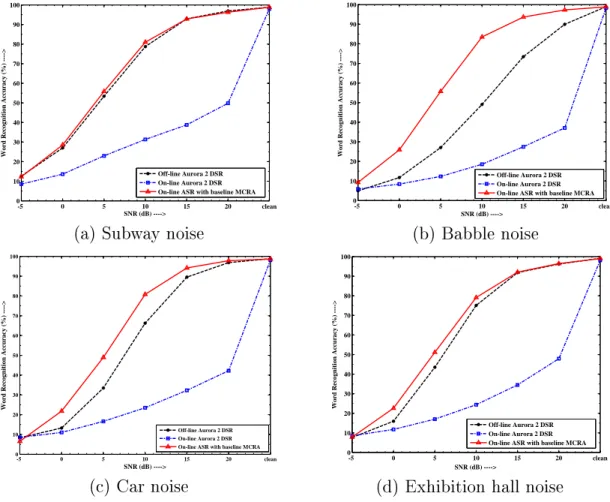
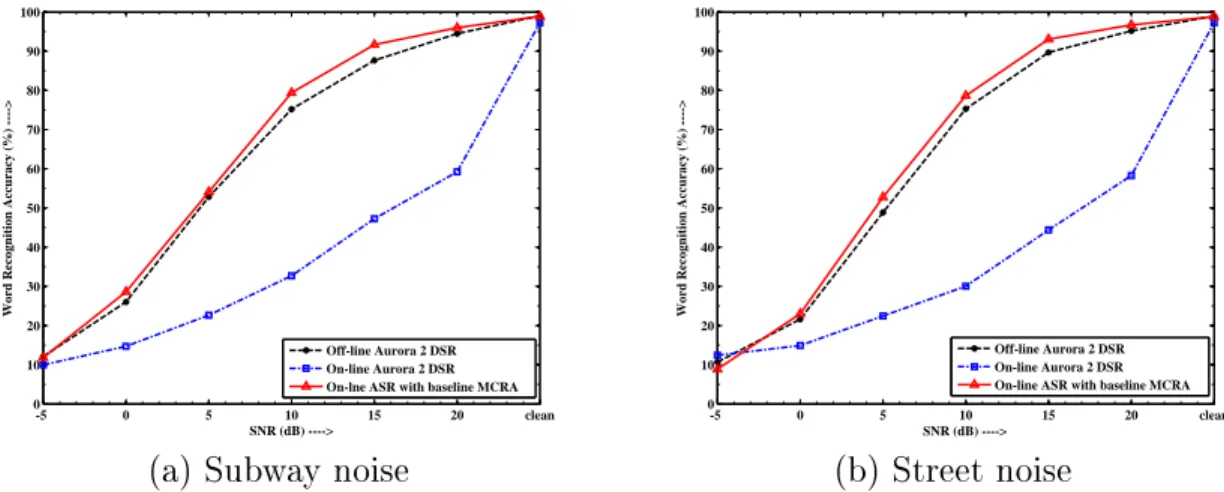
A Soft Computing Approach for On-Line Automatic Speech Recognition in Highly Non-Stationary Acoustic Environments.
Texte intégral
Figure
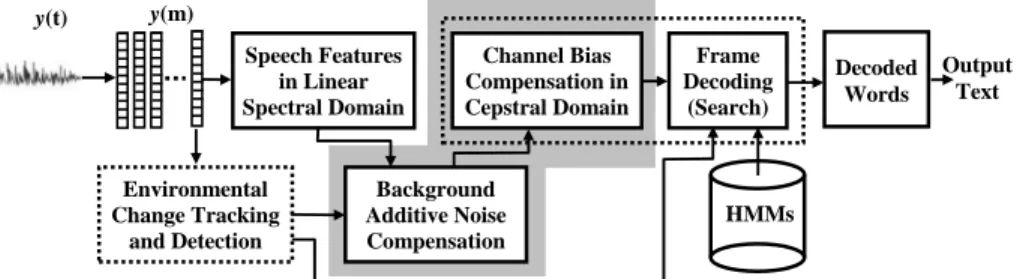


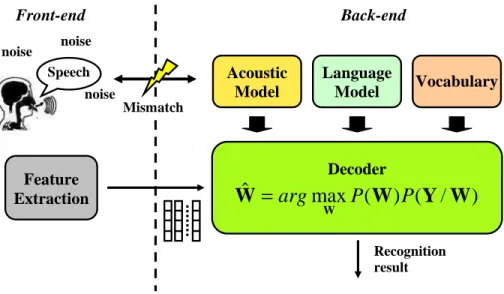
![Figure 3.2 Frame adaptive dynamic joint bias compensation (JAC) technique with time smoothing parameter α b = 0.995 [2]](https://thumb-eu.123doks.com/thumbv2/123doknet/5403440.125934/143.918.206.845.138.342/figure-frame-adaptive-dynamic-compensation-technique-smoothing-parameter.webp)
Documents relatifs
trees and other machine learning techniques to com- bine the results of ASR systems fed by different fea- ture streams or using different models in order to reduce word error
h ] is above a given threshold for one word or for time segment containing a sequence of words and pauses, then a new set of features is computed in that segment and recognition is
To measure the spectral mismatch between adult and children’s speech caused by differences in vocal tract length, we computed the mean warping factor for speakers in the ChildIt
Recognition accuracy results obtained by the standard model with incorporated voicing probability employing both the estimated and oracle voicing information.. For comparison,
On the other hand, the effect of the vocal tract shape on the intrinsic variability of the speech signal between different speakers has been widely studied and many solutions to
(a) Non-spatial selection in stationary environment: gray circles, that represent robots informed about goal direction A, are selected at random locations in the swarm (the
To deal with the problem of lack of text data and the word error segmentation in language modeling, we tried to exploit different views of the text data by using word and sub-word
Acoustic Model Merging Using Acoustic Models from Multilingual Speakers for Automatic Speech Recognition.. Tien Ping Tan, Laurent Besacier,
