Gaussian linear approximation for the estimation of the Shapley effects
Texte intégral
Figure
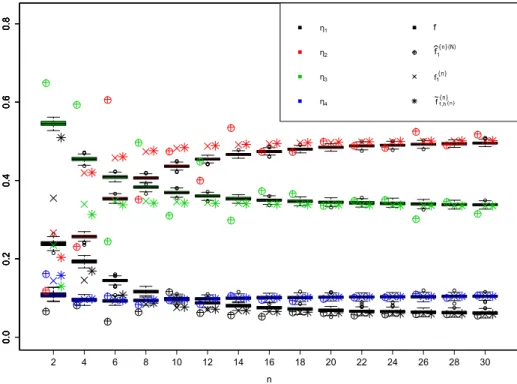
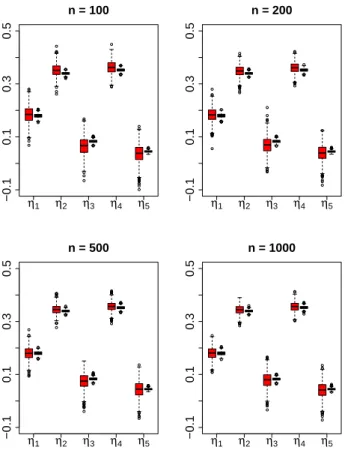
Documents relatifs
For example, Jiang & Tanner (1999a) proved that the class of single-output soft-max gated MoLE models can approximate any conditional density with mean function characterized via
/ La version de cette publication peut être l’une des suivantes : la version prépublication de l’auteur, la version acceptée du manuscrit ou la version de l’éditeur. Access
Dans cet article, nous proposons un modèle de SR original ayant pour ob- jectif de recommander à l’usager, pour un document visité, une liste d’informations diversifiée basée
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
This means that the spatial observation scale in the plane orthogonal to B is chosen smaller than the one in the parallel direction, more precisely with the same order as the
Ici, la distinction entre Nous et les Autres (cfr. 3.2.1.) peut être discutée sous plusieurs aspects. Si d’un côté les Autres représentent un danger et une menace aux
(This is easily seen for instance on formula (1.2) in the special case of the radiative transfer equation with isotropic scattering.) At variance with the usual diffusion
