An interactive approach for the post-processing in a KDD process
10
0
0
Texte intégral
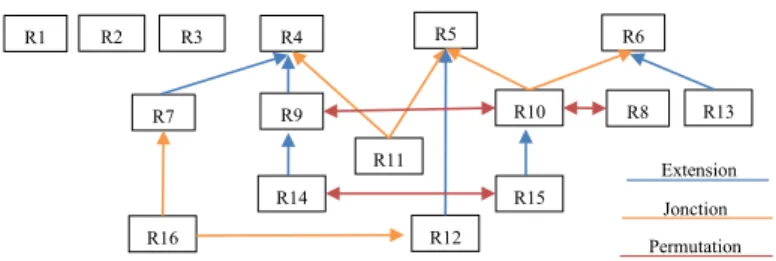
Figure


Documents relatifs
