SLA-aware virtual resource management for cloud infrastructures
Texte intégral
Figure
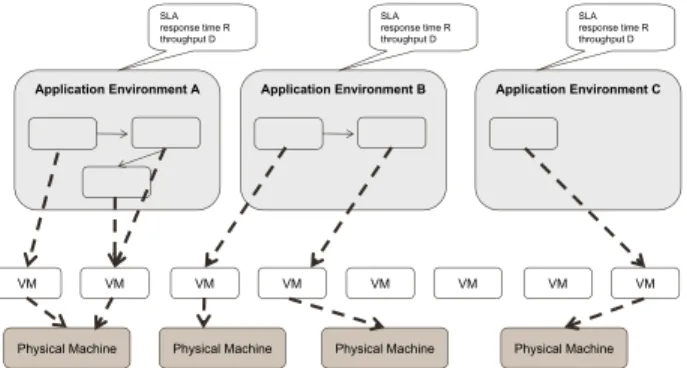
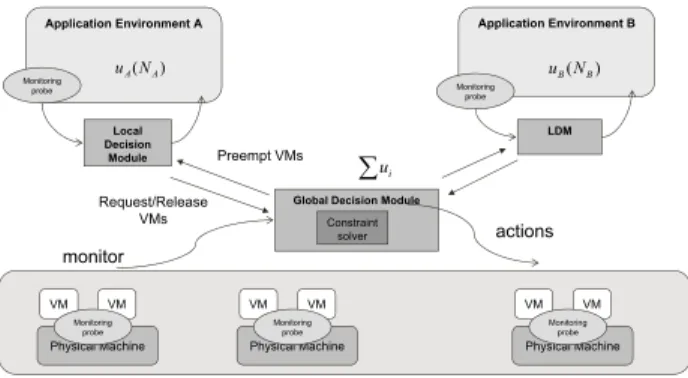
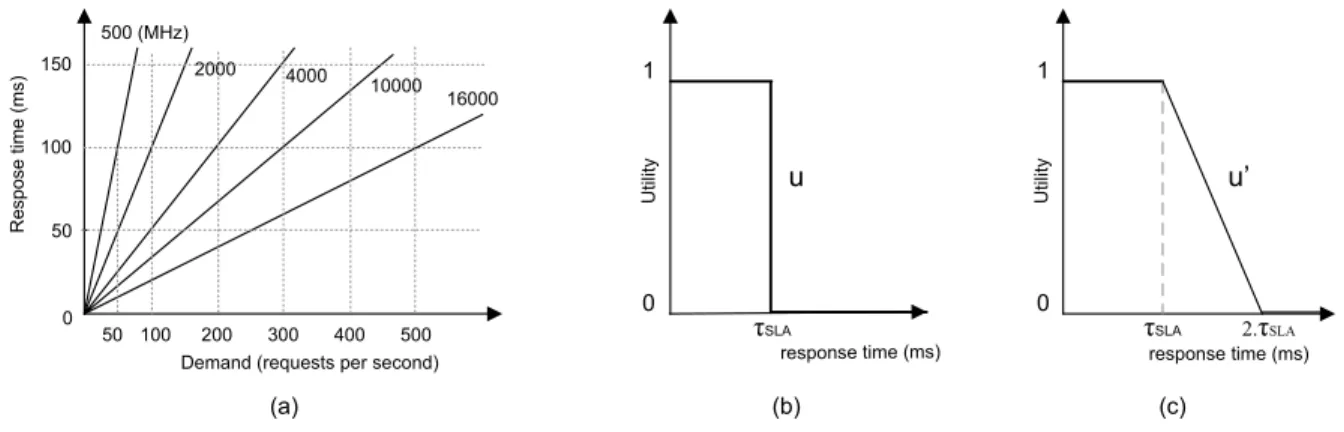
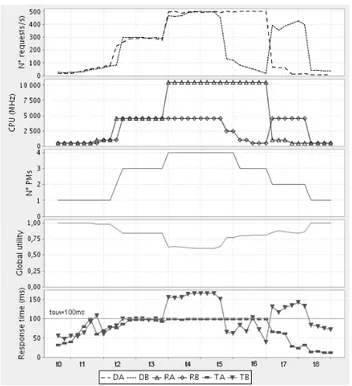
Documents relatifs
Applied to the PISA example, this means that users need to be made aware that they are able to object to processing of personal data for direct marketing purposes (the
As seen in the de fi nition of the superstructure of the problem, the objective is to determine the set of the decision variables (47) that optimizes simultaneously costs,
Proximal algorithms, proximity operator, splitting, convex optimization, support function, disparity map
In the Soviet Constitution of 1936 we find the third slogan: “From each according to his ability; To each according to his work.” “To each according to his work” has its
4) Les chevauchements et cisaille- ments dans la partie nord-est de la Zone axiale sont clairement postérieurs à la culmination du métamorphisme régional principal et aux phases
This part will analyze the overall operation of the system behavior for the use of defense resources to develop the formula of statistical analysis. This paper presents
The goal of this work is a bit different as it proposes a model of competition taking into account the relation between capacity and reputation, and also the customers’ sensitivity
This problem can normally be divided into two steps; the first of which performs the embedding of virtual nodes and links onto substrate nodes and links respectively−also known
