Méthodes de séparation aveugle de sources pour l'imagerie hyperspectrale : application à la télédétection urbaine et à l'astrophysique
206
0
0
Texte intégral
Figure
+7


Outline
Méthodes non linéaires
Hypothèse possibles sur les coefficients de mélange ?
Initialisation des algorithmes
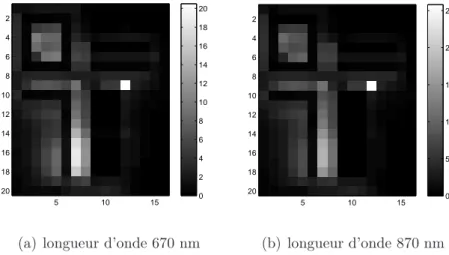
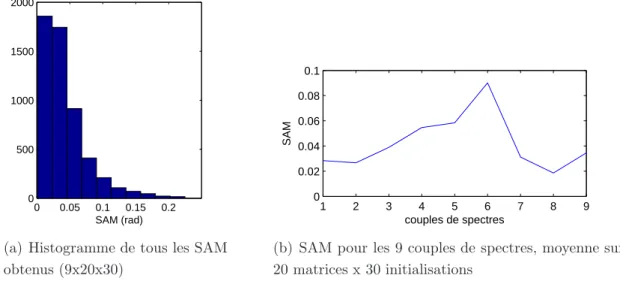
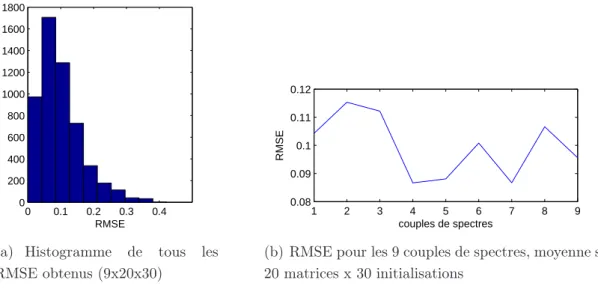
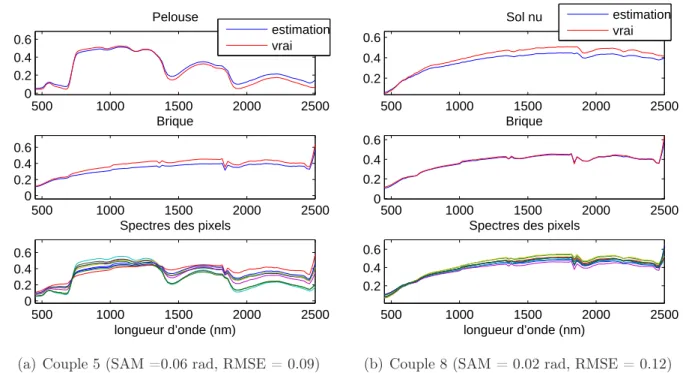
Analyse des résultats à travers l’algorithme LQ mult
Cas 2 : Mélanges de 3 matériaux
Conclusion sur les résultats avec données réelles
Tests et résultats
Résultats de tests de la version accélérée
Documents relatifs
