Deep-Analysis of Palmprint Representation based on Correlation Concept for Human Biometrics identification
Texte intégral
Figure
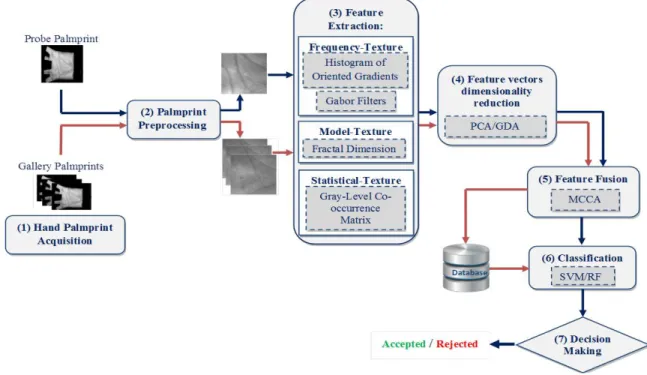
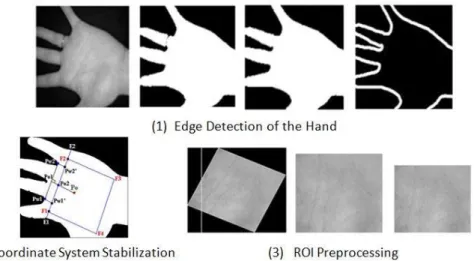

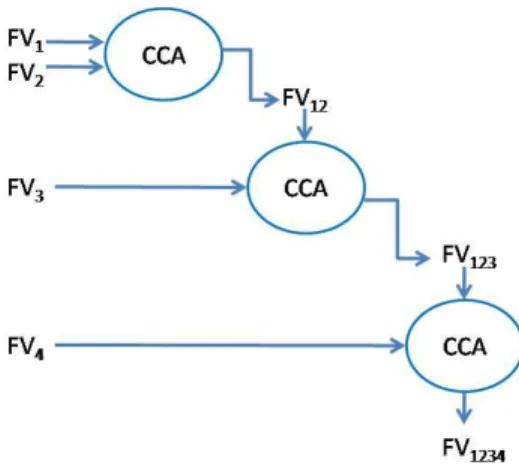
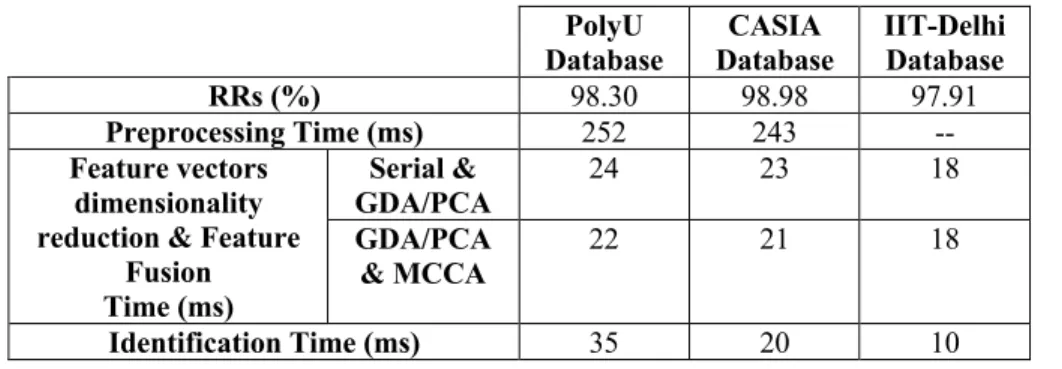
Documents relatifs
Wakeful rest promotes the viewpoint invariance, but not the fine discriminability, of entities mnemonic representations for subsequently familiarity- based recognition.. 2019
Being robust against illumination changes, this method combines four steps: Viola–Jones face detection algorithm, facial image enhancement using contrast limited adaptive
Our main result is an integral representation formula for the solution, in terms of the boundary curvature and of the normal distance to the cut locus of
Grinevald, C., 2007, "Encounters at the brink: linguistic fieldwork among speakers of endangered languages" in The Vanishing Languages of the Pacific Rim. 4 “Dynamique
Conclusion: Human Gene Correlation Analysis (HGCA) is a tool to classify human genes according to their coexpression levels and to identify overrepresented annotation terms
Performance Original palmprint database under noise corruption (a) Recognition per- formance of different approaches with varying feature dimension (b)Performance comparison..
Indeed, for smooth surfaces, the probability of colliding with the surface after desorption is too low for recapture to be signi fi cant, while for high degrees of roughness ( i.e.,
Citation: Grandcolas P (2019) The Rise of “Digital Biology”: We need not only open, FAIR but also sustainable data.. Biodiversity Information Science and Standards
