A Framework for Efficient Representative Summarization of RDF Graphs
Texte intégral
Figure
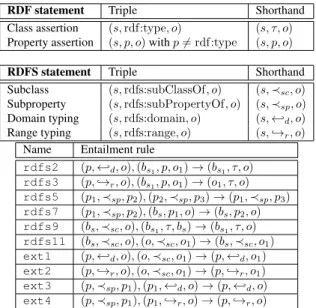

Documents relatifs
En effet, illustrant parfaitement la dynamique du processus de civilisation de Norbert Elias puisqu’il postule la libération du corps et son dévoilement en même
Data triples are read one by one, their subject and object are represented with source and target data nodes, possibly unifying the source and target nodes based on the
(4) Finally, several works combine techniques from several of the main areas listed above; these are hybrid methods, e.g., [1, 27] first and foremost aim at estimating the cardi-
At the end of this stage, the cliques are known and will persist on each machine until the end of the algorithm, but we still need to compute: (i) all the (source clique, target
The contribution of our work is a novel solution into summarizing semantic LOD/RDF graphs, where our summary graph is a RDF graph itself so that we can post simplified queries
a Lyon ambitionna.it de faire evoluer la mentalite de la ville a 1'egard de l'art contemporain de la litterature enfantine et etrangere. Comme le temoigne le Press-Book,
This study provides, to our knowledge, the first deglacial record of density changes in the deep and intermediate South Atlantic spanning the last deglaciation. We find that
stops after reading x on a one-directional input tape; (b) the minimal plain complexity of an algorithm that enumerates a prefix-free set containing x; (c) the conditional
