Reducing synchronization cost in distributed multi-resource allocation problem
Texte intégral
Figure

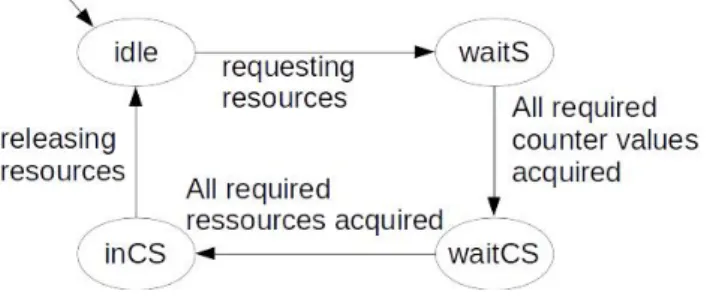
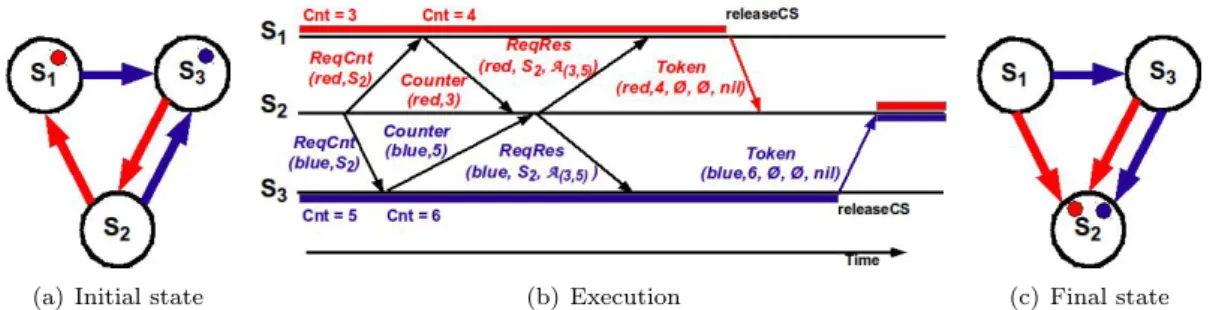

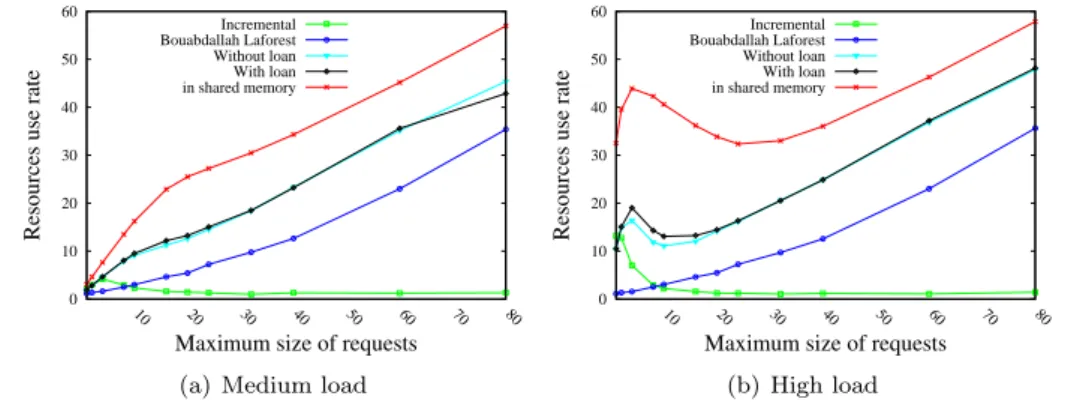
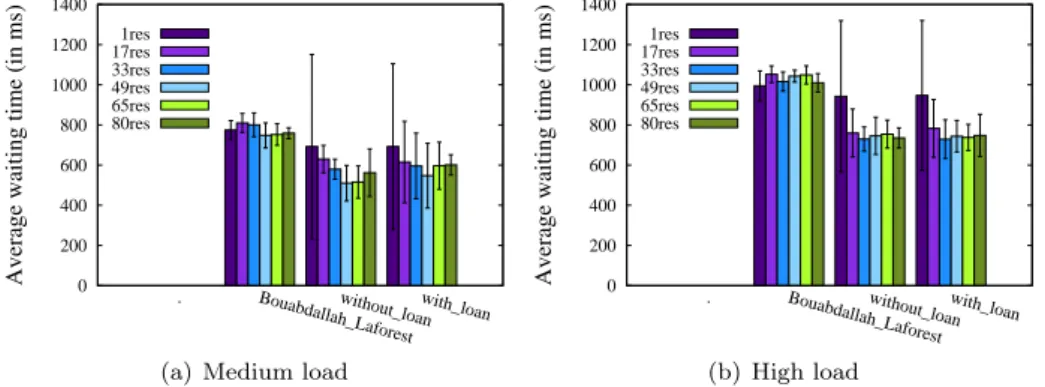



Documents relatifs
is not in contradiction with the fact that the average personal dissatisfaction of heterogeneous agents is always larger than that of homogeneous agents: |δT | is much influenced
1) Presentation of the classification tool: We use the KHIOPS 3 tool, which is a data mining tool allowing to automatically build successfull classification models, on very
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Then a process move program which first schedules the moves having their source in C i and target not in C i , then the moves internal to C i followed by the remaining moves,
We assume that a 5G node can provide a service to user if and only if there exists a complete chain of RFBs composed of one RRH RFB, one BBU RFB and one MEC RFB. The components of
