Sawja: Static Analysis Workshop for Java
Texte intégral
Figure
![Fig. 1. Hierarchy of Java bytecode types. Links represent the subtyping relation enforced by polymorphic variants (for example, the type jvm_type is defined by type jvm_type = [ |‘Object |jvm_basic_type ]).](https://thumb-eu.123doks.com/thumbv2/123doknet/12503270.340468/6.892.260.664.176.331/hierarchy-bytecode-represent-subtyping-relation-enforced-polymorphic-variants.webp)


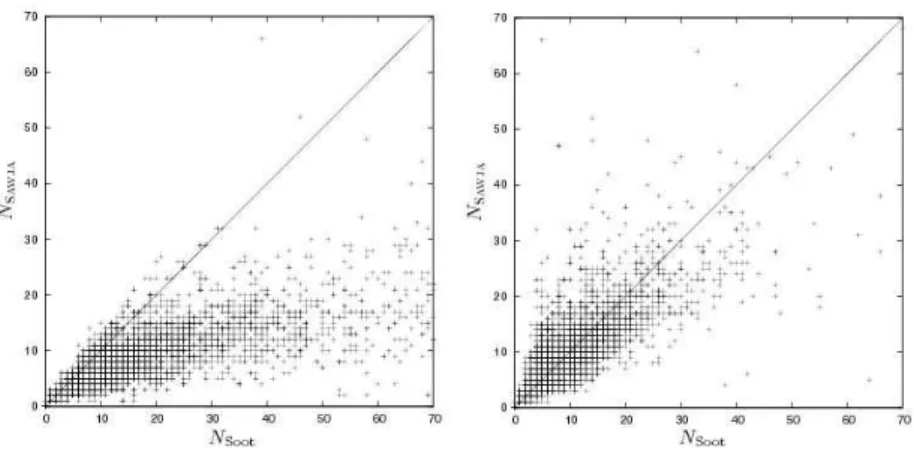
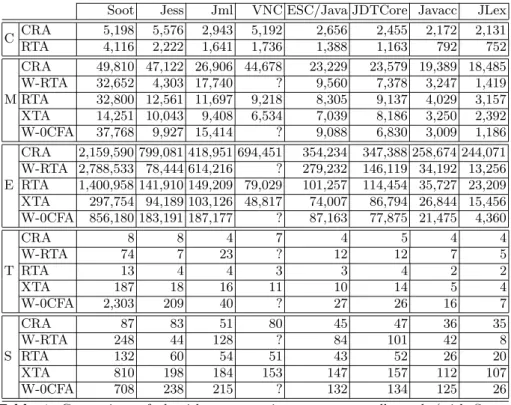
Documents relatifs
traitement requiert ensuite l’inversion d’une matrice dont les dimensions peuvent être importantes. Dans le contexte d’un algorithme d’identification hors ligne, la puissance
Deuxièmement, nous expliquerons com- ment nous avons exploité cette même structure dans le développement d’une analyse statique de la performance des programmes BSPlib..
To prove these results with a denotational analysis, our magic-sets transformation builds new magic blocks of code whose functional behaviours are the internal behaviours just after
Our approach consists of three main steps as shown in Figure 9: (1) the extraction of event handlers; (2) the static analysis; and (3) the generation of test sequences.. Event
On the other hand, verification tools aiming at inferring the possible values of variables at each program point may benefit from the information that some (integer) variables are
The CLR method consists of three main steps: i) construction of the formal context of documents-terms and building of the corresponding concept lattice ii) insertion in the lattice of
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Les virus à ARN négatif simple brin (ordre des Mononegavirales) induisent aussi la formation d’inclusions cyto- plasmiques qui sont également des usines virales dans lesquelles
