SW-ELM : A summation wavelet extreme learning machine algorithm with a priori initialization.
Texte intégral
Figure
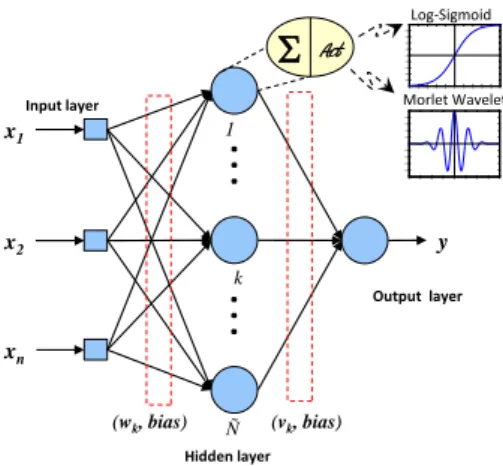

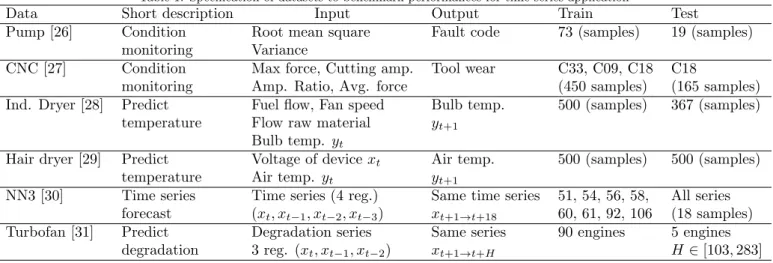
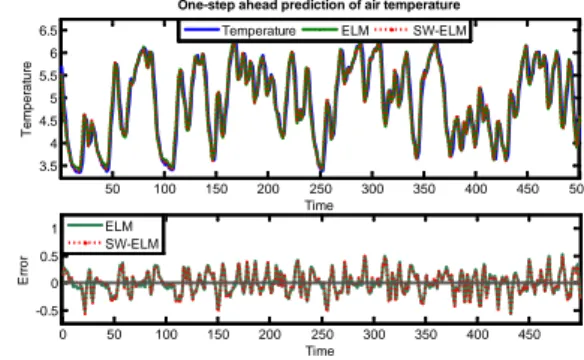

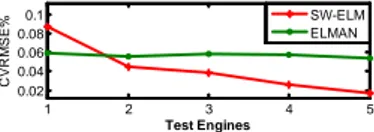
Documents relatifs
(b) DirRec strategy predicts multi-step-ahead values similar to iterative strategy, but, generates a new prediction model after each prediction step. Downloaded
“Echo State Queueing Networks: a combination of Reservoir Computing and Random Neural Networks”, S. Rubino, in Probability in the Engineering and Informational
In this thesis, we show how to extend the discriminative learning framework to exploit different types of structure: on one hand, the structure on outputs, such as the
Even if we were able to correctly classify each Twitter user, we would not be able to make a reliable estimate of the voting results as (i) several Twitter users may not vote,
To calculate the Casimir energy (10) in the (2+1) dimensional model, we discretize each geometry of the boundaries at 255 3 lat- tice and then generate 2 × 10 5 scalar
Compared to the CV-ELM algorithm, the ECV-ELM algorithm proposed in this section is trained by training multiple CV-ELM sub models, and then using ensemble learning methods to
We consider a Tapped Delay Line model C (TDL- C) [11] power delay profile with an RMS delay spread of 200 ns. A cyclic prefix of 4.7 µs is used with an OFDM system constituted of 16
When the first "1" of the e k vector is detected, the value of the following column of the vector of the event e l is studied: if it is a "1", then the pair studied
