Décomposition de graphes en plus courts chemins et en cycles de faible excentricité
97
0
0
Texte intégral
Figure

+7
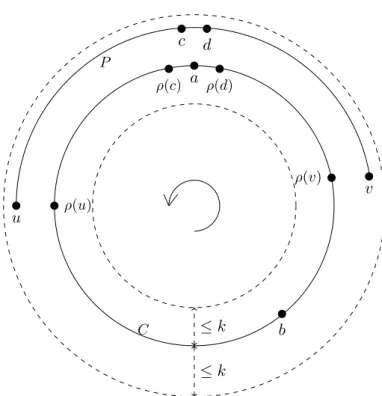
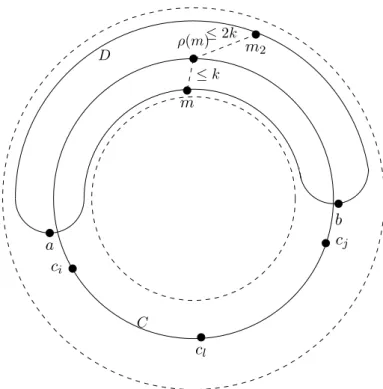
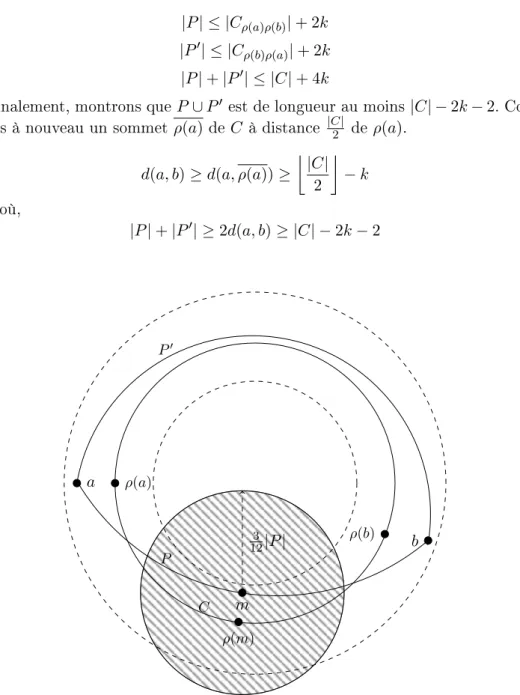
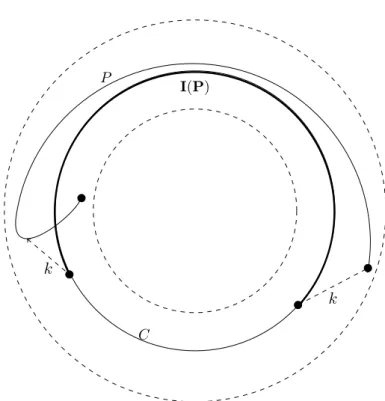
Documents relatifs
