Parametrised measures for the evaluation of association rule interestingness
Texte intégral
Figure
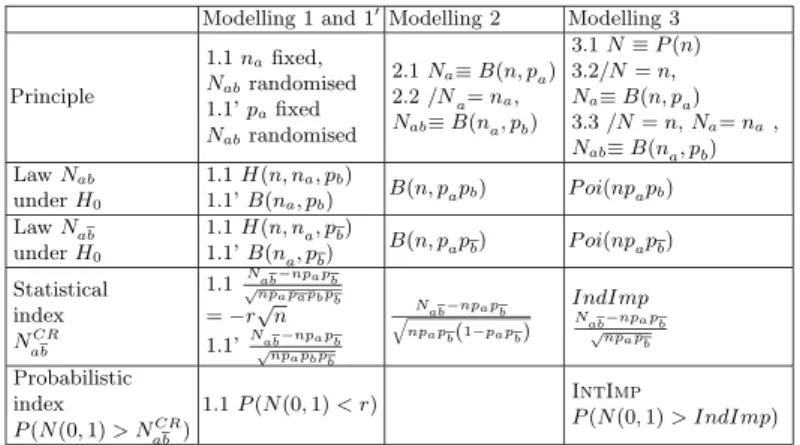

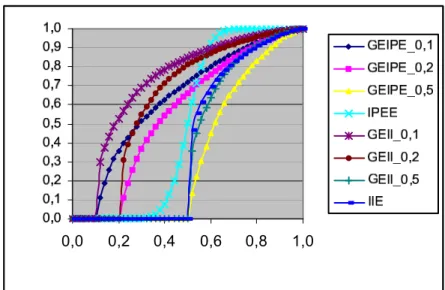
Documents relatifs
The two main peculiarities of the ECBM recovery process are that the adsorption/desorption mechanism taking place controls the displacement dynamics and that gas sorption is
In Section 6 we give sharp upper and lower bounds for the dissipation length scale, the structure functions and the energy spectrum for the ow u(t, x) , which hold uniformly for ν ≤ ν
We have the following commutative algebraic characterisation of generalised Frobenius numbers in terms of the generalised lattice modules..
prove generalisations of Mertens’ formula for quadratic imaginary num- ber fields and definite quaternion algebras over Q , counting results of quadratic irrationals with respect to
les facteurs spectroscopiques de certains niveaux excités de 190 à partir de l'analyse DWBA des distributions angulaires de la réaction 180(d,p).. L'expérience 20Ne(d,p) a
We evaluated the psychometric proprieties of a French child and parent-rated version of the JTCI based on a previous German version, and assessed the correlations between the
temperature inversion breakup that inhibits upslope winds. The present paper shows that cold air advection by sea-breeze generates a mesoscale horizontal
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
