stéganographie
Ould Medeni Mohamed Bouye
Remerciements
Les travaux présentés dans cette thèse ont été effectués au laboratoire de Mathéma-tiques, Informatique et Applications de la Faculté des Sciences de l’Université Mohammed V Agdal de Rabat.
C’est avec une immense joie que j’exprime ma reconnaissance et ma gratitude envers mon professeur et directeur de thèse Monsieur El Mamoun SOUIDI qui a accepté de diriger mon travail tout au long de ces longues années, et qui a toujours su attirer mon intention avec ses remarques pertinentes et ses commentaires intéressants tout en me laissant une marge assez large de liberté. En tant qu’étudiant à la Faculté des Sciences de RABAT, ses qualités d’enseignant chercheur et sa méthodologie de travail m’ont données du goût à la cryptographie et la sécurité informatique en général. Le déroulement de mon projet de recherche a été sagement guidé par des réunions régulières aux cours desquelles il a su combiner sympathie et sérieux afin de me faire profiter de son expertise pour évaluer mes travaux de recherche et de ses conseils enrichissants pour diriger l’évolution de ma maîtrise ainsi celle de mon projet de recherche. Il avait auparavant guidé avec soin mes premiers pas de chercheur pour obtenir le D.E.S.A. Sa clairvoyance et son sérieux ont été pour moi une source d’inspiration et d’admiration. A sa disponibilité, à son sérieux, à son soutien continu, à ses encouragements, et à sa bienveillance je dois cette thèse. Sans lui, je ne serais jamais arriver là où je suis maintenant. A lui, je dois un immense respect.
C’est également avec un grand plaisir que j’exprime mes chaleureux remerciements à Monsieur Said EL HAJJI professeur à l’université Mohammed V Agdal pour l’honneur qu’il m’a fait en présidant le jury de cette thèse et en acceptant d’en être rapporteur.
J’exprime ma gratitude à Monsieur Abdelmalek AZIZI professeur à l’université Mo-hammed 1er d’Oujda et Membre de l’académie Hassan II des sciences et Techniques de
me faire l’honneur d’accepter d’être rapporteurs de ma thèse.
l’Uni-versité de Limoges en France pour l’honneur qu’il me fait en examinant cette thèse et d’accepter sans hésitation de faire le voyage à RABAT pour participer au jury. J’ai eu la chance d’effectuer un stage de trois mois au sein de son laboratoire XLIM, et sous sa direction de grand professeur qui a assez d’expérience dans le domaine de la cryptologie, codage et sécurité des systèmes informatiques et de publier un article avec lui. Il m’a prodigué de nombreux conseils et j’avoue avoir appris beaucoup avec lui, et j’espère conti-nuer même après ma thèse. J’ai été aussi extrêmement sensible à ses qualités humaines et à ces encouragements. Un grand MERCI aussi a tous les professeurs et le personnel du laboratoire XLIM pour leur hospitalité.
Je suis extrêmement sensible à l’honneur que m’ont fait Messieurs Mostapha BEL-KASMI professeur à l’université Mohammed V Souissi et Samir BELFKIH professeur à l’université Ibn Tofail de Kénitra en acceptant d’examiner mon travail.
J’exprime aussi mes sincères remerciements à tous les chercheurs de l’équipe du La-boratoire de Mathématique Informatique et Applications de RABAT, à Mme. Souad El barnoussi et M. Jilali Mikram pour leur assistance ainsi qu’à tous ceux qui de près ou de loin m’ont soutenu et encouragé moralement et matériellement.
Je tiens plus particulièrement à remercier mes amis chercheurs, plus particulièrement mon meilleur ami Benyacoub Badereddine pour ses encouragements incessants et pour son soutien.
Une ÉNORME pensée à ma famille qui a toujours cru en moi et soutenu, malgré mon isolement géographique et trop souvent téléphonique. A ma maman, mon papa, mes frères et sœurs, ma grande mère.
Table des matières
Remerciements 1
Table des matières 3
Introduction 10
1 Codes Correcteurs d’erreurs 17
1.1 Codes Linéaires . . . 17
1.2 Détection et correction des erreurs . . . 20
1.3 Codes de Hamming . . . 21 1.4 Codes de Reed-Solomon . . . 22 1.5 Codes BCH et Goppa . . . 23 2 Stéganographie et Stéganalyse 25 2.1 La Stéganographie . . . 25 2.1.1 Histoire de la stéganographie . . . 26 2.1.2 La Stéganographie Moderne . . . 28 2.1.3 Architectures Stéganographique . . . 28
2.1.4 Caractéristiques de Schéma Stéganographique . . . 29
2.1.5 Techniques Stéganographiques . . . 31
2.2 Codage matriciel (en anglais : "Matrix encoding") . . . 35
2.3 Le format JPEG en Stéganographie . . . 37
2.3.1 Transformation des couleurs . . . 38
2.3.2 Transformation DCT . . . 40
2.3.3 Quantification . . . 41
2.3.5 Codage de Huffman . . . 44
2.4 Stéganographie adaptée au format JPEG . . . 45
2.4.1 Outguess . . . 46
2.4.2 Logiciels Stéganographiques . . . 48
2.4.3 Sécurité d’un schéma de stéganographie . . . 52
2.5 Stéganalyse . . . 54
2.5.1 Techniques Spécifiques . . . 54
2.5.2 Analyse du χ2 . . . 54
2.5.3 Stéganalyse RS . . . 58
2.5.4 Steganalyse de l’algorithme Outguess . . . 65
2.5.5 Techniques Universelles . . . 66
2.5.6 Conclusion . . . 67
3 Codes appliqués à la Stéganographie 68 3.1 Codes de Hamming en stéganographie (F5) . . . 68
3.1.1 Exemple F5 : utilisation des codes de Hamming . . . 69
3.1.2 Efficacité d’insertion . . . 71
3.2 Codes BCH en Stéganographie . . . 73
3.2.1 Look-up tables . . . 76
3.2.2 Dissimulation des données en utilisant le codage par syndrome . . . 82
3.2.3 Tests et résultats . . . 82
3.3 Codes à papier mouillé en stéganographie . . . 84
3.4 Codes de Reed-Solomon en stéganographie . . . 89
3.4.1 Utilisation de l’interpolation de Lagrange . . . 90
3.4.2 Construction plus efficace . . . 91
3.4.3 Algorithme de Guruswami-Sudan : . . . 92
3.5 Décodage par décision majoritaire en Stéganographie . . . 94
3.5.1 Une Nouvelle Construction du Schéma Stéganographique . . . 94
3.5.2 Décodage par décision majoritaire . . . 95
3.5.3 Nouveau schéma . . . 95
3.5.4 Analyse du schéma . . . 99
3.6 Codes non linéaires en stéganographie . . . 100
3.6.2 Fonction Gray Map . . . 101 3.6.3 Codes de Goethals . . . 102 3.6.4 La méthode stéganographique proposée . . . 102 4 A Novel Steganographic Protocol from Error-correcting Codes 104 5 A New Steganographic Algorithm Using Graph Coloring Problem 106 6 Construction and Bound of Matrix-Product Codes 108 7 Quantum steganography via Greenberger-Horne-Zeilinger GHZ4 state 110
8 Steganography and Error-Correcting Codes 112
9 Maximum likelihood decoding algorithm 114
10 A Novel Steganographic Method for Gray-Level Images 116
Liste des tableaux
2.1 Exemple d’un bloc de coefficients DCT . . . 41
2.2 Tables de référence pour la luminance . . . 42
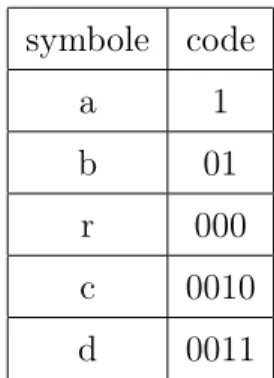
2.3 Code de Huffman pour S = "abracadabra" . . . 45
2.4 Correspondance entre indice et élément. . . 63
2.5 Occurrences de chaque élément. . . 63
2.6 Résultat de la fonction de discrimination sur l’image de base. . . 63
2.7 Résultat de la fonction de discrimination et classification. . . 63
2.8 Récapitulation des résultats obtenus. . . 64
Table des figures
1 Domaine de la dissimulation de l’information . . . 12
2.1 Jean Trithème et Steganographia [100] . . . 27
2.2 Schéma simplifié de Stéganographie [18] . . . 28
2.3 Schéma complet [18] . . . 29
2.4 Triangle des caractéristiques . . . 30
2.5 Image originale et image contenant des données . . . 35
2.6 Schéma de compression/décompression JPEG . . . 38
2.7 Séquence Zig-Zag . . . 43
2.8 Image chinois.jpg [100] . . . 46
2.9 Modifications de l’histogramme de chinois.jpg par Jsteg [100] . . . 47
2.10 A gauche, image original et à droite, image stéganographiée par LSB [48] . 55 3.1 Évolution de l’efficacité d’insertion . . . 72
3.2 Évolution de la taille relative . . . 74
3.3 Image de Lena (a) et son histogramme (b) . . . 84
Publications
1. M.B. Medeni, Mamoun SOUIDI. : Steganographic algorithm based on error-correcting codes for gray scale images., 5th International Symposium on Communications and Mobile Network (ISVC), 2010, IEEE 10.1109/ISVC.2010.5654877
2. M.B. Medeni, Mamoun SOUIDI. : steganographic method for gray images., Inter-national Conference on Multimedia Computing and Systems (ICMCS), 2011, IEEE 10.1109/ICMCS.2011.5945688
3. M.B. Medeni, Mamoun SOUIDI. : Matrix-Product Codes in Steganography., Work-shop on Codes and cryptography, (WCCCS’11), ENSIAS University Mohammed V-Souissi, Rabat Morocco.
4. M.B. Medeni, Mamoun SOUIDI. : A Novel Steganographic Protocol from Error-correcting Codes., Journal of Information Hiding and Multimedia Signal Processing, Volume 1, Number 4, pp.337-343 (2010).
5. M.B. MEDENI, El Mamoun SOUIDI. : Construction and Bound on the Performance of Matrix-Product Codes., Applied Mathematical Sciences, Vol. 5, 2011, no. 19, pp. 929-934.
6. M.B. MEDENI, El Mamoun SOUIDI. : Steganography Protocols from Coding theory, Workshop on Codes and cryptography, (WCCCS’10)., ENSAM University Moulay Ismail, Meknes Morocco.
7. M.B. MEDENI, El Mamoun SOUIDI. : LSB Steganography Method in gray scale image., 2ème Congrès de la Société Marocaine de Mathématiques Appliquées SM2A, à la Faculté des Sciences de Rabat, 28-30 juin 2010 Rabat-Morocco
8. M.B. MEDENI, El Mamoun SOUIDI. : Error-correcting codes in steganography., JDTIC’10 2010 : 2èmes Journées Doctorales en Technologies de l’Information et de la Communication, Faculty-DharMehraz- Fez-Morocco
9. Thierry P. Berger, M.B. Medeni. : Maximum likelihood decoding algorithm for some Goppa and BCH Codes. Application to the matrix encoding method for stegano-graphy., accepted for publication in IHTIAP 2012.
10. A. El Allati, M.B. Ould Medeni, and Y. Hassouni. : Quantum Steganography via Greenberger-Horne-Zeilinger GHZ4 State., Commun. Theor. Phys. vol. 57 PP.
577-582, (2012) .
11. S. M. Douiri, M. B. Medeni, S. Elbernoussi and El Mamoun Souidi. : A New Stegano-graphic Algorithm Using Graph Coloring Problem., Soumis à The Arabian Journal for Science and Engineering.
12. M. B. Medeni, S. M. Douiri, S. Elbernoussi and El Mamoun Souidi. : Graph Coloring and Steganography, Proceeding of the IEEE, the 3rd International Conference on Multimedia Computing and Systems (ICMCS’12), Tangier, Morocco, 2012.(IEEE Xplore, SCOPUS).
13. M.B. MEDENI, El Mamoun SOUIDI. : A Steganographic method for digital images using LSB substitution.,Workshop International Théorie des Nombres, Codes, Cryp-tographie et Systèmes de Communication 26-27 Avril 2012 Oujda-Morocco.
Introduction
La stéganographie est une science et un art utilisé depuis des siècles pour faire passer inaperçu un message secret dans un fichier anodin. Ce mot vient du grec " Stéganô ", qui signifie couvrir et " Graphô " qui veut dire écriture. Ainsi, on dissimule les informations que l’on souhaite transmettre confidentiellement dans un ensemble de données d’apparence anodine afin que leur présence reste imperceptible. Contrairement à la cryptographie, les informations sont cachées mais pas nécessairement chiffrées. Une fois la méthode de dis-simulation connue, tout le monde est capable de récupérer le message secret. Bien que considérées comme deux disciplines différentes, il est possible d’intégrer la cryptographie dans un message ; ainsi, la communication n’est pas seulement dissimulée mais également chiffré.
Dans son Enquête, l’historien grec Hérodote (484-445 av. J.-C.) rapporte ainsi une anecdote qui eut lieu au moment de la seconde guerre médique. En 484 avant notre 1ère, Xerxès, fils de Darius, roi des Perses, décide de préparer une armée gigantesque pour en-vahir la Grèce (Livre VII, 5-19). Quatre ans plus tard, lorsqu’il lance l’offensive, les Grecs sont depuis longtemps au courant de ses intentions. C’est que Démarate, ancien roi de Sparte réfugié auprès de Xerxès, a appris l’existence de ce projet et décidé de transmettre l’information à Sparte (Livre VII, 239) : " il prit une tablette double, en gratta la cire, puis écrivit sur le bois même les projets de Xerxès ; ensuite il recouvrit de cire son message : ainsi le porteur d’une tablette vierge ne risquait pas d’ennuis". Un autre passage de la même ?uvre fait également référence à la stéganographie : au paragraphe 35 du livre V, Histiée incite son gendre Aristagoras, gouverneur de Milet, à se révolter contre son roi, Darius, et pour ce faire, "il fit raser la tête de son esclave le plus fidèle, lui tatoua son message sur le crâne et attendit que les cheveux eussent repoussé ; quand la chevelure fut redevenue normale, il fit partir l’esclave pour Milet".
L’introduction de cette problématique dans les thèmes de recherches académiques doit beaucoup à G. Simmons et son problème des prisonniers (cf. [23]). Simmons envisage le cas de deux prisonniers autorisés à échanger des messages authentifiés, mais non chiffrés. L’al-gorithme d’authentification est connu et le but des prisonniers est d’échanger des messages planifiant une évasion. Lors de la parution de [23], la question des fuites d’information se posait déjà très fortement et le même auteur détaille dans [47] la manière dont les États-Unis et l’Union soviétique, à la fin des années 1970, au cours de négociations sur un traité de non prolifération des armes nucléaires 1, se sont trouvés confrontés au problème
de connaître très précisément quelles données pouvaient être émises par un détecteur. Les protagonistes étudiaient un dispositif devant permettre de détecter la présence de missiles dans les silos, sans révéler les emplacements de ces derniers. Parmi les contraintes impo-sées, il devait être impossible de modifier l’information émise et également impossible de transmettre plus que le strict nécessaire. Simmons explique, dans [44], de quelle façon il a été amené à étudier ce dispositif et à constater qu’il était possible de transmettre une dizaine de bits sans que cela soit détectable. Ajoutons que cette forme particulière de stéganographie, la dissimulation de messages dans les communications authentifiées, est appelée canal subliminal.
De nombreux intérêts, industriels notamment, ont poussé au développement du do-maine de la dissimulation de l’information. La stéganographie, le tatouage et le filigrane
2. La stéganographie fait partie du domaine de la dissimulation d’information comme
l’illustre la Figure 1 :
1. la stéganographie : c’est la dissimulation de l’information avec pour objectif de cacher l’existence du message donc personne ne peut voir qui’il y a un message. Lorsqu’une personne non autorisée tente uniquement de détecter la présence d’un message dans un cover-medium transmit par un canal de communication, elle est dite passive. La plupart des solutions de stéganographie considèrent exclusivement ce type d’attaquant. Toutefois, il peut aussi être actif : il sait que le stégo-medium contient de l’information. Il tente de la modifier ou de l’extraire.
1Strategic arms limitations talks two (SALT 2), traité qui n’a pas été ratifié.
2Nous avons choisi de traduire ainsi respectivement watermarking et fingerprinting. Signalons que le
2. Le tatouage a une portée commerciale. Il tente de protégé les droits d’auteurs. A pour objet de permettre l’identification de l’entité à l’origine du document, cela correspond précisément au copyright. Des données sont insérées dans les documents, de manière plus ou moins discrète, l’essentiel étant de ne pas nuire à l’usage du document. Ces données doivent être difficiles à retirer. Plus précisément, réussir à les enlever doit aboutir à un document très dégradé. Toutes les copies d’un même document d’origine sont rigoureusement identiques. L’insertion du tatouage doit limiter les modifications subies par le médium. Par suite, chaque copie du stégo-medium contient une marque identique : celle du propriétaire légal. Il ne s’agit pas de dissimulation à proprement parler. La présence du tatouage dans le stégo-medium est connue. Cependant cette connaissance est insuffisante. L’effet a obtenir est préventif. Les modifications apportées au stégo-medium tatoué attestent d’une contre façon.
3. Le fingerprinting assure la détection des copies illégales d’un stégo-objet. Chaque uti-lisateur authentifié reçoit sa propre copie du document qui contient une empreinte : l’identifiant. Ainsi, lorsqu’une copie illégale est découverte, la lecture de l’empreinte indique la source de la fuite. A la différence du tatouage où l’origine du médium est déterminante, le fingerprinting se préoccupe du destinataire . Chaque copie du médium contient une information différente, relative à son utilisateur, rendant alors chaque stégo-objet unique.
La stéganographie présente donc un point commun important avec le tatouage et Le fingerprinting : on dispose d’un document et on souhaite y incorporer une information additionnelle sans détériorer de manière notable le document d’origine. Les techniques intervenant lors de cette insertion varient donc très peu d’un domaine à l’autre. Cependant, le cahier des charges de la stéganographie diffère légèrement de celui du tatouage ou du filigrane : la dissimulation tient une place plus centrale tandis que d’autres propriétés ne sont pas requises.
Contrairement aux chiffrements, qui s’appliquent sans réserve à tout type de données numériques, les algorithmes stéganographiques sont tributaires du format des documents numériques dans lesquels doit avoir lieu l’insertion. Le document d’origine doit être modifié de manière indétectable, ce qui implique de se restreindre à des zones particulières, qui dépendent naturellement du type de document. Le cadre dans lequel nous nous plaçons, et que nous détaillons dans les chapitres, s’applique aux images, en noir et blanc, en niveau de gris ainsi qu’en couleurs. Nous verrons qu’il est également possible d’appliquer la stéganographie à tout type de document comportant une partie "relativement" aléatoire. Le premier (le tatouage) a pour objet de permettre l’identification de l’entité à l’origine du document, cela correspond au copyright. Des données sont insérées dans les documents, de manière plus ou moins discrète, l’essentiel étant de ne pas nuire à l’usage du document. Ces données doivent être difficiles à retirer. Plus précisément, réussir à les enlever doit aboutir à un document très dégradé. Toutes les copies d’un même document d’origine sont rigoureusement identiques. Tout comme le tatouage, Le fingerprinting a également un but d’identification, mais il ne s’agit plus d’identifier l’émetteur : on souhaite marquer chaque copie distribuée de manière unique. Le filigrane joue donc le rôle de numéro de série. La principale contrainte reposant sur le filigrane est la résistance à la contrefaçon. L’accès à plusieurs copies, comportant chacune une marque différente, ne doit pas permettre de fabriquer une nouvelle copie avec une marque valide. Une copie ainsi formée doit permettre d’identifier au moins l’une des copies ayant servi à sa construction. Cela impose, comme pour le tatouage, une certaine robustesse de l’insertion des filigranes ainsi qu’une importante furtivité.
Les codes correcteurs d’erreurs sont utilisés dans la communication numériques pour protéger les données numériques contre les bruits lors de la transmission à travers un canal de communication, de plus les codes correcteurs d’erreurs permettent aussi la protection
de données lors de leur stockage. Mais ils peuvent encore être employés en cryptographie. Ils sont dans ce contexte un outil permettant, de chiffrer des données et d’authentifier des personnes. Le domaine de la cryptographie basé sur le codes correcteurs d’erreurs est vu le jours après l’invention du premier cryptosystème à clef publique par Diffie et Hellman [50], cette nouvelle branche de la cryptographie moderne, à donné l’idée au mathématicien français R. J. McEliece [51] pour imaginer le premier et le plus célèbre des cryptosystèmes à clef publique utilisant des codes correcteurs d’erreurs. la théorie des codes contient elle aussi de multiples problèmes difficiles à résoudre dans un temps polynomial, plus ou moins bien adapté pour une utilisation en cryptographie. Notons quand même que les codes ont aussi beaucoup d’applications dans d’autres domaines parmi eux la stéganographie, en général l’implémentation de la stéganographie avec les codes correcteurs d’erreurs est connu sous le nom codage matriciel (en anglais : "Matrix encoding" ou "Syndrome co-ding"), a été introduite en stéganographie par Cranddall [10] en 1998. L’implémentation a ensuite été proposée par Westfeld avec l’algorithme de stéganographie F5 [1]. L’objectif est toujours le même (une image, audio, vidéo,etc ...) en modifiant celle-ci, mais avec la contrainte de minimiser le nombre de modifications introduites dans le fichier. L’insertion est basée sur le calcul de syndrome, mais le but est d’obtenir une efficacité d’insertion (e = nombre de bits du message/nombre de coefficients modifiés) meilleure que celle trouvée par les algorithmes précédents . Une autre évolution de stéganographie avec les codes a été également proposée à travers les "codes à papier mouillé" [88], et consiste à sélectionner les sites d’insertion du côté codeur, mais avec un décodeur ignorant les sites sélectionnés. Cet axe de recherche est présenté dans le chapitre 1 et bien détaillé avec la présentation des schémas stéganographiques très efficaces réalisés grâce aux codes correcteurs d’erreurs. Tout au long de cette thèse, nous traitons la problématique de dissimulation d’infor-mation par ses liens avec les codes correcteurs d’erreurs. Nous modélisons le problème auquel nous sommes confrontés. Nous commençons notre étude en nous préoccupant uni-quement de la dissimulation : notre seule contrainte est donc de minimiser le nombre de changements nécessaires dans l’objet de couverture pour l’insertion des messages. Afin de construire ces protocoles, nous devons construire des boules centrées en mot du codes deux à deux disjoints dont la réunion soit l’espace tout entier, Fn
q. Une solution consiste à
réunion nous donne bien l’espace Fn
q. Ensuite nous abordons le problème de la capacité de
messages à dissimuler. Notre problème est alors, pour une longueur n donnée, d’essayer de maximiser le nombre de messages dissimulables lorsque la distorsion maximale est fixée. Nous proposons ensuite, un nouveau schéma stéganographique pour les images en niveau de gris en utilisant la coloration de graphe. Nos travaux étaient plus concentrés sur les codes correcteurs d’erreurs et ses applications en stéganographie.
Et voici un résume de mes contributions par thèmes :
– Codes correcteurs d’erreurs : (Construction and Bound on the Performance of Matrix-Product Codes [65]) : Dans ce travail, nous considérons la construction produits de codes et matrice [c1, · · · , Cs].A, où C1, · · · , Cs sont des codes linéaires et A est une
matrice de plein rang. Nous montrons comment nous calculons la dimension, la distance minimum et de plus nous vérifions plusieurs bornes pour ce type de codes – Stéganographie basées sur les codes :
– A Novel Steganographic Protocol from Error-correcting Codes [64] : Cet article présente un nouveau schéma stéganographique, basé sur le décodage par décision majoritaire, d’un code correcteur d’erreur. Comme application on prend un code BCH correcteur d’ erreurs.
– Maximum likelihood decoding algorithm for some Goppa and BCH Codes. Ap-plication to the matrix encoding method for steganography [60] : Le but de cet article est de transformer certains algorithmes de décodage algébrique jusqu’à la capacité de correction d’erreur dans un décodeur de maximum de vraisemblance par l’utilisation d’une recherche exhaustive limitée. Ensuite on a proposé une ap-plication de ce décodage en stéganographie
– A novel steganographic method for gray-level images with four-pixel differencing and LSB substitution [58] : Dans cet article nous proposons une méthode de stéganographie pour cacher des informations dans le domaine spatial i.e ( les images en niveaux de gris). La méthode proposée fonctionne en divisant l’image de couverture en blocs de même taille et incorpore ensuite le message dans chaque pixels du bloc sélectionné en fonction du nombre de uns dans les quartes bits à gauche
– Stéganographie et la théorie de graphe [73] : on s’est intéressé à utiliser quelques techniques de la théorie de graphe connu pour leur rapidité et optimalité en
sté-ganographie, pour cela on suppose que l’image de couverture est un graphe et les sommets sont les pixels de l’image, sous cet angle on a proposé deux travaux en stéganographie.
– Stéganographie Quantique [74] : Un système de communication quantique stéga-nographie via Greenberger-Horne-Zeilinger GHZ4 Etat est construit pour étudier la possibilité de transférer des informations cachées à distance. En outre, les États multi-partites intriqués sont devenus un sujet mouvementé en raison de ses applica-tions importantes et des effets profonds sur les aspects de l’information quantique. le protocol proposé consiste à partager la corrélation de quatre particules GHZ4 états entre les utilisateurs légitimes.
Chapitre 1
Codes Correcteurs d’erreurs
Dans ce chapitre nous rappelons les notions nécessaire pour la construction des bons schémas stéganographiques. Nous commençons par des rappels sur la théorie des codes, notamment les codes linéaires en bloc avec lesquelles nous aurons à travailler avec une rapide discussion sur les problèmes de décodage. Ensuite dans la section nous présentons en détail le domaine de la stéganographie. Ce chapitre se termine par une définition formelle du protocole ou schémas stéganographique réalisé à partir des codes correcteurs d’erreurs (Matrix Encoding).
1.1
Codes Linéaires
Un code correcteur est un ensemble des techniques de codage basé sur la redondance. Celle-ci est destinée à corriger les erreurs de transmission d’une information (le plus sou-vent appelée message) sur un canal de communication non suffisamment fiable. La théorie des codes correcteurs ne se limite pas qu’aux communications classiques (radio, câble co-axial, fibre optique, etc.) mais également aux supports pour le stockage comme les disques compacts, la mémoire RAM et d’autres applications où l’intégrité des données est impor-tante.
Définition 1.1.1 (Code linéaire). Soit Fq un corps fini. Un code linéaire C de longueur
n sur Fq est un sous espace vectoriel de Fnq. On l’appele [n, k] − C
Définition 1.1.2 (Matrice génératrice). On appelle matrice génératrice G d’un [n, k] code
Une autre matrice très utile est la matrice H, appelée matrice de contrôle ("parity-check matrix" en anglais). On la définit de la façon suivante :
Définition 1.1.3 (Matrice de contrôle (parity-check matrix) ). Une matrice de contrôle H
d’un [n, k]-code linéaire est une matrice de taille (n−k)×n, avec n−k lignes linéairement indépendantes, telle que chaque ligne de G est orthogonal à toutes les lignes de H.
Définition 1.1.4 (Codes équivalents) Soient C et C0 deux codes linéaires sur F
q de
ma-trices générama-trices G et G0 respectivement. Les codes C et C0 sont dit équivalents s’il existe
une matrice de permutation P telle que
G0 = G × P (1.1)
Définition 1.1.5 (Distance de Hamming). Soient u, v ∈ Fn
q. la distance de Hamming
entre u et v, notée dH(u, v), est donné par l’expression suivante :
dH(u, v) = #{i : ui 6= vi}
où # désigne le cardinal
Exemple 1.1.1 Considérons les mots binaires u = (0010110) et v = (1000101). On a
alors : dH(u, v) = 4.
Définition 1.1.6 (Poids d’un mot).
Soit v un mot de l’espace Fn
q, le poids de Hamming de v, noté w(v), est défini comme
suit :
w(v) = #{i : vi 6= 0}
Exemple 1.1.2 Si on reprend les exemples ci-dessus, on a : w(u) = 3 et w(v) = 3 Remarque 1.1.1 La distance de Hamming entre u et v est égale au poids de Hamming
de u − v c-à-d : dH(u, v) = w(u − v).
Définition 1.1.7 (Distance minimum d’un code).
La distance minimum d’un code C, notée d, est le minimum des distances de Hamming entre les mots du code. On a donc :
Proposition 1.1.1 (Borne de Singleton).
Soit C un [n, k] code de distance minimal d. L’inégalité suivante est appelé borne de singleton : d ≤ n−k+1. Cette borne permet de trouver une borne maximale sur la distance minimale d par rapport aux valeurs n et k.
On pose t = bd−1
2 c, t s’appelle capacité de correction
Proposition 1.1.2 (Borne de Hamming). Soit un [n, k, d]-code linéaire C défini sur Fq.
La borne de Hamming est :
qk ≤ t X i=0 µ t i ¶ (q − 1)i ≤ qn
Définition 1.1.8 (Code Parfait). Un code est dit parfait si la borne de Hamming est une
égalité, c’est-à-dire si : t X i=0 µ t i ¶ (q − 1)i = qn
Définition 1.1.9 (Code MDS). Un code est dit MDS (Maximum distance separable) si
la borne de Singleton est une égalité, c’est-à-dire si : d = n − k + 1
Définition 1.1.10 Soit C un [n, k]-codes linéaire et s ∈ Fn−k
q , l’ensemble C(s) = {x ∈
Fn
q|x × Ht= s} est appelé translaté de C, on a C(0) = C, et si deux vecteurs x, y ∈ Fn−kq
tel que x 6= y alors C(x) 6= C(y). De plus toutes translaté peut écrit sous la forme C(s) = x + C, x ∈ C(s)
x quelconque.
L’élément de plus petit poids dans C(s) est appelé représentant de classe et sera notée
eL(s).
Définition 1.1.11 Soient C un Code linéaire définit sur Fn
q et v ∈ Fnq , on définit la
distance de v à C de la manière suivante :
Définition 1.1.12 (Rayon de recouvrement). Soit C un [n, k]-code linéaire, le rayon de
recouvrement de C, noté ρ, est définit comme la plus grande distance entre les points de l’espace ambiant du code et le code :
ρ = maxv∈Fn
q{d(v, C)}
Remarque 1.1.2 On peut également voir le rayon de recouvrement ρ comme le plus petit
rayon tel que toutes les boules de rayon ρ centrées en les mots du code recouvrent totalement l’espace ambiant, ce qui explique son nom. De plus on peut voir le code parfait d’une autre façon grace à la définition du rayon de recouvrement.
Proposition 1.1.3 Soient C un code, t = bd−1c2 la capacité de correction et ρ le rayon de recouvrement de C. Le code C est un code parfait si
t = ρ
1.2
Détection et correction des erreurs
L’encodage d’un mot u ∈ Fn
q s’effectue en transformant le vecteur u en un mot du
code c de longueur n tel que :
c = u × G
Puis on envoie c au travers du canal. A la sortie du canal, on reçoit un mot r. L’objectif du décodeur est de reconstruire le mot qui a été envoyé à partir du mot reçu. Le décodeur il cherche d’abord à détecter s’il y a eu une erreur, puis dans un deuxième temps, il cherche à corriger cette ou ces erreurs.
Une méthode pour détecter la présence d’erreurs et de calculer le syndrome :
s = r × Ht (1.2)
Si le syndrome s est égal au vecteur nul, étant donné que le produit d’un des mots du code C avec la transposée de la matrice de contôle est nulle, on peut déduire que r est un mot appartenant au code C. Le récepteur va alors considérer qu’il n’y a pas d’erreur, et qu’il s’agit du mot envoyé.
Si le syndrome est différent du vecteur nul, cela signifie que le mot reçu r n’est pas un mot du code C. Par conséquent, on est sûr qu’une erreur ou plus est apparue lors de la transmission. Le but du décodeur va donc être de trouver où se situe cette erreur et de la corriger.
Voyons plus précisément le cas des codes binaires : On pose e = (e0, e1, · · · , en−1), le
vecteur d’erreur, représentant les erreurs ayant été introduite par le canal. Ce vecteur a des zéros partout sauf aux positions où une erreur s’est produite. On a alors :
r = c + e (1.3) Le syndrome s est alors égal à :
s = (c + e) × Ht (1.4) s = c × Ht+ e × Ht (1.5) or c × Ht= 0 (1.6) donc on a : s = e × Ht (1.7)
On peut donc calculer les syndromes possibles à partir des vecteurs d’erreurs et consti-tuer une table associant à chaque erreur pouvant apparaître dans le canal le syndrome que l’on obtiendrait. Ainsi lors du décodage, on pourra comparer s avec les entrées de la table et retrouver le vecteur erreur. Lorsque e est connu, on retrouve facilement c en calculant :
c = r + e
1.3
Codes de Hamming
Le code de Hamming est un code binaire défini [15] par sa matrice de parité plutôt que par sa matrice génératrice. C’est la matrice de dimension r × (2r − 1) qui contient toutes
les colonnes non nulles distinctes que l’on peut écrire sur r bits. Le code de Hamming est donc l’ensemble des mots de longueur 2r− 1 dont le noyau est H. C’est donc un espace de
dimension 2r− 1 − r. De plus, la distance minimale de ce code est 3 car il n’existe aucun
mot de code de poids 1 ou 2 puisque cela signifierait qu’il y a une colonne nulle ou deux colonnes égales dans H. On a donc un code [2r− 1, 2r− 1 − r, 3] dans lequel on doit donc
pouvoir décoder une erreur.
1.4
Codes de Reed-Solomon
Les codes de Reed-Solomon ont été développés par I. Reed et G. Solomon indépen-damment dans les années 50 [95] mais avaient déjà été construits par Bush [96] un peu avant, dans un autre contexte. Ces codes sont certainement les codes par blocs les plus utilisés pour la correction d’erreurs en dans les CD, les DVD et la plupart des support de données numériques. Ils sont très utilisés car ils sont extrêmaux du point de vue de la capacité de correction.
La façon la plus simple de voir ces codes est en tant que code d’évaluation : chaque élément du support du code est associé à un élément du corps Fq sur lequel est défini
le code et chaque mot de code est l’évaluation d’une fonction f ∈ Γ sur le support. Pour construire un [n, k]- codes de Reed-Solomon on prend Fq = F2m, Γ l’ensemble des
polynômes de degré strictement inférieur à k sur F2m, et une racine primitive n-iémes de
l’unité α. Ainsi on a bien un code linéaire de longueur n ≤ 2met dimension k. Une matrice
génératrice du code peut alors s’écrire :
G = 1 1 · · · 1 α1 α2 · · · αn α2 1 α22 · · · α2n ... ... ... ... αk−11 αk−12 · · · αk−1 n
Par sa nature, ce code a une distance minimale égale n − k + 1 car deux polynômes de degré < k distincts ne peuvent pas être égaux en plus de k − 1 positions distinctes. Cette distance est même exactement égale à n − k + 1 puisque l’évaluation d’un polynôme de la forme Qk−1i=1(X − αi) est de poids n − k + 1. On a donc des codes sur F2m de la
une bonne capacité de correction. Notons que cette distance minimale est la meilleure que l’on puisse atteindre avec ces paramètres : une distance minimale supérieure entrerait en contradiction avec la dimension du code.
Définition 1.4.1 Un code cyclique de longueur n sur Fq avec le polynôme générateur g
est défini comme étant l’idéal engendré par g dans l’anneau quotient Fq[x]/(xn− 1)
1.5
Codes BCH et Goppa
Les codes BCH (Bose, Chaudhuri, Hocquenghem) sont des codes cycliques particuliers qui permettent de prévoir la distance minimum avant la construction.
Theorem 1.5.1 Soit C un code cyclique de longueur n sur Fq, de polynôme générateur
g(x) où n est premier avec q. Soit L le corps des racines n-ièmes de l’unité sur Fq, (Corps
de décomposition de xn− 1 sur F
q). Soit δ un entier au moins égal à 1, et β une racine
primitive n-ièmes de l’unité dans L, δ − 1 puissances de β dont les exposants sont des entiers consécutifs (modulo n), soit βr, βr+1, · · · , βr+δ−2, alors le poids minimum du code
C est au moins δ.
Exemple 1.5.1 La décomposition de x9− 1 sur F 2 est :
x9− 1 = (x − 1)(x6+ x3+ 1)(x2+ x + 1)
Les classes cyclotomiques sont : {0}, {1, 2, 4, 8, 7, 5} et {3, 6}. Donc g(x) = x6+ x3+ 1 a
pour racine dans L = F64, les éléments β, β2, β4, β8, β7, β5. (β racine primitive 9-ièmes
de l’unité, par exemple β = α7, avec α racine primitive de L). Le poids minimum du code
cyclique C, de générateur g(x) est donc au moins 3.
Remarques 1.5.1 1. Le théorème donne une borne inférieur, (soit δ) du poids mini-mum de C. Il arrive assez souvent que ce poids minimini-mum soit strictement supérieur à δ. Dans l’exemple précédent, le poids minimum est exactement 3, car le mot associé à g(x) lui-même est de poids 3. Le code C est donc 1-correcteurs
2. Le théorème permet de trouver un code corrigeant e erreurs sur Fq, pour n’importe
quel entier e. Il suffit de trouver n tel qu’un diviseur de xn− 1 satisfasse aux
le produit des diviseurs de xn− 1 sur F
q qui ont pour racines β, β2, · · · , βδ−1, avec
δ = 2e + 1 ou 2e + 2, mais dans ce cas, la longeur n et la dimension k du code ne peuvent être choisies arbitrairement.
Définition 1.5.1 Pour r fixé, le diviseur g(x) de xn−1 cherché, pour assurer la borne du
théorème doit avoir pour racines βr, βr+1, · · · , βr+δ−2 mais aussi, puisqu’il est à coefficients
dans Fq, les conjugués de chacune de ces racines. Le polynôme de plus petit degré (donc
correspondant à la plus grande dimension pour le code) satisfaisant à cette condition est le produit des polynômes minimaux de βr, βr+1, · · · , βr+δ−2 [15], chacun d’eux n’apparaissant
qu’une fois dans le produit.
Définition 1.5.2 Un code BCH de distance construite δ est un code cyclique dont le
générateur est le produit des polynômes minimaux de βr, βr+1, · · · , βr+δ−2 pour un entier
r donné (sans répetition de facteurs). Dans le cas r = 1, on dit que le code est un code BCH au sens strict
Remarque 1.5.1 Comme il a déjà été dit, le poids minimum peut être meilleur que la
distance construite. La construction nous assure seulement que le poids minimum est au moins la distance construite, ce qui est souvent satisfaisant.
Définition 1.5.3 Pour définit un code de Goppa on à besoins, des données suivantes :
– Un corps Fq à q éléments. De plus q est un puissance d’un nombre premier q = pm;
– un polynôme G ∈ Fq[x] ;
– Un ensemble L = {β1, β2, · · · , βn} de Fq tel que G(βi) 6= 0 pour tout 1 ≤ i ≤ n
Le code C = Γ(L, G) est l’ensemble des vecteurs c = (c1, c2, · · · , cn) ∈ Fnq tels que la
fraction rationnelle Rc(X) = n X i=1 ci X − βi
ait un numérateur multiple de G(X). La longueur de ce code est n ; si r = degG, on peut démontrer que sa dimension k et sa distance minimale d vérifient k > n − mr et d > r + 1.
Chapitre 2
Stéganographie et Stéganalyse
Ce chapitre présente succinctement les grandes lignes des étapes qui composent la compression JPEG. Son objectif est de permettre la compréhension des techniques de stéganographie et de stéganalyse adaptées au format JPEG [80]. Dans cet esprit, certaines approximations ont été effectuées et certains détails techniques ont été omis. Les parties concernant le format JPEG et les démarches utilisées dans la construction des ces images sont tirer de [100, 84]. D’autre part, nous présentons en détail avec des exemples et des tests aussi les deux algorithmes de stéganalyse qui sont les plus connues [85, 48]
2.1
La Stéganographie
La stéganographie est l’art de la dissimulation de communications. Contrairement à la cryptographie, la stéganographie n’a pas pour objectif de sécuriser une communication, mais d’en cacher l’existence même. Les deux disciplines ont donc chacune leur propre domaine de compétence. Dans certaines situations, le faite même de vouloir transmettre des données de manière chiffrée sera jugé comme suspect. De la même manière, de plus en plus de pays mettent en place de forte restriction concernant la longueur des clés cryptographiques, ainsi que la cryptographie en elle même.
Le regain d’intérêt actuel pour la stéganographie provient de ces restrictions imposée à la cryptographie. D’une manière générale, la stéganographie arrive en renforcement au chiffrement de données. Pour permettre de garantir une confidentialité maximum, les données sont tout d’abord chiffrées avant d’être dissimulées à l’aide d’un processus stéganographique.
Personne ne sachant réellement répondre à la question "Quelles informations sont-elles réellement récoltée sur moi sur Internet ?", la stéganographie vient comme un moyen de pouvoir avoir contrôle de ce que nous laissons transparaître vers l’extérieur. A une époque ou l’on arrive plus à estimer la puissance de certaine agence de renseignement, ni à connaître leur véritable capacité, il semble légitime de s’assurer que notre vie privée soit respectée.
Dans cette section, nous présentons tout d’abord un historique des techniques de sté-ganographie pour bien cerner la philosophie du domaine et les concepts d’emploi. Nous posons ensuite les bases de la stéganographie moderne et mettons en évidence les proprié-tés intrinsèques des schémas de stéganographie. Nous en déduisons ainsi les services de sécurité offerts par de telles techniques ainsi que les règles fondamentales de leur mise en œuvre.
2.1.1
Histoire de la stéganographie
Bien que ce qui nous intéresse ici est en rapport avec l’informatique il peut être intéres-sant de revenir un peu en arrière pour connaître l’origine de la stéganographie [100]. Ainsi on se rend compte que la première forme de stéganographie répertoriée nous vient d’une histoire Grecque signé Hérodote et datant du 5ème siècle avant Jésus-Christ. L’auteur nous relate la révolte contre les lois Perses. Afin de communiquer secrètement deux chefs de guerre utilisèrent des esclaves. Ils leurs tatouaient sur le crâne le message et ensuite les cheveux repousser. L’esclave était ensuite envoyé chez le correspondant trompant ainsi l’ennemi. Une fois rasé le message était parfaitement lisible. Bien que très rudimentaire, cette méthode est un assez bon symbole de ce qu’est la Stéganographie. Au fils du temps, la Stéganographie a été très souvent employée et s’est ouverte à un grand nombre de formes. Une représentation chronologique, illustrée à la page 10, retrace certaines de ses utilisations dans l’histoire. Certaines d’entres elles seront détaillées par la suite.
Les Grecs utilisaient certains esclaves pour transmettre les messages. Ceux-ci étaient écrits sur les crânes des messagers, et passaient donc inaperçu lorsque les cheveux repous-saient. Une fois suffisamment longs, le messager pouvait être envoyé, avec l’ordre de se faire raser le crâne une fois arrivé à destination. Le principal désavantage de cette méthode était l’attente pour l’envoi d’un message. Une autre technique était d’utiliser des tablettes de cire. Une fois la cire raclée, on gravait le message dans le bois de la tablette. Il suffisait
ensuite d’y remettre de la cire, et le message était parfaitement caché.
En Chine ancienne, les messages étaient écrits sur de la soie, qui était ensuite roulée en boule, elle même recouverte de cire. Un messager devait enfin avaler cette boule. Dès le Ier siècle av. J.-C. Les romains utilisaient l’encre invisible, qui fut la plus utilisée des méthodes de stéganographie à travers les siècles. On écrit, au milieu des textes écrits à l’encre, un message à l’aide de jus de citron, de lait ou de certains produits chimiques. Il est invisible à l ? ?il, mais une simple flamme, ou un bain dans un réactif chimique, révèle le message.
Un scientifique allemand, Gaspart Schott (1608-1666) explique dans son livre Schola Steganographica comment dissimuler des messages en utilisant des notes de musique. Souvent taxés d’ésotérisme, certains de ces ouvrages, à l’instar de Steganographia ont été interdits en leur temps. Néanmoins, l’intérêt vif du public pour les sciences du secret a rendu possible la diffusion de ces livres sous le manteau.
2.1.2
La Stéganographie Moderne
la stéganographie dite moderne, c’est-à-dire adaptée aux données numériques, est re-lativement jeune. En pleine expansion, elle suit depuis le milieu des années 90 un essor corrélé é celui d’Internet. La première étape est bien évidemment de définir précisément l’objet que l’on va étudier. Le lecteur pourra se référer à d’excellents ouvrages [76], [91], [101] traitant de dissimulation d’information. Bien que la communauté des stéganographes se soit constituée dans les années 90, G. J. Simmons pose en 1983 le socle de la stéganogra-phie moderne [23] en définissant la notion de canal subliminal. Pour illustrer son propos, il reprend le problème de deux prisonnier. Deux prisonniers souhaitent établir un plan d’évasion. Pour ce faire, ils ont la possibilité de se transmettre des messages. Cependant, ces messages transitent à travers le gardien, qui a donc accès au contenu. Tout contenu jugé inapproprié sera détruit, et pourra engendrer une lourde sanction. Dans cette optique, le contenu doit donc paraître anodin au yeux du gardien. Cette situation rend inutilisable la cryptographie, car un contenu indéchiffrable attirera l’attention du geôlier. La stégano-graphie a donc comme objectif de pouvoir entretenir des communications sécurisés, sans pour autant attirer l’attention d’autrui.
2.1.3
Architectures Stéganographique
Dans une architecture stéganographique, il y a principalement deux éléments. D’un côté un processus de dissimulation, de l’autre un processus de recouvrement. Un processus de dissimulation simplifié peut être donné par le schéma suivant :
Fig. 2.2 – Schéma simplifié de Stéganographie [18]
Il existe trois type de protocoles de stéganographie, correspondant de près à ce qui existe en cryptographie.
La stéganographie pure est un système dans lequel le secret de dissimulation des don-nées ne réside que dans l’algorithme utilisé à cet effet. La découverte de cet algorithme rompt la dissimulation de la communication. Ceci revient à mettre en place de la "sécurité par l’obscurité".
La stéganographie à clé secrète est similaire à la cryptographie symétrique, l’échange de données confidentielles nécessite, au préalable, l’échange d’une clé secrète que l’on ne partagera que avec notre interlocuteur. Il est donc nécessaire d’avoir un canal sécurisé, ou de rencontrer en personne notre interlocuteur, afin d’être certain que cette dernière ne soit pas compromise. Cette clé aura une influence sur la manière de "cacher" l’information.
La stéganographie à clé public, quant à elle, est similaire à la cryptographie asymé-trique. La personne voulant envoyer des données à un autre interlocuteur, sans éveiller de soupçons, utilisera la clé public de ce dernier. La clé public étant à priori connue de tout le monde, il n’y aura pas besoin d’échange préalable "sécurisé". La personne recevant ce message sera la seul à pouvoir en extraire son contenu à l’aide de sa clé privée.
Voici un schéma plus complet du processus stéganographique :
Fig. 2.3 – Schéma complet [18]
2.1.4
Caractéristiques de Schéma Stéganographique
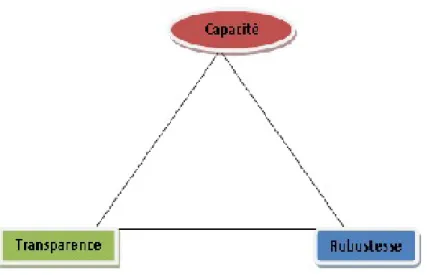
Trois critères permettent de classer les algorithmes stéganographique : La capacité, la transparence et la robustesse.
1. La capacité correspond à la taille de données qui peut être incorporé dans l’objet de couverture, relativement à la taille de celui-ci,
2. La transparence ou l’imperceptibilité dépende directement à la distorsion introduite par le processus de dissimulation pendant l’insertion de données, la distorsion est
tous simplement les nombres de modification ou de changement dans l’objet de couverture,
3. La robustesse signifie la résistance de notre stégo-objet, c-à-d rester normale même s’il subit des transformation (filtrage, etc...).
Fig. 2.4 – Triangle des caractéristiques
Ces trois critères ne peuvent pas être maximisé simultanément. Chacun d’entre eux aura une influence sur l’autre. Par exemple, la capacité va en contradiction avec la trans-parence. Sur la Figure (2.4), des outils ont été placés afin d’en définir la caractéristique principale.
Les outils de stéganographie dit naïfs correspondent à la grande majorité des outils disponibles sur internet. Ils cachent les informations dans les conteneurs sans réellement se préoccuper de la facilité à détecter ces données, ni les influences que ces données peuvent avoir sur le conteneur d’un point de vue statistique.
Les outils de stéganographie académique sont quant à eux développé par des équipes de recherches (notamment l’équipe de Fridrich). Leur objectif est de faire évoluer en
paral-lèle stéganographie et stéganalyse. Leur objectif principal est d’arriver à des algorithmes totalement transparents (pour les méthodes actuelles), afin de pouvoir en déduire des méthodes de stéganalyse encore plus performantes. De récentes recherche portent sur la maximisation de l’espace de dissimulation disponible. Ces outils arriveront peut-être à allier transparence à capacité dans un avenir proche.
Pour finir, les outils de watermarking, utilisés principalement pour la protection de droit d’auteur, sont principalement développé afin d’avoir une très grande robustesse. Contrairement à la stéganographie, leur adversaires sont de type actif. Le contenu du watermarking ne leur servant en rien, leur unique objectif est la suppression pur et simple de ce dernier.
2.1.5
Techniques Stéganographiques
La Stéganographie est une science pour cacher les données secrètes dans des fichiers informatiques comme des couvertures et les fichiers les plus utilisés sont les fichiers textes (ce fut une des premières formes de la stéganographie), les images, fichiers audio ...etc, il est aussi possible de cacher des informations dans bien d’autres types de fichiers couramment échangés sur des réseaux tel la vidéo ou bien dans des zones d’un disque dur inutilisées par le système de fichiers, et même dans des protocoles informatiques comme IP et TCP. Il existe plusieurs techniques pour mettre en place des schémas stéganographiques. Nous commencerons donc ici par décrire ces techniques en fonction du support de couvertures, puis nous allons détailler la méthode LSB pour les images et les fichiers sons.
1. La stéganographie sur images :
– Usage des bits de poids faible d’une image (LSB) – Manipulation de la palette de couleurs d’une image – Message caché dans les choix de compression d’une image 2. Dans un texte :
– Modulation fine d’un texte – Marquage de caractères
– Codage sous forme d’une apparence de spam 3. dans un son :
– Dans les fichiers son, il existe à peu près les mêmes possibilités de cacher des messages que dans les fichiers images.
4. Fichiers HTML,
5. Canaux cachés HTTP, anaux cachés IP, anaux cachés TCP, anaux cachés DNS 6. Rajout de données (EOF, en-têtes, ...) : Les données cachées consistent en un fichier
image rajouté juste sous le marqueur EOF d’un fichier
Ces six points peuvent être regroupé en deux catégories distinctes. la technique dite de fusion et la modification LSB.
Ces deux techniques vont être détaillée ci-dessous. LSB (Least Significant Bit)
La stéganographie LSB (Least Significant Bit) consiste à dissimuler l’information dans des bits de poids faibles d’un support. Cette technique est un cas particulier de sté-ganographie +/ − k, qui incrémente ou décrémente les valeurs du support de +/ − k. Historiquement, peut-être par facilité d’implémentation, la stéganographie LSB adaptée aux images fixes non compressées est l’une des premières techniques stéganographiques et peut-être même l’une des plus employées encore aujourd’hui.
Utiliser LSB revient à remplacer certaines données déjà présentes dans un fichier par l’information à cacher. Cette méthode peut sembler simpliste, mais il faut faire attention à ne pas supprimer de données importantes qui rendraient impossible la lecture du stégo-objet final. Typiquement, on substitue les données non primordiales par notre message. Le destinataire extrait l’information s’il a connaissance des positions où le message a été substitué. Puisque seules des modifications mineures ont été apportées dans le processus d’encapsulation, l’émetteur présume qu’elles ne seront pas détectées par un attaquant passif.
Un exemple typique de ce procédé est l’application d’une image 24-bits au format BMP non compressée (voir section Format d’image). Une clé secrète k détermine, dans une zone de l’image, l’emplacement des pixels. La luminance de chaque pixel est codée par une valeur comprise entre 0 (soit en binaire : 00000000), et 255 (soit en binaire : 11111111). Le bit de poids faible de l’écriture binaire,
Algorithme général de la méthode de substitution de poids faible. for i = 1, ..., l(c) do
si ← ci
end for.
for i = 1, ..., l(m) do
compute index j, where to store ith message bit .
sij ← cij = mij
end for.
Encapsulation du message . for i = 1, ..., l(M) do
compute index j, where the ith message bit is stored .
mi ← LSB(cij)
end for.
le dernier, est celui qui a le moins d’influence sur la valeur de la luminance. On cache l’information en introduisant un biais dans cette proportion : on impose une valeur aux bits de poids faible des pixels choisis selon la clé. Par exemple, la lettre A peut être cachée dans 3 pixels (qui n’ont pas subi de compression). Soit le code binaire de 3 pixels (9 octets) suivant :
(00100111 11101001 11001000) (00100111 11001000 11101001) (11001000 00100111 11101001)
La valeur binaire de A est 10000011. En insérant la valeur binaire de A dans les 3 pixels, on obtiendrait le résultat suivant :
(00100111 11101000 11001000) (00100110 11001000 11101000) (11001000 00100111 11101001)
Parmi les 8 bits utilisés, les bits soulignés sont ceux qui ont été modifiés et en gras les bits de poids faible nécessaire pour comprendre le message entier. En moyenne, seule la moitié
des bits utilisés sont modifiés. Cette modification est imperceptible pour l’ ?il humain, car la luminance de ces pixels aura varié d’au plus 1. On peut aussi cacher des données dans le deuxième plus petit bit significatif sans que l’ ?il humain ne discerne le changement. Par contre, la modification du bit de poids faible est difficilement applicable sur des images de 8 bits (256 couleurs) en raison de la limitation du nombre de couleurs. Il existe plusieurs logiciels qui utilisent cette méthode.
Une approche plus sophistiquée de cette méthode réside dans l’utilisation d’un généra-teur de nombres pseudo-aléatoires pour étaler le message secret sur le médium de couver-ture. Si les deux participants à la communication partage une stégo-clé k utilisable comme graine pour un générateur de nombres aléatoires, ils peuvent créer une séquence aléatoire. Ainsi, la distance entre deux bits encapsulés est déterminée aléatoirement. Puisque le ré-cepteur a accès à la graine k et a connaissance du générateur de nombres pseudo aléatoires
Méthode à intervalle aléatoire . for i = 1, ..., l(c) do
si ← ci
end for.
generate random sequence ki using seed k
n ← k1
for i = 1, ..., l(m) do
sn← cn= mi
n ← n + ki
end for.
Encapsulation generate random sequence ki using seed .
n ← k1 for i = 1, ..., l(m) do mi ← LSB(cn) n ← n + ki end for. Fusion
Cette technique, que l’on peut considérer comme de la stéganographie naïve, consiste à ajouter les données à cacher au fichier [18]. Pour ce faire, cette méthode utilise des
emplacements inutilisés ou non lu par la plupart des décodeurs d’image.
On distingue deux fonctionnements : L’ajout de données en fin de fichier et l’ajout au niveau des en-têtes de fichier.
L’ajout en fin de fichier est rendu possible par le fait que la plupart des décodeurs d’image ne lisent pas le fichier image dans son ensemble. Pour la plupart des formats d’image disponible, un certaine chaîne de bits est définie afin de marquer la fin de l’image. L’ajout en fin d’image est simplement après cette chaîne de bits. Aucune limitation de taille n’est imposée, cependant un fichier image de 20 Mbytes risque de ne pas passer inaperçu.
Pour ce qui est de l’ajout dans les en-tête, certains formats comme le bitmap défi-nisse un champ permettant de spécifier l’offset à partir du quel l’image commencera. En spécifiant un offset un peu plus long il est possible de cacher entre deux les données à dissimuler. Cela peut aussi être fait à l’aide d’ajout de commentaire, pour le JPEG par exemple.
Fig. 2.5 – A gauche, image originale. A droite, image contenant des données dissimulées dans le champs de commentaire à l’aide d’Invisible Secrets 4 [18]
2.2
Codage matriciel (en anglais : "Matrix encoding")
Soit s et x respectivement le message secret qu’on veut cacher, et le support de cou-verture, on peut supposer que tous les deux sont deux séquences de symboles d’un al-phabet fini B. On note s = (s1, s2, ..., sk) et x = (x1, x2, ..., xn). Ainsi ils peuvent
être vus comme vecteurs s ∈ Bk et x ∈ Bn. Dans la plupart des cas l’alphabet est le
corps F2 = {0, 1} mais d’autres alphabets sont également possibles, en tant que chiffres
Définition 2.2.1 (Schéma stéganographique).
Soient n, k deux entiers positifs, k ≤ n et soit B un ensemble fini. Un protocole stéganographique de type [n, k] sur B c’est un paire de fonction Γ = (f, g) tels que
f : Bk× Bn→ Bn; g : Bn → Bk
telle que g(f (s, x)) = s, pour tout s ∈ Bk et x ∈ Bn, f c’est la fonction de dissimulation
et g la fonction de récupération. Le nombre ρ = max{d(x, f (s, x)), s ∈ Bk, x ∈ Bn} c’est
la rayon de protocole.
Ainsi, la fonction de dissimulation d’un [n, k] protocole stéganographique de rayon ρ, (dorénavant ce type de protocole est noté [n, k, ρ]) nous permet de cacher les symboles de l’information de longueur k dans une suite de n symboles de couverture, en changeant tout au plus ρ de ces symboles de couverture. L’information secrète s plus tard est extraite à partir de x en employant la fonction de récupération. Un bon protocole doit remplir deux conditions principales :
1. il faut avoir des algorithmes efficaces de dissimulation/récupération ; 2. avoir les bons paramètres k, n, ρ, (tels que k
n est plus grand possible et ρ
n le plus
petit possible). Le protocole serait approprié si f (s, x) est l’élément le plus proche à
x dans l’ensemble g−1(s) = {y ∈ Bn/g(y) = s} (noter que, étant n ≥ k alors g non
injective en générale et par conséquent g−1(s) est un ensemble, et pas un élément
simple ).
Exemple 2.2.1 Considérer un protocole de LSB appliqué à une image BMP. Si chaque
Pixel est représenté par h bits, nous pouvons considérer
1. le support de couverture est l’image entière ; le protocole (pour chaque Pixel) est la paire de fonctions f : F2 × Fh2 → Fh2; g : Fh2 → F2, défini par f (s, x1, ..., xh) =
(x1, x2, ..., xh−1, s) , g(y1, y2, ...., yh) = yh. Alors ces deux fonctions (f, g) définissent
un [1, h, 1] protocole stéganographique.
2. le support de couverture est l’ensemble de tous les bits de poids faible (LSB) ; le protocole (pour chaque Pixel) est la paire de fonctions f : F2× F2 → F2; g : F2 →
F2, avec f (s, x) = s ; g = Id, dans ce cas (f, g) représente le protocole [1, 1, 1]
On peut cacher un message en employant un protocole Γ, le nombre de bits changé dans le support de couverture son bornée par le rayon de Γ, dans des méthodes de LSB que nous pouvons espérer cela approximativement la moitié de Pixel demeurera sans changement (à la moyenne). Ainsi, sans compter que le rayon ρ il est d’intérêt de considérer la moyenne de symboles changés, α = α(Γ). Pour un [k, n] protocole Γ si Card(B) = q et tous les secrets possibles s et couvertures x sont également probables, cette moyenne est donnée près α(Γ) = 1 qkn X s∈Bk X x∈Bn d(x, f (s, x))
En construisant un protocole stéganographique, habituellement le processus de dissi-mulation est construit d’abord. Puis, la fonction de récupération est exactement choisie. Afin d’illustrer ceci comme ce qui, montre le protocole F5. Puisque c’est un bon exemple des idées que nous aimons développer en ce document, nous le décrirons de manière assez détaillée. À comprendre qui note F5, si nous voulons cacher de l’information dans le n bits de couverture en changeant tout au plus 1 d’entre eux, nous avons (n + 1) des possibilités, par conséquent nous pouvons cacher log(n + 1) d’information.
2.3
Le format JPEG en Stéganographie
La norme JPEG est une norme qui définit le format d’enregistrement et l’algorithme de décodage pour une représentation numérique compressée d’une image fixe.
JPEG est l’acronyme de Joint Photographic Experts Group. Il s’agit d’un comité d’experts qui édite des normes de compression pour l’image fixe. La norme communément appelée JPEG, de son vrai nom ISO/IEC IS 10918-1 | ITU-T Recommandation T.81, est le résultat de l’évolution de travaux qui ont débuté dans les années 1978 à 1980 avec les premiers essais en laboratoire de compression d’images. Le groupe JPEG qui a réuni une trentaine d’experts internationaux, a spécifié la norme en 1991. La norme officielle et définitive a été adoptée en 1992. Dans la pratique, seule la partie concernant le codage arithmétique est brevetée, et par conséquent protégée par IBM, son concepteur. JPEG normalise uniquement l’algorithme et le format de décodage. Le processus d’encodage quant à lui est laissé libre à la compétition des industriels et des universitaires. La seule contrainte est que l’image produite doit pouvoir être décodée par un décodeur respectant le standard. La norme propose un jeu de fichiers de tests appelés fichiers de conformance
qui permettent de vérifier qu’un décodeur respecte bien la norme. Un décodeur est dit conforme s’il est capable de décoder tous les fichiers de conformance. Un brevet concernant la norme JPEG a été déposé par l’entreprise Forgent, mais a été remis en cause par le bureau américain des brevets (USPTO), qui l’a invalidé le 24 mai 2006 pour antériorité existante à la suite d’une plainte de la Public Patent Foundation. Mais depuis le 27 septembre 2007, la société Global Patent Holdings, filiale d’Acacia Research Corporation, a à son tour revendiqué la paternité de ce format.
Fig. 2.6 – Schéma de compression/décompression JPEG
2.3.1
Transformation des couleurs
JPEG est capable de coder les couleurs sous n’importe quel format, toutefois les meilleurs taux de compression sont obtenus avec des codages de couleur de type lumi-nance/chrominance car l’œil humain est assez sensible à la luminance (la luminosité) mais peu à la chrominance (la teinte) d’une image. Afin de pouvoir exploiter cette pro-priété, l’algorithme convertit l’image d’origine depuis son modèle colorimétrique initial (en général RVB) vers le modèle de type chrominance/luminance YCbCr. Dans ce modèle,
Y est l’information de luminance, et Cb et Cr sont deux informations de chrominance, respectivement le bleu moins Y et le rouge moins Y.
Soit une image I que l’on veut compresser au format JPEG. Chaque pixel pi, est
repré-senté par un triplet (Ri, Vi, Bi) dans l’espace RVB. La première étape de la compression
JPEG consiste en un changement de l’espace des couleurs de RVB vers l’espace de couleurs YCbCr. Un pixel sera donc codé par un triplet (Yi, Cbi, Cri), où Yi désigne la luminance,
c’est-à-dire l’intensité lumineuse, Cbi la chrominance bleue, c’est-à-dire l’intensité de la
couleur bleue et Cri la chrominance rouge, c’est-à-dire l’intensité de la couleur rouge. Le
changement d’espace s’effectuent en appliquant les équations suivantes. Les équations de changement de RV B vers Y CbCr :
Y Cb Cr = 0, 299 0, 587 0, 114 −0.1687 −0, 3313 0, 5 0, 5 −0, 4187 −0, 0813 × R V B + 0 128 128
Les équations de changement de Y CbCr vers RV B :
R = Y + 1, 402(Cr − 128),
V = Y − 0, 34414(Cb − 128) − 0, 71414(Cr − 128), B = Y + 1, 772(Cb − 128).
Le changement d’espace de couleurs se justifie par le fait que l’espace Y CbCr est très proche du fonctionnement de l’œil humain. De plus, ce dernier est très sensible aux va-riations de luminance et très peu sensible aux vava-riations de chrominance. De ce fait, on pourra effectuer des modifications sur les composantes Cb et Cr afin de compresser l’in-formation visuelle et cela, sans que l’ ?il ne détecte la différence. Pour ce faire, les pixels sont regroupés en blocs de 4 × 4 pixels. Les quatre valeurs de chrominance bleue sont remplacées par leur moyenne ; la même transformation est effectuée sur les quatre valeurs de chrominance rouge. L’ ?il ne perçoit pas les changements effectués. Le gain de stockage est de 50% et la transformation appliquée est non réversible, la compression est dite avec perte. Cette transformation est appelée sous-échantillonnage.
Chacune des valeurs Y , Cb, Cr est un nombre codé sur P bits, compris entre 0 et 2P −1,
où P est appelé précision. Les valeurs Y , Cb et Cr sont alors ramenées sur l’intervalle [−2P +1+ 1, 2P −1− 1] par une translation de −2P −1.
2.3.2
Transformation DCT
La transformée DCT (Discrete Cosine Transform, en français transformée en cosinus discrète), est une transformation numérique qui est appliquée à chaque bloc. Cette trans-formée est une variante de la transtrans-formée de Fourier. Elle décompose un bloc, considéré comme une fonction numérique à deux variables, en une somme de fonctions cosinus oscil-lant à des fréquences différentes. Chaque bloc est ainsi décrit en une carte de fréquences et en amplitudes plutôt qu’en pixels et coefficients de couleur. La valeur d’une fréquence reflète l’importance et la rapidité d’un changement, tandis que la valeur d’une amplitude correspond à l’écart associé à chaque changement de couleur. Un coefficient DCT Suv de
coordonnées (u, v) dans le domaine fréquentiel s’exprime en fonction des 64 valeurs du bloc dans le domaine spatial sxy de coordonnées (x, y) à partir de la formule
Suv = 1 4C(u)C(v) 7 X x=0 7 X y=0 sxycos (2x + 1)uπ 16 cos (2y + 1)vπ 16 (2.1) avec C(0) = √1 2 et C(u) = 1 si u 6= 0
Cette transformation est en fait la partie réelle de la transformée de Fourrier discrète. La transformée en cosinus discrète inverse, (IDCT) permet de retrouver, lors de la dé-compression, les blocs dans le domaine spatial à partir des coefficients DCT, à l’aide de la formule sxy = 1 4C(u)C(v) 7 X u=0 7 X v=0 Suvcos (2x + 1)uπ 16 cos (2y + 1)vπ 16 (2.2)
Parmi les coefficients DCT, on distingue le coefficient S0,0, aussi appelé coefficient DC,
des autres que l’on nomme coefficients AC. Le coefficient DC est le coefficient des basses fréquences, c’est donc lui qui est porteur de la majorité de l’information. Ce coefficient étant généralement le plus grand ; on ne stocke que sa différence avec le coefficient DC du bloc précédent. La table (2.1) illustre un bloc de coefficients DCT.

![Fig. 2.1 – Jean Trithème et Steganographia [100]](https://thumb-eu.123doks.com/thumbv2/123doknet/2196150.12021/28.892.248.635.781.1067/fig-jean-tritheme-et-steganographia.webp)
![Fig. 2.2 – Schéma simplifié de Stéganographie [18]](https://thumb-eu.123doks.com/thumbv2/123doknet/2196150.12021/29.892.298.598.907.1085/fig-schema-simplifie-de-steganographie.webp)
![Fig. 2.3 – Schéma complet [18]](https://thumb-eu.123doks.com/thumbv2/123doknet/2196150.12021/30.892.233.666.704.859/fig-schema-complet.webp)
![Fig. 2.5 – A gauche, image originale. A droite, image contenant des données dissimulées dans le champs de commentaire à l’aide d’Invisible Secrets 4 [18]](https://thumb-eu.123doks.com/thumbv2/123doknet/2196150.12021/36.892.228.657.673.820/gauche-originale-contenant-donnees-dissimulees-commentaire-invisible-secrets.webp)

![Fig. 2.8 – Image chinois.jpg [100]](https://thumb-eu.123doks.com/thumbv2/123doknet/2196150.12021/47.892.299.594.682.890/fig-image-chinois-jpg.webp)
