Learning corrections for hyperelastic models from data
Texte intégral
Figure

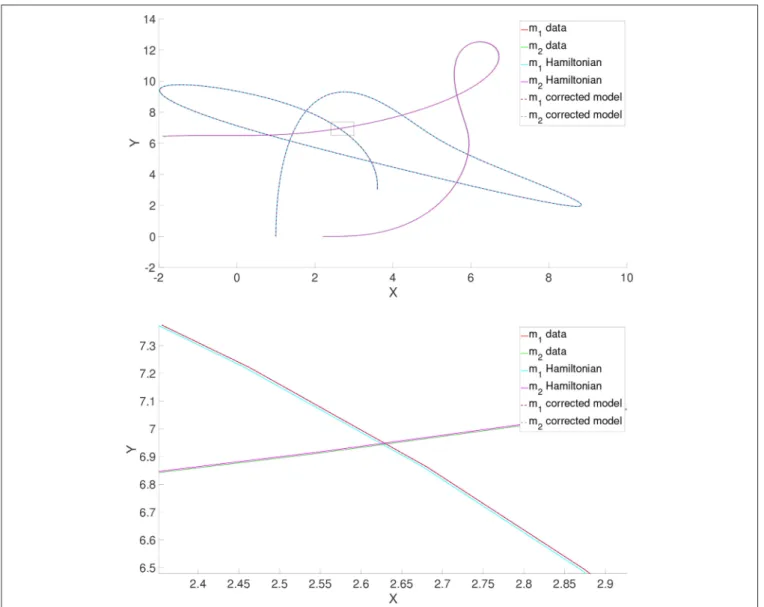
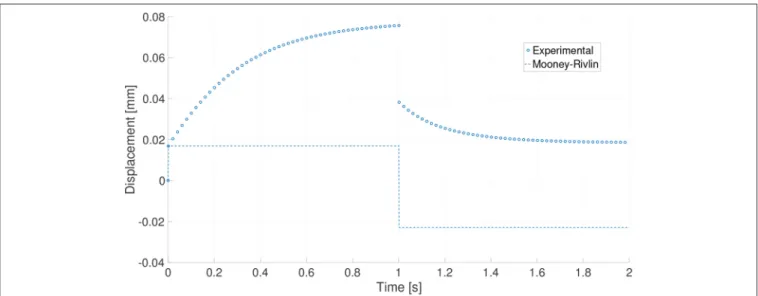
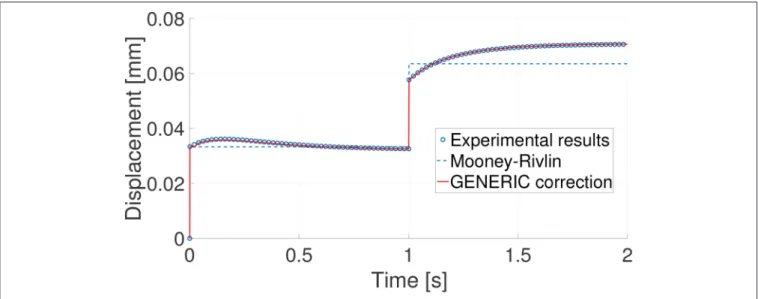

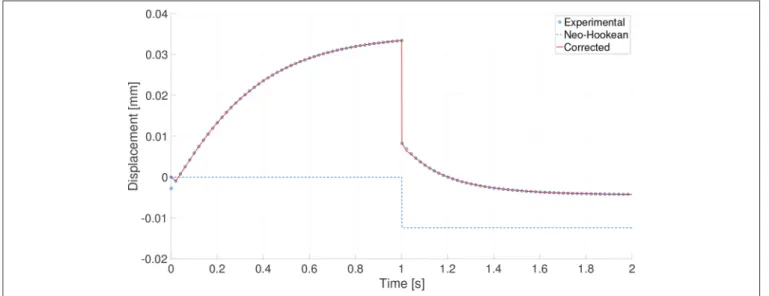
Documents relatifs
The asymptotic approximation of the displacement field deduced by orthogonal transformation, given by equations (81)-(84), can satisfy the symmetry property by an appropriate choice
This original coupled approach, using simulations from a realistic OGCM and in situ Nd data, allowed us to characterize the subduction areas, pathways and transports of the
Trois grandes parties ont été nécessaires : une première partie bibliographique à travers laquelle nous avons passé en revue les travaux actuels entrepris dans ce domaine, une
This text is based on notes (taken by R. Thangadurai) of three courses given at Goa University on December 15 and 16, 2014, on Algebraic independence of Periods of Elliptic
Motivated by the increase of archaeological and epigraphic sources in recent decades the project aims at an integrated analysis and transparent access of these
The fraction of reported cases, from date τ 3 to date τ f , the fraction of reported cases f was assumed increase linearly to reach the value 200% of its initial one and the fraction
data generating process is necessary for the processing of missing values, which requires identifying the type of missingness [Rubin, 1976]: Missing Completely At Random (MCAR)
Comparison of recognition rate when using only original data to the use of synthetic data, without (a) and with (b) highlighted times of addition of new class (dots). In Figure
