Towards Generic Image Classification using Tree-based Learning: an Extensive Empirical Study
Texte intégral
Figure
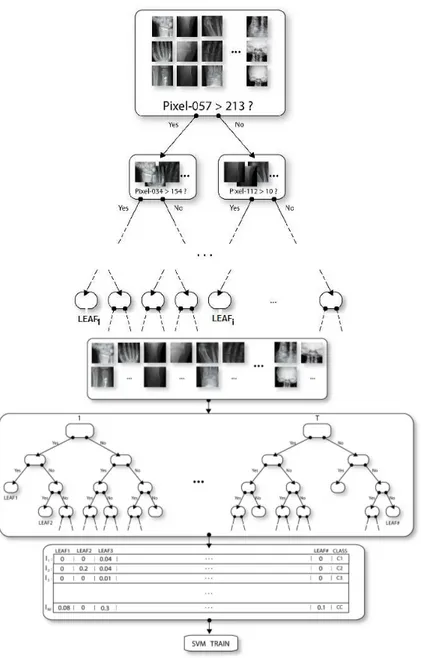
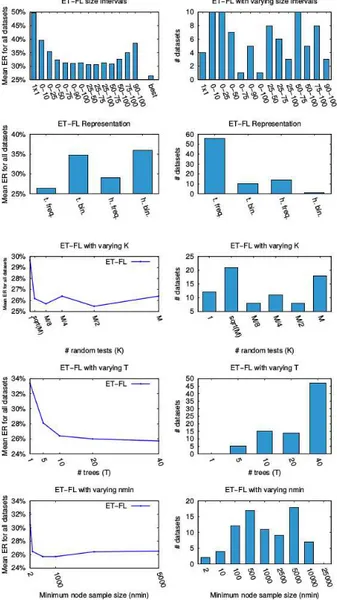
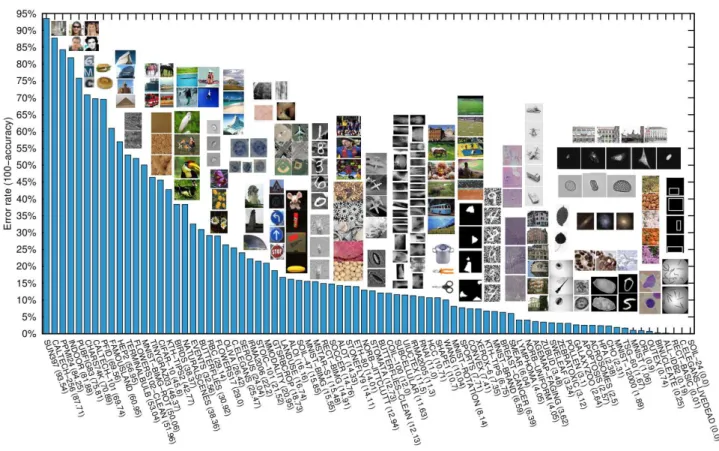

Documents relatifs
Lyapunov exponents are useful in different domains of mathematics In smooth ergodic theory one is interested in the ergodic behavior of smooth maps The Lyapunov exponents can be used
In addition, even if p is not realized by a PRFA or is empirically estimated, our algorithm returns a PFA that realizes a proper distribution closed to the true distribution..
A chirped pulse millimeter wave (CP- mmW) setup was combined with the buffer gas cooling apparatus for combined laser and millimeter wave spectroscopy experiments
For instance, a test image that has been classified by the extra-trees with a probability of 0.9 means that a great number of subwindows have been assigned a high probability of
Use the Tfid- fVectorizer tool provided by scikit-learn to convert the text data into TF-IDF feature vector, using the logistic regression, support vector machine, naive
Figure 2 shows the performance on a random validation dataset (20 percent of training data) using ensemble of models trained with over-sampling, threshold moving and error
1) Taking into account the relationship between HSI channels by calculating the correlation, constructing a linear predictor of the next channel value from the
As vast research in sensors to detect physiological changes relation to emotion has been conducted in the field of autonomic response and the emotional state in a learning context
