Réplication de données dans les systèmes de gestion de données à grande échelle
Texte intégral
Figure
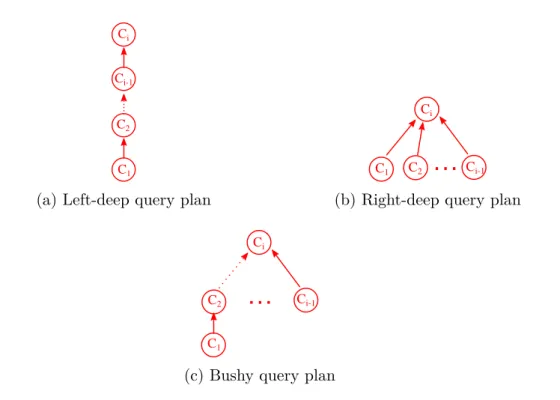
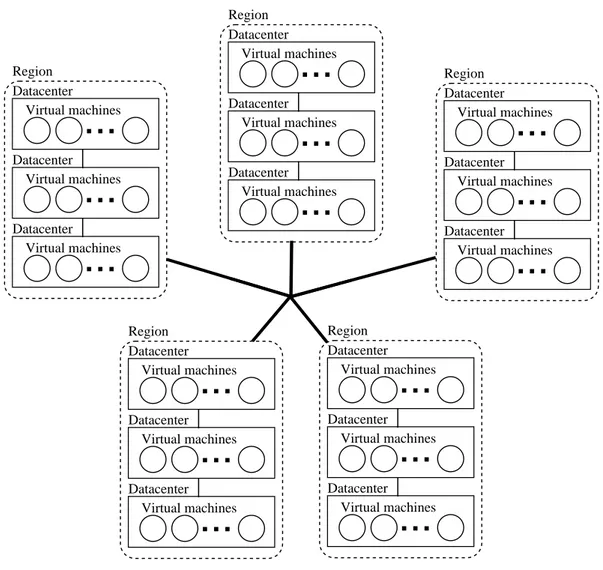
Documents relatifs
Afin de pouvoir évaluer la qualité des motifs précédemment découverts et d'identifier de nouvelles séquences appartenant aux différentes familles de protéines amyloïdes, nous
A l’heure actuelle, les solutions que nous pouvons consid´er´ees sont : (i) or- donner les candidats en fonction de leur proximit´e avec la derni`ere requˆete de la session
Grâce à notre solution, les transferts de données sont désormais gérés par un compo- sant intégré dans chaque client dans lequel les requêtes de transfert sont ordonnancées pour
Dans ce papier nous allons donc nous atteler à la comparaison entre deux stratégies de réplication de données avec d’un coté une stratégie qui considère le profit économique,
Dans cette section, nous décrivons brièvement l’évaluation de SVMAX. Notre système est fourni à la fois comme une API Java et outil visuel. En utilisant ce dernier, on peut choisir
Dans le domaine de l’automatique et de la supervision des processus, la conception et l’utilisation des modèles mathématiques (modèle qualitatif, modèle
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
la nuisibilité des adventices tropicales de manière globale. Pour cela, il est nécessaire de pouvoir aborder cette analyse à l’échelle de la parcelle, de l’exploitation,
