BCTMark: a framework for benchmarking blockchain technologies
Texte intégral
Figure
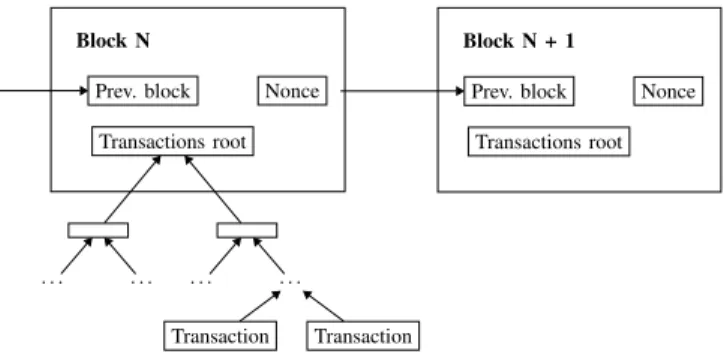

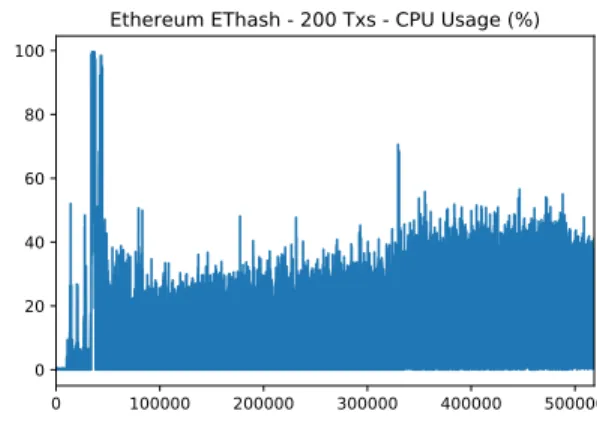
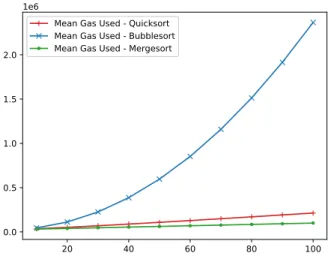
Documents relatifs
GoDIET automatically generates configuration files for each DIET component taking into ac- count user configuration preferences and the hierarchy defined by the user,
Advance reservation in grid envi- ronment is a complex issue due to the following reasons: (i) Since availability and performance of resources both exhibit dynamic variability, it
In this paper, we presented experiments conducted on the Grid’5000 testbed to explore the scalability of the Kadeploy cluster deployment solution using up to 3999 KVM virtual
In the indirect funding model, users are given a way to spend resources on any testbed they need to perform the work they are funded for.. The exact cash-flow could be indirect
• after each set of tasks the agent schedules, it sends information about its local resources to a MonALISA[3] farm; the information consists of: the average
In the context of the C ORBA Component Model ( CCM ), this paper details all the steps to achieve an automatic deployment of components as well as the entities involved: a grid
Just like real criminals, who start from scratch a new life in other countries under a false name and live there with perfect impunity, some fiction characters
According to the literature of AP task in social media, the methods that build high level features based on relationships among groups of authors have been useful for boosting
