On a unifying product form framework for redundancy models
28
0
0
Texte intégral
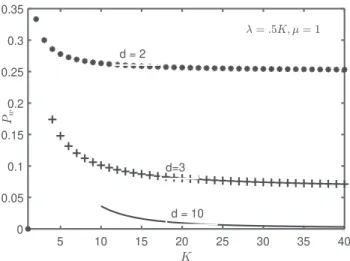
Figure
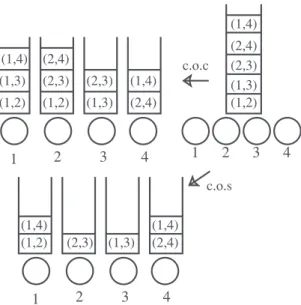
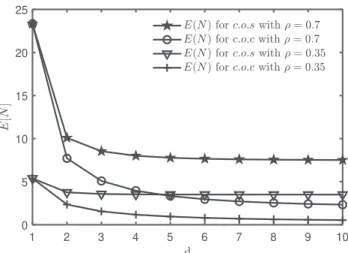


+2
Documents relatifs
