Exploitation d'indices visuels liés au mouvement pour l'interprétation du contenu des séquences vidéos
79
0
0
Texte intégral
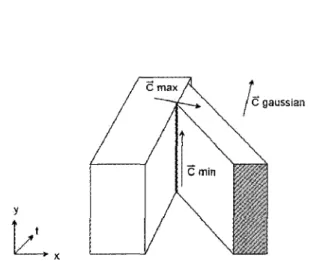
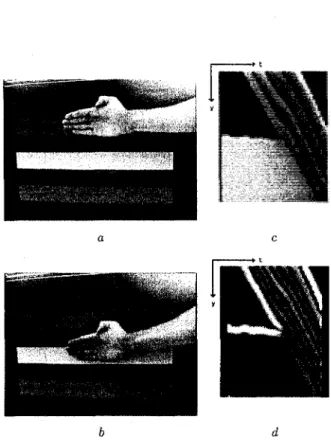
Figure

+7



Documents relatifs