UFR Informatique et Télécommunications
Faculté des Sciences, 4 Avenue Ibn Battouta B.P. 1014 RP, Rabat – Maroc Tel +212 (0) 5 37 77 18 34/35/38, Fax : +212 (0) 5 37 77 42 61, http://www.fsr.ac.ma
N° 2579
THÈSE DE DOCTORAT
Présentée par :
Hajar BOUIROUGA
Discipline : Sciences de l’ingénieur
Spécialité : Informatique et Télécommunications
Reconnaissance des scènes vidéo pour adulte
Soutenue le : 30 Juin 2012
Devant le jury
Président :
Driss ABOUTAJDINE, PES, Faculté des Sciences de Rabat, Maroc
Examinateurs :
Mr Lhoussaine MASMOUDI, PES, Faculté des Sciences de Rabat. Mr Abdallah ADIB, PES, Faculté des Sciences de Mohammedia Mr El Hassane IBN ELHAJ, PES, INPT Rabat.
Mr Mohamed WAHBI, PES, EHTP Casablanca. Mme Sanaa EL FKIHI, PA (ENSIAS, Rabat, Maroc
________________________________________________________________________
AVANT PROPOS
Les travaux présentés dans ce mémoire ont été effectués au Laboratoire de Recherche en Informatique et Télécommunications (LRIT) à la Faculté des Sciences de Rabat, Université Mohamed V-Agdal, sous la direction du Professeur Driss ABOUTAJDINE, responsable du laboratoire LRIT, à qui je tiens à exprimer ma profonde gratitude pour m’avoir encadrée avec un grand intérêt ainsi que pour ses encouragements, son ouverture d’esprit et bien sûr ses qualités scientifiques exceptionnelles.
Nulle parole ne saurait exprimer toute ma gratitude et mes chaleureux remerciements adressés à Mme Sanaa EL FKIHI, Professeur assistant à ENSIAS et à Mr Abdelillah JILBAB, Professeur agrégé à ENSET, pour avoir bien voulu accepter de diriger ce travail. Que ce modeste travail puisse leur donner entière satisfaction. Je dois une profonde reconnaissance pour l'aide et le soutien qu'ils m’ont apportés, ainsi pour leurs suggestions et leurs contributions, sans oublier bien sûr le partage de leurs connaissances sur le monde de la recherche.
Je remercie les membres de mon jury de thèse pour l’intérêt qu’ils ont porté à mon travail. Merci au Professeur Driss ABOUTAJDINE d’avoir accepté de présider mon jury de thèse.
Je suis également reconnaissante à Mr Lhoussaine MASMOUDI, Professeur de l'enseignement supérieur à la Faculté des Sciences de Rabat et à Mr El Hassane IBN ELHAJ, Professeur de l'enseignement supérieur à l’INPT de Rabat d’avoir accepté de juger ce travail et d’en être les rapporteurs. Mes sincères remerciements vont également à Mr Abdellah ADIB, Professeur de l'enseignement supérieur à la faculté des sciences et techniques de Mohammedia et à Mr Mohamed WAHBI, Professeur de l'enseignement supérieur à L’EHTP de Casablanca pour leur participation au jury de cette thèse. Je les remercie tous pour leurs remarques et leurs critiques constructives.
Je remercie chaleureusement mes parents, proches, professeurs et tous ceux qui ont rendu ce travail possible par leurs conseils, soutiens, remarques et encouragements.
Je voudrais maintenant remercier mes amis qui m’ont aidé, au cours de ces dernières années, à conserver ou à retrouver un certain équilibre.
Au cours de mon travail de thèse, j’ai été amené à travailler au sein de Maroc-métrie la société qui mesure les audiences TV au maroc dont je saisie l’occasion à remercier tout son corps professoral et surtout son directeur Younès Alami ainsi que toute l’équipe PANEL et DSI qui m’ont épargné aucun effort pour m’orienter afin que je puisse mener a bien cette thèse. Enfin, j’adresse ma profonde gratitude et ma reconnaissance à Mme Sâadia Samri pour son soutien au cours de ces années.
Je voudrais enfin renouveler mon affection à ma famille. Maman, Papa, mes deux sœurs Kawtar et Doha mes oncles et ma tante, c’est aussi pour vous et grâce à vous …
RESUME
La détection de la peau consiste à détecter les pixels de peau dans une image couleur pour obtenir une image binaire. Elle constitue une étape de prétraitement fondamentale dans plusieurs applications telles que la détection de visage, la segmentation vidéo, le filtrage des images sur le Web et la reconnaissance des scènes vidéo pour adultes. Cependant, c’est une tâche difficile à réaliser à cause de la variation de la couleur de la peau (européenne, africaine, etc.) et la diversité des conditions de prise de vue (lumière, bruit, ...) qui créent une classe de la peau avec beaucoup de variations inter-classe.
Dans l’objectif de surmonter ces dernières contraintes nos travaux de thèses consiste à définir un modèle robuste de la distribution de la peau basé sur la fusion des différentes espaces de couleurs. La fusion de classificateurs, a été proposée comme une voie de recherche permettant de fiabiliser la détection en utilisant la complémentarité qui peut exister entre les trois classificateurs. Ensuite, nous avons proposé d’utiliser les informations de mouvement présentes dans la séquence. En effet, le mouvement apparent des pixels est généralement continu au cours du temps.
L’utilisation de l’information de mouvement peut être un moyen simple pour mettre en œuvre une technique rapide de détection de peau dans une vidéo. Cette catégorie de systèmes suppose généralement que l’arrière plan de la scène vidéo est stationnaire et que les régions contenant la peau tels que le visage ou/et les mains par exemple sont en mouvement. Dans ce cas, ces régions peuvent être détectées par une simple différence entre l’image courante et l’image précédente. Il semble évident que les hypothèses retenues sont trop fortes. C’est pourquoi l’information de mouvement n’est jamais utilisée seule pour la détection. On la trouve utilisée conjointement avec l’information de couleur de peau. L’exploitation de l’information de mouvement oriente la détection de peau vers des zones préférentielles en éliminant les zones sans intérêt et permet donc une forte réduction de la complexité de la détection et par conséquent une limitation importante des calculs et des traitements.
Ensuite, une vérification de la présence ou pas d’un visage dans la scène ne peut être que très bénéfique. Cette étape permettra au système de détourner l’opération de reconnaissance si la scène ne contient aucun visage. On se base donc sur un vote majoritaire selon le nombre de visages dans les différents frames de la vidéo à analyser. Notre méthode se révèle être en mesure de déterminer et de distinguer efficacement les vidéos à caractère illicite en intégrant la caractéristique de la forme associée à la détection de visage. Cependant, si le nombre de visages dominant dans la vidéo appartient à l’intervalle [1 4], on conclu que cette vidéo peut bien être une vidéo adulte.
Pour augmenter les performances de notre démarche on a proposé de compléter le prétraitement en éliminant les images qui présentent des gens avec des costumes de natation. Une manière possible pour traiter ce problème est de créer une méthode d'identification d'objet pour la région peu sûre supérieure qui identifierait la différence entre un corps d'une femme et celle d’un homme. Cette méthode consiste tout d’abord à calculer le nombre de régions de peau dans les images de la vidéo, puis on procède à séparer les régions et en extraire différentes informations, en vérifiant un ensemble de contraintes qui sont aux nombres de deux. L’une concerne le ratio et l’inclination θ de la région et l'autre concerne sa surface, habituellement, dans le cas des organes adultes, ces contraintes ne dépassent pas un certain intervalle, donc tous les segments qui ont un ratio, une inclination et une surface qui ne fait pas partie de cet intervalle seront éliminés.
Une phase de prise de décision consiste à calculer des descripteurs qui caractérisent les images pour adultes de la scène sur les zones détectées de la peau. Elle permet d’affecter la probabilité d’appartenance d'une image à l’une des deux classes : Adulte ou non adulte. Un pourcentage de peau élevé correspond à une image qui sera classifiée pour adulte. Tous ces descripteurs composent un vecteur de fonction simple qui sera pris en considération pour prendre notre décision. Cette phase peut être accomplie par plusieurs modèles (arbres, réseaux de neurones (ANN), SVM...).
Il n’existe pas une règle générale pour choisir le meilleur classificateur pour une application donnée. Pour cela, le choix entre ces classificateurs se fait d’une manière empirique en utilisant les résultats de classification comme critère de performance. A cette fin, nous avons présenté une étude comparative entre les deux classificateurs ANN et SVM en termes de
taux de bonne reconnaissance et on a conclu que la méthode SVM avec noyau gaussien est celle qui donne les meilleurs résultats.
Mots clefs : Détection de la peau, Détection de mouvement, visage, classification, réseaux de neurones, SVM, descripteurs des images adultes, filtrage vidéo.
ABSTRACT
Skin detection is considered a fundamental step in many image and video processing applications namely, face detection, video segmentation, filtering internet images and recognition of adult video scenes. It consists in detecting skin and non-skin pixels in a given color image to obtain a binary one. However, this is not always an easy task because the change in skin color (European, African, etc) and the variety of shooting conditions (light, noise, etc) create a class of skin with a lot of inter-class variations.
To overcome these drawbacks, our objective in this thesis is to put forward a robust approach capable of discriminating between skin and non skin areas. Our contributions are based on the fusion of different color spaces with the aim to take advantages of the complementarity that exists between these spaces. Besides, we propose to use the motion information present in the video sequence in conjunction with the information of skin color. Indeed, the apparent motion of pixels is generally continuous over time. Using motion information can be a simple way to implement a rapid detection of skin in a video by assuming that the background of the video scene is stationary and regions containing the skin such as the face and the hands are in motion. Indeed, in skin detection, the exploitation of motion properties allows the elimination of uninteresting areas and reduces largely the complexity of detection and, therefore, a significant limitation of the computing process.
In our work, we focus on the detection of adult video scenes. In this way, the verification of a face in the scene can be very useful. This step will allow the system to ignore video analysis if no face is in the scenes. It is, therefore, based on a majority vote by the number of faces in different frames of video to analyze. Our method has proven to be able to identify videos that may contain adult scenes by integrating the characteristic shape associated with face detection. However, if the number of dominant face in the video belongs to the interval [1 4], we concluded that this video may well be an adult video.
To improve the performance of our approach it was proposed to complete the pre-treatment by removing the images that present people with swimming costumes. One possible way to deal with this problem is to create a method of object identification for the region that would
identify the difference between the body of a woman and that of a man. This method first to calculates the number of regions of skin in the images of the video, then proceeds to separate different regions and extracts information by checking a set of constraints, namely first the ratio and the inclination θ of the region and then its surface. Usually in the case of adult organs, these constraints do not exceed a certain range. So, all segments that have a ratio, an inclination and a surface that is not part of this range will be eliminated.
A decision phase, based on descriptors that characterize adult images obtained from the detected areas of the skin, determines the probability of belonging to an adult or a non adult image. A high percentage of skin corresponds to an image that will be classified for adults. All these descriptors comprise a vector of simple function that will be considered in making our decision. This phase can be accomplished by several models (trees, neural networks, SVM ...).
There is no general rule for choosing the best classifier for a given application. The choice between these classifiers is empirically using the classification results as a method of performance. To this end, we presented a comparative study of the two classifiers ANN and SVM in terms of correct recognition rate. It was concluded that the SVM method using Gaussian kernel gives the best performances.
Keywords: Skin detection, motion detection, classification, neural networks, SVM, descriptors of adult images, video filtering.
Résumé………...2
Abstract ..………...5
Tables des matières……….………7
Liste des figures ……….…..11
Liste des tableaux………..13
Abréviations ………...14
Introduction Générale…….……….…….15
Chapitre 1 : Analyse Multimédia
1.1 Introduction ... 221.2 Etat de l’art et étude des systèmes existants ... 22
1.2.1 Les approches de filtrage. ... 23
1.2.2 Logiciels existants ... 24
1.3 Le fossé sémantique ... 26
1.4 Le document vidéo ... 26
1.5 Analyse du contenu de la vidéo ... 27
1.6 Modélisation du Contenu Vidéo ... 28
1.7 Les différents formats de fichiers vidéo numériques ... 29
1.8 Les images de références ... 30
1.9 Description générale du système de reconnaissance ... 31
1.9.1 Extraction des caractéristiques ... 32
1.9.2 Classification ... 32
1.10 La segmentation temporelle de vidéo ... 33
1.10.1 Segmentation en plans ... 34
1.10.2 Segmentation en scènes ... 34
1.11 La segmentation d'image ... 35
1.11.1 Segmentation en blocs ... 35
1.11.1 Segmentation en régions ... 36
1.12 Les critères pour les mesures des performances ... 37
1.13 Présentation des données ... 37
1.14 Conclusion ... 39
Chapitre 2 : Détection de la peau
2.1 Introduction ... 412.2 Les espaces couleur pour la détection de la peau ... 42
2.2.1 L’espace RGB ... 43
2.2.2 L’espace HSV ... 44
2.2.3 L’espace YUV ... 44
2.3 Représentation du contenu visuel des images ... 45
2.3.1 Les attributs réversibles ... 46
2.3.2 Les attributs non-réversibles ... 46
2.3.2.1 Descripteurs de couleur ... 46
2.3.2.3 Descripteurs de forme ... 47
2.3.2.4 Descripteurs de mouvement ... 48
2.4 Les méthodes de détection de la peau ... 49
2.4.1 Les approches physiques de détection de la peau ... 49
2.4.1.1 La couleur de peau dans l’espace RGB ... 50
2.4.1.2 La couleur de peau dans l’espace HSV ... 50
2.4.1.3 La couleur de peau dans l’espace YCbCr ... 51
2.4.2 Les approches paramétriques de distribution de la peau ... 52
2.4.2.1 Simple gaussien ... 52
2.4.2.2 Mélange de gaussiennes ... 53
2.4.3 Les approches non paramétriques de distribution de peau ... 53
2.4.3.1 Le classificateur de Bayes ... 54
2.4.3.2 Table normale de consultation ... 55
2.5 Fusion des méthodes de détection de la peau ... 55
2.5.1 Fusion entre le modèle bayes et les différents espaces de couleurs ... 56
2.5.2 Fusion entre les deux espaces HSV et YCbCr ... 57
2.5.3 Fusion entre les deux espaces RGB et HSV ... 58
2.5.4 Fusion entre les deux espaces RGB et YCbCr ... 58
2.5.5 Fusion entre les trois espaces RGB-HSV-YCbCr ... 58
2.6 Evaluation de performances de classificateurs ... 59
2.7 Transformation morphologique ... 65
2.7.1 Erosion ... 65
2.7.2 Dilatation ... 66
2.8 Conclusion ... 68
Chapitre 3 : Détection des scènes vidéo pour adultes
3.1 Introduction ... 703.2 Description des changements de plans ... 71
3.2.1 Détection des changements de plan ... 71
3.2.2 Méthodes de détection du changement de plan ... 72
a. Méthodes basées sur les pixels ... 72
b. Méthodes basées sur les histogrammes ... 72
c. Méthodes basées sur les blocs ... 73
d. Méthodes basées sur le mouvement ... 74
3.3 Les méthodes de détection de mouvement ... 74
3.3.1 Algorithme de la soustraction de l’arrière-plan par modélisation statistique ... 75
a. Initialisation ... 75
b. Extraction de l’avant-plan ... 76
c. Résultats expérimentaux ... 77
3.3.2 Algorithme de la différence entre deux images consécutives ... 77
a. Calcul de la différence ... 78
b. Calcul des étiquettes de mouvement ... 78
c. Résultats expérimentaux ... 78
3.4 Détection des visages ... 79
3.4.1 Méthodes de détection de visages ... 79
3.4.2 Notre approche pour la détection de visage ... 80
a. Sélection des pixels représentant la peau à partir d'une image d'entrée ... 80
c. Détection du visage par appariement du gabarit "template matching" ... 80
3.4.3 Application de la méthode de détection de visage ... 82
a. Extraction de l'image niveau de gris ... 82
b. Normalisation du segment ... 82
c. Comparaison du segment avec le modèle ... 82
d. Décision ... 82
3.5 Extraction des caractéristiques des régions ... 84
3.6 Vérification des images de la plage ... 90
a. La position ... 90
b. Les dimensions du segment ... 90
c. La surface ... 90
d. Le rapport entre la hauteur et la largeur ... 90
e. Calcul du centre de gravitée du segment ... 90
f. Calcul de la rotation du segment ... 91
3.7 Evaluation de performance ... 93
3.8 Conclusion ... 93
Chapitre 4 : Reconnaissance des scènes vidéo pour adultes
4.1 Introduction ... 954.2 Classification des vidéos ... 96
4.3 Méthode de classification ... 98
4.3.1 Classification Naïve de Bayes ... 98
4.3.2 Les arbres de décision ... 99
4.3.3 La logique floue en classification ... 100
4.3.4 Réseau de neurones ... 101
4.3.4.1 Les étapes de la conception d'un réseau ... 102
a. Choix et préparation des échantillons ... 102
b. Elaboration de la structure du réseau ... 102
c. Apprentissage ... 102
d. Validation et tests ... 102
4.3.4.2 Calcul de la valeur prédite ... 103
4.3.4.3 Optimisation des paramètres ... 104
4.3.4.4 Choix du nombre d’unités cachées ... 105
4.3.4.5 Utilisation des ANN pour le blocage des scènes vidéo pour adultes ... 105
a. Un filtre de réseau neuronal ... 105
b. Vérifier des images pour adultes ... 106
4.3.4.6 Comparaison entre les différentes fonctions d’activation ... 107
4.3.5 Les machines à vecteur de support ... 110
4.3.5.1 Cas linéairement séparable ... 110
4.3.5.2 Cas linéairement non-séparable ... 114
4.3.5.3 Astuce noyau ... 115
4.3.5.4 Exemples de kernels... 115
a. Le kernel polynomial ... 115
b. Le kernel RBF Gaussien ... 117
c. Le kernel neuronal (Sigmoïde) ... 117
d. Le kernel linéaire ... 118
4.3.5.5 Choix des paramètres ... 118
a. Résolution du problème d’optimisation quadratique ... 119
b. Calcul du biais. ... 119
4.3.5.7 Comparaison des performances entre les noyaux SVM ... 125
4.4 Evaluation de la classification ... 126
4.5 Illustration et interprétation des résultats ... 128
4.6 Conclusion ... 129
Conclusion Générale ………..……….131
Liste des publications ………..………133
LISTE DES FIGURES
1 Processus de filtrage de la vidéo adultes. 1.1 Architecture du filtre
1.2 Comparaison entre les logiciels existants. 1.3 Structure d'une vidéo.
1.4 Exemple d'image mosaïque construite à partir d'un ensemble d'images. 1.5 Description générale du système de Reconnaissance.
1.6 Composantes du système de Reconnaissance.
1.7 Résultats de la segmentation d’une séquence de type Avi. 1.8 Résultats de la segmentation d’une séquence de type Mpeg. 1.9 Segmentation en blocs d’une image.
1.10 Extrait de la base d’apprentissage. 1.11 Extrait de la base de test.
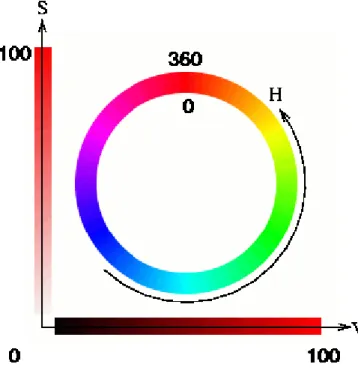
2.1 L’image originale et son masque binaire. 2.2 Présentation des couleurs dans l'espace RGB. 2.3 Représentation du modèle HSV.
2.4 Transformation du RGB en YCbCr et HSV.
2.5 Fusion de la méthode bayésienne et la méthode du seuillage par HSV, a) Original image, b) détection par la méthode de bayes, c) Ajout des pixels blancs par la méthode de seuillage, d) filtrage morphologique.
2.6 Les courbes ROC pour Les approches physiques de détection de la peau, et pour les approches paramétriques et non paramétriques.
2.7 Résultats de la modélisation paramétriques et non paramétrique de distribution de peau. 2.8 Résultats des approches physiques de distribution de peau.
2.9 Les courbes ROC de la fusion entre le modèle bayes et les approches physiques de détection de la peau.
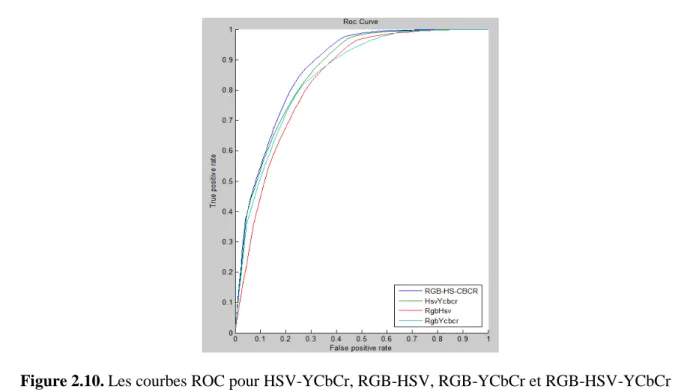
2.10 Les courbes ROC pour HSV-YCbCr, RGB-HSV, RGB-YCbCr et RGB-HSV-YCbCr. 2.11 Les courbes ROC pour Bayes-HSV et notre modèle hybride RGB-HSV-YCbCr.
2.12 Résultats de la modélisation de la répartition de la peau en fonction de différents modèles.
2.13 Résultat de l'érosion de la fonction de départ figuré en vert.
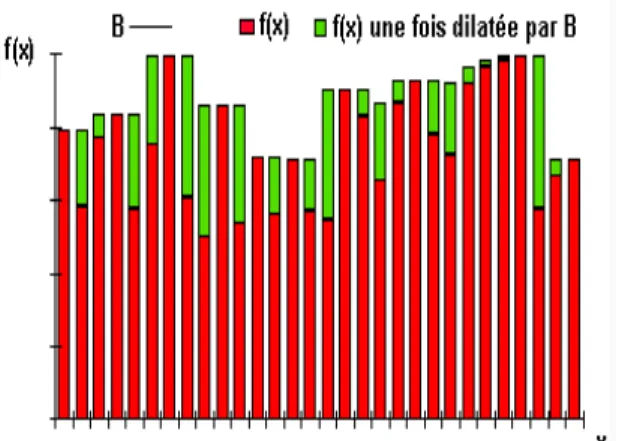
2.14 Résultat de la dilatation de la fonction f(x) par un élément structurant B. 2.15 Processus de segmentation général d’une image.
2.16 Résultat du filtrage morphologique.
2.17 Les courbes Roc pour le résultat du modèle RGB-HSV-YCbCR avec et sans le filtrage morphologique
3.1 Résultats de la soustraction de l’arrière plan pour la séquence vidéo d’un être humain. 3.2 Résultats de la soustraction de l’arrière plan pour la séquence vidéo de deux balles
bondissantes.
3.3 Détection du mouvement par la méthode de soustraction d’images consécutives.
Matching (Cas où il n’y a pas de visage).
3.5 Illustration de quelques résultats de la détection des visages par la méthode Template Matching (Cas pas de visage).
3.6 La probabilité de la peau moyenne à l'intérieur de l’ellipse globale. 3.7 La probabilité de peau moyenne à l'intérieur du LFE.
3.8 La probabilité de la peau moyenne à l'extérieur du LFE. 3.9 Le taux de bonne défection en fonction du nombre de visage. 3.10 La structure du filtre des scènes vidéo adulte.
3.11 Les courbes ROC avec et sans détection de visage. 4.1 Schéma général d'un réseau neuronal.
4.2 La structure du filtre des scènes vidéo adulte cas des réseaux de neurone.
4.3 Comparaison entre les différentes fonctions d’activation pour le filtre des scènes vidéo adulte.
4.4 Hyperplan de séparation optimal.
4.5 Représentation dans IR2 de l’hyperplan correspondant à la fonction de décision d’un classificateur linéaire.
4.6 Représentation de la séparation par un kernel polynomial de degré d. 4.7 Représentation de La séparation par un kernel RBF.
4.8 La structure du filtre des scènes vidéo adulte cas des SVM. 4.9 Noyau linéaire, moyenne sur 100 ensembles pour C = 1 à100. 4.10 Noyau linéaire, moyenne sur 100 ensembles pour C = 2 à 5.
4.11 Noyau gaussien, moyenne sur 100 ensembles pour C = 3 et σ=0.1 à 100.
4.12 Noyau gaussien, moyenne sur 100 ensembles pour
σ
= 2.5 et C=1 à 100 puis de 3 à 10. 4.13 Noyau gaussien, moyenne sur 100 ensembles pour C = 4.9 et σ= 0.1 à 100 et de 2.5 à 5. 4.14 Noyau polynomiale, moyenne sur 100ensembles pour C = 3 et d=0.1 à 100.4.15 Noyau polynomial, moyenne sur 100 ensembles pour d = 2.5 et C=1 à 100 puis de 3 à 5. 4.16 Noyau polynomial, moyenne sur 100 ensembles pour C = 3 et d =2.5 à 5.
4.17 Les courbes ROC pour les différents kernels utilisés à identifier les scènes vidéo adultes. 4.18 Les courbes ROC pour ANN et SVM pour la reconnaissance des vidéos pour adultes
résultat sur des images synthétiques.
4.19 Les courbes ROC pour ANN et SVM pour la reconnaissance des scènes vidéo pour adultes résultat sur des images réels.
4.20 Résultats expérimentaux pour des images adultes. 4.21 Résultats expérimentaux pour des images non adultes.
LISTE DES TABLEAUX
2.1 Les performances des modèles de détection de peau
2.2 Résultats de la détection de la peau pour les deux modèles RGB-HSV-YCbCr et Bayes (Test réalisé sur 100 vidéos adultes et 100 non adultes)
4.1 Comparaison de taux de performance et de temps moyen de traitement pour les différentes fonctions d’activation pour le seuil 0.70.
4.2 Comparaison de taux de performance et de temps moyen de traitement pour les différentes fonctions d’activation pour le seuil 0.72.
4.3 Comparaison de taux de performance et de temps moyen de traitement pour les différentes fonctions d’activation pour le seuil 0.74.
LISTE DES ABREVIATIONS
AVI : Audio Video InterleaveImbrication Audio Vidéo, est un format de fichier conçu pour stocker des données audio et vidéo.
JPEG : Joint Photographic Experts Group
Méthode de compression des images qui en préserve les qualités. C'est probablement la plus utilisée en stockage et échange de photos via le WEB, avec le GIF.
MOV : Quicktime Movie
C’est un fichier vidéo propriétaire de la firme Apple, prévu pour être lu en streaming.
MPEG : Moving Picture Expert Group
Méthode de compression mise au point pour la transmission d'images vidéo. RGB : Red, Green and Blue (Rouge, Vert et Bleu).
HSV : Hue, Saturation and Value (Teinte, Saturation et Valeur).
YCbCr : Luma, blue-difference and red-difference components (Luminance, Chrominance bleu et Chrominance rouge).
CIE : International Commission on Illumination
La commission internationale de l'éclairage est une organisation internationale dédiée à la lumière, l'éclairage, la couleur, les espaces de couleur.
ROC : Receiver Operating Characteristics
La courbe ROC, est un graphique tracé de la sensibilité , ou taux de vrais positifs, par rapport au taux de faux positifs.
SAP : Extraction of background (Soustraction de l’arrière plan). SVM : Support Vector Machine (Machine à vecteurs de support). ANN : Artificial Neural Network (Réseau de neurones artificiels). LFE : Local fit ellipse
L'ellipse Convenable Locale, calculée seulement sur la plus grande région de la carte peau.
GFE : Global fit ellipse
INTRODUCTION GENERALE
Contexte général et problématique
Internet est devenu le réseau public mondial le plus communément utilisé dans les administrations, les écoles, les entreprises et chez soi. En fait, toutes les tranches d’âge sont présentes sur la toile et leur nombre s’accroit d’une manière exponentielle.
Face à l’importance de l’utilisation d’Internet, la facilité d’accès et la diversité des services disponibles sur cette toile, une grande prise de conscience de l’importance du traitement et de l’analyse des informations véhiculées s’est avérée impérativement indispensable.
Par ailleurs, nos jeunes enfants devraient normalement ne faire usage de l’Internet que sous surveillance d’adultes. Et même pour les enfants plus âgés une initiation à un usage responsable de ce média s’impose. Ceci fait partie de l’éducation et dès lors des devoirs des parents et éducateurs. Pourtant, nous ne pouvons exclure que nos enfants qui, très souvent, maîtrisent les nouvelles techniques beaucoup plus vite que beaucoup d’adultes et qui s’y mettent sans préjugé, s’aventurent sur l’Internet en l’absence de leurs parents ou éducateurs. Il est bien compréhensible qu’on ne va pas démonter la configuration et l’enfermer dans une armoire à chaque fois qu’on quitte l’ordinateur. Cependant, il faut prendre quelques précautions pour limiter l’accès à l’internet.
Une de ces mesures par exemple est l’installation d’un filtre de réseau. Ce problème, exprimé dans un contexte informatique s’intéresse au contenu visuel et demande de mettre en place un environnement permettant de détecter qu'une image ou une vidéo fassent illégalement partie d'une collection d'images.
Différentes méthodes de filtrage d'images pour adultes existent. La couleur de la peau est utilisée en combinaison avec d'autres fonctionnalités telles que les histogrammes de texture et de la couleur. La plupart de ces méthodes s'appuient sur des réseaux de neurones ou des machines à vecteurs de support (SVM) [1] comme classificateurs. Les auteurs dans Forsyth et al. [2] ont proposé un filtre adapté qui permet d’extraire la peau en analysant la texture lisse. Après la détection de la peau, une analyse géométrique est appliquée pour détecter des parties nues dans le corps humain. Une autre méthode a été proposée par les auteurs Duan et al. [3] ; leur étude est basée uniquement sur la détection de la couleur de peau et la prise de décision est faite par les SVM. Les images sont d'abord filtrés par le modèle de la peau et les sorties sont classées par SVM. Rowley et al. [4] proposent un système qui inclut la
couleur de peau et la détection de visage, ils ont utilisé un détecteur de visage pour supprimer la propriété particulière des régions de peau. Yoo [5] suggèrent de récupérer les images étiquetées d'une base de données où une image est étiquetée comme un contenu pour adultes si la plupart des images similaires sont étiquetés de cette façon.
Les méthodes de reconnaissance des scènes vidéo sont en général propriétaires. Lee et al. [6] ont utilisé un classificateur linéaire discriminant qui combinent deux méthodes basées sur la forme et la détection des zones de peau dans les images de la vidéo. Rea et al. [7] estiment la couleur de peau avec la détection de motifs périodiques dans le signal audio d'une vidéo. Quant à Tong et al. [8] ils présentent une approche qui est entièrement basée sur l'information de mouvement. Malgré les bons résultats obtenus par ces méthodes, elles présentent l’inconvénient de s’accommoder aux variations des conditions d’éclairement, la richesse ethnique avec des teintes variées et des décors complexes.
Il nous semble donc intéressant d’utiliser des espaces de couleur invariants vis à vis de la luminance et d’appliquer des techniques de fusion. C’est dans ce contexte que s’inscrivent les travaux que nous avons développés dans le cadre de cette thèse. Nous nous sommes principalement intéressés au problème d’identification de pixels de peau dans l’image. Ce sujet de recherche est d’enjeu important dans la mesure où il est indispensable avant d’envisager des analyses et des traitements de niveau supérieur. Notre objectif est de construire un modèle de peau le plus générique possible qui servira ensuite de base pour le développement d’un système de détection des parties du corps humain (visage, main, etc.) qui sera d’une utilité potentielle pour de nombreuses applications telles que la reconnaissance des scènes vidéo pour adultes. La mise en place d’un tel système doit, au préalable, s’appuyer sur un système de détection et de segmentation des régions de peau. En effet, Internet apparaît comme un immense gisement d’informations dont le libre accès conduit à des usages indésirables tel que l’accès des enfants à des sites adultes. Il est donc nécessaire d’introduire des outils de filtrage de sites pour des applications qui visent un control parental.
Méthodologie
La reconnaissance des scènes vidéo adultes est un problème très important. Il s’avère donc nécessaire d’introduire des méthodes originales permettant la mise à disposition de traitements automatiques pour l’aide à la reconnaissance des scènes vidéo pour adultes. Toutefois, le caractère non coopératif des vidéos pour adultes conduit à intégrer davantage
de connaissances au sein du système d’identification. D’autre part, le volume de données vidéo devient de plus en plus important, ceci conduit à l’étude des méthodes semi-automatique de reconnaissance en faisant intervenir la détection de visage dans le processus de reconnaissance en particulier au niveau de la phase de détection des scènes vidéo pour adultes . Pour cela, la méthodologie générale adoptée est inspirée du processus d’extraction de caractéristiques à partir de données ce qui est similaire à la recherche d’images par le contenu. On peut dire que la phase de recherche est un cas particulier de la phase de classification du processus de reconnaissance, tandis que la phase de détection (extraction des caractéristiques) n’est qu’une étape de la phase de préparation de données. La figure 1 illustre le processus de filtrage de la vidéo pour adultes.
Figure.1: Processus de filtrage de la vidéo adultes
Le processus de filtrage de la vidéo adultes est un processus itératif et interactif qui se compose de quatre phases allant du prétraitement des images jusqu’à la phase d’évaluation des résultats, en passant par l’extraction de caractéristiques et la classification de données. Nous présentons brièvement ces quatre phases :
• Prétraitement des images adultes :
Cette phase est caractérisée par deux étapes : la détection de mouvement et la détection des régions de peau. La détection du mouvement, représente une étape très importante pour un système de vision numérique. En effet, un gain de performance considérable peut être réalisé lorsque des zones sans intérêt sont éliminées avant les phases d’analyses. Tandis que la détection de la couleur de la peau est un moyen efficace souvent utilisé pour définir une série des zones candidates.
• Analyse d'images en temps réel :
Le système analyse les flux d'images à l'aide de descripteurs visuels (couleur, texture, forme) pour en extraire une signature numérique (l'ADN de l'image).
• Reconnaissance d'images et renvoi du résultat :
Il existe des algorithmes dotés d'une capacité d'apprentissage. L'analyseur est donc capable d'apprendre et de détecter des catégories de vidéo déterminées par l’utilisateur. Ensuite pour chaque scène analysée, on renvoie un résultat sous la forme d'un score ou d'une alerte. Ce résultat provient d'une classification effectuée par le système et inférant l'appartenance de la scène à une catégorie donnée (adulte ou non adulte).
• Evaluation des résultats :
Cette dernière phase du processus consiste à évaluer les différentes méthodes utilisées dans les étapes du processus ainsi que la performance globale du système de reconnaissance. Nous avons utilisé, dans le cadre de nos travaux, le taux de bonne détection comme critère d’évaluation en se basant sur les courbes ROC [40].
Contributions et contenu du mémoire
Dans cette thèse, nous introduisons un nouveau champ d’application de la fusion de données aux collections d’images afin de définir un modèle de peau efficace. Pour des raisons diverses telles que les conditions d’éclairage, la diversité ethnique, etc., l'identification de la peau est un problème complexe. Il nous semble intéressant d’appliquer les techniques de classification dans ce contexte.
Nos premiers travaux, démarrés en 2009, ont permis la définition d’un modèle de peau permettant de discriminer les pixels de peau de ceux de non-peau. Ce modèle est essentiellement basé sur la couleur, celle-ci étant la primitive la plus riche et la plus simple à calculer. Notre approche trouve son originalité dans la fusion des trois espaces de couleurs nous aboutissons ainsi à un modèle de peau robuste aux variations de conditions de lumière et à la richesse ethnique.
Les résultats expérimentaux ont montré que notre modèle est efficace. Pour cette raison, nous l’avons utilisée comme critère déterminant dans notre processus de reconnaissance de scènes vidéo pour adultes. Ce travail a fait l’objet d’un journal international [10].
Afin d'exploiter les règles obtenues à partir de la première phase de notre travail, il était nécessaire d’utiliser la détection de mouvement qui est une étape très avantageuse pour un système de vision numérique. En effet, un gain de performance considérable peut être réalisé lorsque des zones sans intérêt sont éliminées avant les phases d’analyses. Ce travail a fait l’objet d’une communication internationale [11].
Enfin, nous avons réalisé une application dans laquelle la classification des scènes vidéo pour adultes est une étape préalable nécessaire. Ce dernier travail a permis de mettre au point un système, permettant un filtrage sémantique du contenu adulte.
L’ensemble des travaux ont donné lieu à : • 3 revues internationales
• 8 conférences internationales avec actes et comité de lecture • 3 conférences nationales avec actes et comité de lecture • 1 poster
Organisation du manuscrit
Le travail réalisé dans le cadre de cette thèse est organisé en quatre chapitres. Le premier chapitre énonce la problématique générale de la thèse et les travaux effectués dans la littérature sur la modélisation d'un système de recherche et d'indexation par le contenu sémantique. Puis, il aborde la description globale de l'information vidéo, et décrit les données sur lesquelles nous avons travaillé.
Le second chapitre expose un état de l'art sur les principaux espaces de couleur pour la détection de la peau. Ensuite, il présente les différentes méthodes de détection de la peau. Ces méthodes ont été classées et présentées en trois approches. Enfin, il est dédié à la définition d’un modèle de peau qui s’appuie sur des techniques de fusion des différents espaces de couleur.
Le troisième chapitre s'intéresse à l’analyse et la modélisation de séquences vidéo. Cette phase consiste d’une part à détecter le mouvement des objets et d’autre part, à utiliser une méthode hybride. C’est une fusion entre la méthode de détection de la couleur de peau et la méthode du « template matching » qui est basée sur la création d’un modèle de visages.
Nous présentons dans la dernière section de ce chapitre une deuxième phase qui consiste à calculer les différents descripteurs qui caractérisent les images adultes.
Le dernier chapitre constituant les principales contributions, présente l’approche élaborée pour la reconnaissance des scènes vidéo pour adultes. L’accent est mis d’une part, sur le processus de détection, extraction et modélisation des caractéristiques visuelles des images adulte et d’autre part, sur l’architecture du système de reconnaissance adapté à l’identification des vidéos adultes.
Dans ce chapitre nous exposons quelques méthodes de classification couramment utilisées dans la phase de fouille de données, en particulier les méthodes de classification supervisées telles que les méthodes bayésiennes, les réseaux de neurones et les machines à vecteurs de support. Ensuite, nous présentons le cadre formel du travail réalisé en ce qui concerne l’extraction des caractéristiques des vidéos, leur modélisation et la phase de reconnaissance. A la suite des différentes réalisations, les résultats expérimentaux sont exposés. Une nouvelle méthode hybride de détection adaptée aux vidéos adultes est présentée. C’est une méthode qui permet de pallier les limites des méthodes existantes. En fin de ce chapitre, nous étudions l’influence de la fusion sur les performances globales du système de reconnaissance.
Nous dressons par la suite l’ensemble des conclusions liées aux différents volets de nos travaux, qui ouvrent un ensemble de perspectives sur des problématiques adjacentes.
Analyse Multimédia
Sommaire
1.1 Introduction ... 21 1.2 Etat de l’art et étude des systèmes existants ... 22 1.2.1 Les approches de filtrage. ... 22 1.2.2 Logiciels existants ... 24 1.3 Le fossé sémantique ... 26 1.4 Le document vidéo ... 27 1.5 Analyse du contenu de la vidéo ... 28 1.6 Modélisation du Contenu Vidéo ... 28 1.7 Les différents formats de fichiers vidéo numériques ... 30 1.8 Les images de références ... 31 1.9 Description générale du système de reconnaissance ... 32 1.9.1 Extraction des caractéristiques ... 33 1.9.2 Classification ... 33 1.10 La segmentation temporelle de vidéo ... 34 1.10.1 Segmentation en plans ... 35 1.10.2 Segmentation en scènes ... 35 1.11 La segmentation d'image ... 36 1.11.1 Segmentation en blocs ... 36 1.11.1 Segmentation en régions ... 37 1.12 Les critères pour les mesures des performances ... 38 1.13 Présentation des données ... 38 1.14 Conclusion ... 40
1.1 Introduction
De nos jours, Internet prend une place grandissante dans la vie quotidienne et dans le monde professionnel. Le public qui y a accès est de plus en plus large, mais aussi de plus en plus jeune. Les enfants trouvent chaque jour un accès plus facile à la toile [34]. Cet accès de plus en plus large ne va pas sans inconvénients, les sites à caractère adulte, violent, raciste, etc. en sont un. En effet, ces sites sont souvent en accès libre, ce qui pose un problème évident vis à vis des enfants. Alors, la question qui se pose est de savoir comment faire pour protéger nos enfants contre des données illicites ?
Pour faire face à ce fléau, il existe un ensemble de produits commerciaux sur le marché qui proposent des solutions de filtrage. Un nombre significatif de ces produits se basent sur une liste de mots clés peu convenable pour les enfants (nudité, adulte, etc.)
Dans cette thèse, nous présentons notre solution de classification et de filtrage des scènes vidéo pour adultes. À la différence de la majorité des logiciels commerciaux, qui sont principalement basés sur la détection des mots interdits ou sur une liste noire, collectés et mis à jour manuellement, notre solution, réalise la classification et le filtrage à caractère adulte par un apprentissage qui s’appuie sur une combinaison judicieuse de plusieurs algorithmes de classification et une analyse du contenu structurel et visuel.
Dans ce chapitre, nous décrivons tout d’abord les approches de filtrage de sites adultes et nous présentons quelques logiciels existants les plus connus sur le marché, nous allons ensuite introduire et comprendre le problème du fossé sémantique, puis, nous allons procéder à la description du support vidéo, pour mieux décrire la structure générale d'un système de reconnaissance, suivi d'une présentation des techniques de segmentation d'image et de la vidéo, ainsi que les critères pour la mesure des performances et l’évaluation du système. Enfin, nous allons présenter les bases d’apprentissage et de test que nous allons utiliser dans nos protocoles expérimentaux.
1.2 Etat de l’art et étude des systèmes existants
De nombreux travaux de recherche dans la littérature ont déjà montré l’intérêt croissant pour la classification et le filtrage de sites Web dans le but de limiter l’accès des contenus préjudiciables sur la toile. Il existe également une panoplie de produits commerciaux de filtrage sur le marché. Dans cette partie, nous décrivons tout d’abord les approches de filtrage de sites pour adultes ensuite nous présentons quelques logiciels existants.
1.2.1 Les approches de filtrage.
Il existe quatre approches de filtrage de sites pour adultes : la technologie de l’étiquetage, le filtrage par liste de sites autorisés ou interdits, le filtrage par mots clés et le filtrage par analyse du contenu multimédia.
• Technologie de l’étiquetage
Il existe divers systèmes d'étiquetage qui sont utilisables pour identifier les contenus circulant sur Internet, les plus connus sont basés sur un protocole standardisé appelé PICS (Platform for Internet Content Selection). Le standard PICS permet à n'importe quelle organisation de définir son propre système de classification et de donner ainsi la possibilité
aux personnes utilisant ce système de bloquer (ou de rechercher) des sites en fonction de leur contenu. Il est important de signaler que le standard PICS n'est pas un système de classification, mais une méthode de codage utilisée par les systèmes de classification. Lorsque la protection du navigateur est activée et qu'une personne utilise ce même navigateur pour accéder à une page Internet, celui-ci compare la cote de la page avec les niveaux ayant été définis précédemment comme acceptables par l’utilisateur. Si la page comporte un contenu correspondant à des niveaux supérieurs à ceux définis, le navigateur bloque l'affichage de la page. Les systèmes d'étiquetage les plus connus à l'heure actuelle sont ceux qui sont proposés par le RSACi (Recreational Software Advisory Council) et SafeSurf. Tous les deux sont basés sur le protocole PICS.
L’utilisation d’étiquettes pour filtrer le contenu nécessite plusieurs opérations : création, stockage, mise à jour et diffusion des étiquettes, authentification des données des étiquettes et enfin utilisation de ces données par les logiciels de filtrage pour classifier les pages Web dans la catégorie acceptable ou la catégorie inacceptable.
• Filtrage par liste de sites autorisés ou interdits
Les techniques basées sur les listes d’URL permettent de créer un Internet où tout est autorisé sauf la consultation de quelques sites. On garde donc la possibilité de naviguer librement d’un site à un autre, tout en restreignant les risques d’accéder à un site inapproprié. Cependant, une liste noire ne peut jamais être exhaustive puisque de nouveaux sites apparaissent constamment, les logiciels de filtrage ne pourront pas, même avec des mises à jour régulières, bloquer la totalité des sites pour adultes. Chaque liste sera obsolète dès le moment où elle aura été mise sur le marché puisque tout nouveau site apparaissant après la mise à jour ne sera pas contenu sur cette liste et ne sera, par conséquent, pas bloqué.
Il arrive souvent que certains sites à contenu tout à fait licite disparaissent, et leurs adresses peuvent être récupérées par des sites adultes d’où la nécessité d’une vérification régulière par l’administrateur.
• Filtrage par mots clés
En complément aux listes « noire » et « blanche » les logiciels de filtrage peuvent également effectuer un contrôle des contenus par mots clés ou phrases clés. À l’aide d'un outil d'analyse de texte, le programme vérifie tous les mots de la page avant que celle-ci ne s’affiche. Si un mot « interdit » est décelé, que ce soit dans une page Web, dans le titre d'un groupe de discussion ou dans celui d'un forum de dialogue en direct, le logiciel de filtrage bloquera l'affichage de ces données.
Ce système se heurte généralement au problème de la langue : une même expression devant être enregistrée dans toutes les langues véhiculées sur Internet. Par ailleurs les éditeurs de sites pour adultes déploient des trésors d’imagination pour trouver des orthographes de substitution, par exemple en écrivant S.E.X.E au lieu de sexe.
• Filtrage par analyse du contenu multimédia.
La classification des sites adultes par une analyse intelligente du contenu Web s’intègre dans une problématique plus générale, celle des systèmes automatiques de classification et de catégorisation de sites Web. La réalisation de tels systèmes doit s’appuyer sur un processus d’apprentissage automatique et plus précisément sur un apprentissage supervisé.
L’analyse intelligente du contenu est basée sur le contenu non textuel. Une page web contient en général des images ou des vidéos. Pour ce faire, les données numériques de l’image ou la vidéo vont subir des mesures en fonction de différents critères à savoir : Couleur, texture et forme. L’objectif est de mettre en évidence des invariants ou informations stables qui permettront la comparaison et la classification. Cependant la technologie numérique permet de produire, stocker des volumes de plus en plus importants de données multimédia dans les sites Web, automatiser l’analyse et la recherche dans ces contenus numériques est devenu un enjeu crucial pour les applications de filtrages.
1.2.2 Logiciels existants
Pour compléter notre étude sur les travaux existants, nous présentons quelques exemples de produits commerciaux de filtrage existants à savoir :
• IE (Internet Explorer) • Cybersitter 2002 • Net Nanny 4.0.4
• Norton Internet Security 2003 • PureSight Home 2.6
• Cyber Patrol 5.0 • WebGuard 2005
Des tests de performance de ces logiciels ont été réalisés [64]. Les résultats de ces tests sont décrits dans la figure suivante :
Figure 1. 1. Comparaison entre les logiciels existants [64]
Comme montre la figure ci-dessus, le taux de bonne classification est donné par le système WebGuard, ce système utilise un filtre par une analyse multimédia à la différence des autres systèmes qui sont principalement basés sur la détection des mots interdits ou sur une liste noire. Nous signalons que les tests sur ces systèmes commerciaux de filtrage les plus populaires, ont été effectués sur une base composée de 200 pages pour adultes et 300 pages non adultes.
Etant donné la nature dynamique et la quantité énorme des documents Web et compte tenu de l’importance des images dans ces documents Web, en particulier pour les sites adultes, un système de filtrage efficace doit inclure une analyse du contenu visuel.
Pour cela, nous avons opté pour un système automatique de détection du contenu adulte en se basant sur l’analyse des scènes vidéo pour adulte. En plus, Notre solution consiste à considérer le nombre d’images de la vidéo classifiées comme image potentiellement adulte selon une présence importante de peau, pour cette raison nous s’intéressons par la suite à étudier la détection de la peau qui présente une étape très importante dans la reconnaissance des scènes vidéo pour adulte et par conséquent pour le filtrage des sites illicites.
Figure 1. 2. Architecture du filtre.
La figure 1.2 montre l’architecture globale du système qui suscite la création d’un certain nombre de filtre spécifiques. Un moniteur lance un ou plusieurs de ces filtres selon le site sollicité. Les différents blocs peuvent être créés et améliorés indépendamment les uns des autres ; ce qui donne à cette architecture un aspect évolutif. Cette indépendance permettra, en plus, de mieux structurer la conception de l’application.
-Plusieurs intervenants peuvent développer en parallèles différentes parties du système. -Chaque partie peut être testée et validée indépendamment des autres.
Le filtre global est donc construit autour de plusieurs modules de filtrage. Ces modules sont basés sur l’analyse des URL des sites d’une part, et sur l’analyse des images contenues dans ces sites d’autres part. C’est dans ce deuxième module que s’inscrit le travail de cette thèse.
1.3 Le fossé sémantique
Si nous, humains, savons parfaitement interpréter et détecter le contenu d'une image ou d'une information, nous sommes limités lorsqu'il s'agit de traiter une grande quantité d'informations. Un comportement inverse de celui de la machine, qui ne trouve pas de problème à traiter une tâche répétitive donnée, mais limitée lorsqu'il s'agit d'interpréter ou d'extraire automatiquement des concepts à partir de données numériques, ce qui est appelé fossé sémantique, définit comme suit : « le manque de concordance entre les informations qu’on peut extraire des données visuelles et l’interprétation qu’ont ces mêmes données pour un utilisateur dans une situation déterminée » [12].
Dans ce contexte, il semble important d’apporter des solutions pour la description sémantique des images, sous la forme d’associations entre des éléments sémantiques (concepts) et des éléments de bas niveau (caractéristiques des images).
Notre objectif dans ce travail est alors d’exploiter l’information contenue dans ces données, et d’en extraire une sémantique fiable pour un besoin de classification et plus particulièrement pour une reconnaissance automatique des vidéos pour adultes.
Dans notre approche, nous utilisons une représentation des caractéristiques symboliques et des caractéristiques numériques dans un même espace pour produire à la fin un vecteur de descripteur représentant le contenu de l’image.
1.4 Le document vidéo
Formellement, un document vidéo est défini comme une combinaison de flux d’information. Principalement, deux sources d’informations composent ce document à savoir l’image et le son, qui sont synchronisés pour former une histoire. Le flux visuel comporte une séquence d’images fixes qui selon l’axe temporel apparaissent animées à une fréquence de 24 à 30 images par seconde. Le flux sonore est composé d’un ou plusieurs canaux (mono, stéréo). Le signal sonore est typiquement échantillonné entre 16000 et 48000 Hertz. Un troisième flux d’information généralement associée aux documents vidéo est le texte. Il provient soit d’un flux séparé, soit il est dérivé des sources audio et visuelle. Pour le stockage, la manipulation et la recherche de documents vidéo, il est nécessaire de se doter d’un moyen d’organiser l’information. On peut considérer qu’il existe plusieurs niveaux de structure liés à la donnée vidéo, il s’agit d’une organisation hiérarchique issue du monde de la production vidéo ou cinématographique. Cette hiérarchie met en évidence des séquences de granularités différentes. Un premier niveau de structure, appelé « plan », correspond au premier niveau de montage. Les niveaux supérieurs visent à monter en abstraction de façon hiérarchique, et tendent vers un niveau sémantique. En principe, ces différents niveaux de hiérarchie sont nommés selon le type de contenu du document vidéo (scène, histoire, documentaire, etc.). Une séquence vidéo brute est une suite d'images fixes, qui peut être caractérisée par trois principaux paramètres : sa résolution en luminance, sa résolution spatiale et sa résolution temporelle.
La résolution en luminance détermine le nombre de nuances ou de couleurs possibles pour un pixel. Celle-ci est généralement de 8 bits pour les niveaux de gris et de 24 bits pour les séquences en couleurs. La résolution spatiale, quant à elle, définit le nombre de lignes et de
colonnes de la matrice de pixels. Enfin, la résolution temporelle est le nombre d'images par seconde [14].
1.5 Analyse du contenu de la vidéo
Les documents vidéo peuvent avoir des contenus extrêmement variés (télévisés, documentaires, films, publicité, vidéosurveillance, etc.). La plupart du temps, ces documents ont une (ou plusieurs) structures internes. Comme les documents eux-mêmes, ces structures peuvent être très variées. Le type de structure dont il est question ici est relatif au contenu sémantique du document. Il s’agit de structures qui ont un sens pour l’utilisateur. À ce titre, elles peuvent parfois apparaître mal définies, ambiguës ou subjectives. Notre thèse s’intéresse au contenu illicite de la vidéo, et en particulier, au contenu à caractère adulte auquel les enfants se retrouvent très souvent confronté.
En ce qui concerne l’analyse du contenu, on peut distinguer deux niveaux de descriptions qui sont liés aux données vidéo :
• Le niveau signal (ou « bas niveau ») : proche de la représentation numérique des documents, il s’attache à décrire les caractéristiques « physiques » des segments d’une vidéo comme la couleur, la texture et la forme. Les informations correspondant à ce niveau sont en général de type numérique (tableaux de nombres, histogrammes de couleur par exemple).
• Le niveau sémantique (ou « haut niveau ») : proche de la façon dont les humains représentent le contenu des documents, il vise la description des concepts présents et des relations entre eux. Les informations correspondantes à ce niveau sont en général de type symbolique (concepts, relations, graphes) [14].
1.6 Modélisation du Contenu Vidéo
La structure la plus classique consiste à décomposer la vidéo en des unités (segments) dont chacune représente un niveau de description. Cette décomposition est similaire à la modélisation hiérarchique du contenu vidéo.
Dans un document vidéo, on distinguera des séquences qui correspondent à des unités sémantiques de la vidéo (thème, sujet, etc.). Dans des vidéos de taille importante, plus le contenu est varié plus le nombre de séquences est important. Les séquences peuvent elles mêmes être décomposées en scènes. Ces scènes, sont composées d’un ou plusieurs plan(s). Chaque plan correspond à une prise de vue, avec ou sans mouvement de caméra (plan fixe). Les plans sont séparés par des transitions.
Dans une vidéo, on peut définir des entités élémentaires (éléments d’information) significatives comme des personnages, des éléments décors, des objets, etc. On peut également définir des objets de granularité plus fine : des parties d'éléments comme le visage du personnage. Ces entités sont regroupées au niveau description du contenu vidéo et sont appelées des entités « Classe ».
On peut également définir une entité événement (event) : un événement est « quelque chose qui arrive ». Il peut être décrit par les classes ou les occurrences de classe qui interviennent dans « ce qui arrive » et par des relations qui définissent « ce qui arrive ». Un événement se déroule en général pendant un certain intervalle de temps [14]. La figure 1.3 illustre la structure d'un document vidéo.
Figure 1. 3. Structure d'une vidéo.
Pour la détection des transitions franches, chaque image est divisée en 16 blocs sans chevauchement, puis est extrait un histogramme pour chacun. Il suffit de comparer la similarité entre les images de la fenêtre coulissante avec l'image courante à travers le calcul d'une distance Euclidienne par exemple, en donnant un poids à chaque bloc. Ensuite, on trie de façon décroissante les distances obtenues et on analyse ce classement. L'algorithme arrive à détecter une coupure lorsque le nombre d'images en aval classées dans la première partie du classement est supérieur à un seuil préfixé. Il a été observé qu'un mouvement rapide dans un plan peut fausser le résultat de la segmentation. Pour cela, on donne plus d'importance aux régions qui représentent le fond de l'image que les régions centrales. Ceci a permis l'obtention d'un gain de performance sur les données.
1.7 Les différents formats de fichiers vidéo numériques
Il existe plusieurs formats de vidéo numérique. Tous ces formats sont compressés car, sans compression, 1 seconde de vidéo occuperait une taille non conciliable avec sa manipulation et son transport (22 Mo par seconde).
Avec un tel débit, on se trouve confronté à deux problèmes :
- La capacité de stockage : la vidéo non compressée nécessite énormément de place sur un disque dur.
- La rapidité de transmission.
Pour palier à ces deux inconvénients, il faut réduire le débit des données donc compresser les informations. Ces méthodes de compression vont engendrer une dégradation de la qualité de l’image. Elles sont basées sur deux constations :
- La redondance spatiale : dans une image, deux points voisins sont souvent similaires. On parle de compression spatiale.
- La redondance temporelle : deux images successives sont souvent fort similaire. On parle de compression temporelle. Dans ce cas, deux méthodes sont envisagées : le codage par différence entre les images successives et le codage par prédiction de mouvement.
La compression des données va donc consister à déterminer ces redondances et les éliminer. Plusieurs formes de compressions existent, plus ou moins standardisées, qui réduisent la taille des fichiers pour une manipulation plus aisée sur ordinateur.
La vidéo est compressée par ce que l’on appelle des CODEC (Codeurs/Décodeurs). Il existe deux types de CODEC, les CODEC logiciels et les CODEC matériels. Le codec a pour rôles de compresser la vidéo pour la rendre transportable et la décompresser pour la rendre lisible par l’utilisateur [15].
Le choix du codec utilisé doit dépendre du type de séquence vidéo, du système d’exploitation, utilisé mais aussi de plusieurs facteurs à savoir:
- La qualité.
- Le taux de transfert des données. - Le volume de stockage.
- Le temps nécessaire à la compression et à la décompression des informations.
L’encodage des séquences vidéo donne naissance à différents formats. Les principaux à employer sur Internet pour diffuser de la vidéo ou de l'audio sont :
Le format MPEG (Motion Picture Expert Group) : Le grand principe de ce type de codage repose sur les redondances qui existent entre les images successives. On trouve plusieurs niveaux de la norme MPEG : MPEG1, MPEG2 et MPEG4.
Le format AVI (Audio Video Interleave) utilisé pour les fichiers Motion Jpeg. Les fichiers numériques qui peuvent être lus par un logiciel gratuit tel que Fast.
Le format MOV (Quick time) utilisé pour les fichiers vidéo Quick time.
Certain formats de vidéo numérique se reconnaissent par la forme de leur enveloppe de transport. D’autres utilisent une structure de transport standard, cas du format AVI ou MOV qui ne permettent pas de déterminer le CODEC utilisé [15].
1.8 Les images de références
On appelle image de référence, l'image qui va être utilisée pour prédire une image et estimer le mouvement à compenser. Cette image peut être simplement une image précédemment codée dans la séquence. Elle est souvent utilisée sous la forme d'objet mosaïque qui est construit à partir d'une séquence de vues de l'objet considéré. Le principe de construction consiste à recaler les images (ou portions d'images) traitées dans le référentiel de l'objet mosaïque. Ces images peuvent être utilisées pour représenter sur une seule image la totalité d'une scène, la figure 1.4 présente ce résultat. Cette mosaïque est généralement plus grande qu'une image de la séquence.
Figure 1. 4. Exemple d'image mosaïque construite à partir d'un ensemble d'images.
Il est important de souligner qu'il est inutile d'utiliser toutes les images d'un plan pour obtenir une bonne extraction des caractéristiques visuelles. En effet, il serait par la suite impossible de conserver et d'utiliser cette information qui est par ailleurs redondante. Ainsi, une sélection d'une ou plusieurs images représentatives des plans serait nécessaire. Or, on peut déjà noter que si un plan présente de faibles mutations, il pourra être considéré comme statique. Il suffit alors de choisir l'image qui est la plus identique aux autres. En pratique,
cette recherche exhaustive est difficilement réalisable. Les approches empiriques sélectionnent simplement la première, la dernière ou l'image médiane du plan [16].
Des travaux comme ceux de Yueting et al. [17] proposent une approche par regroupement des images similaires pour obtenir la ou les images représentatives du plan. Toutefois, lorsqu'un plan présente du mouvement, il est intéressant de sélectionner les images représentatives en fonction de l'intensité ou des variations du mouvement. Pour cela, Kobla et al. [18] utilisent le domaine compressé MPEG pour mesurer le déplacement de la caméra dans le plan et découpent ce dernier en sous plans afin de limiter l'amplitude du mouvement. Liu et al. [19] proposent une mesure de l'énergie du mouvement dans le domaine MPEG afin d'identifier les images-clés du plan.
Les avantages de la détection dans des images fixes et l’aspect temporel d’une vidéo permet d’améliorer la détection et d’effectuer le suivi de la scène adulte.
1.9 Description générale du système de reconnaissance
Le principe de base du processus de reconnaissance est d’effectuer une classification pour retrouver un objet spécifique dans une vidéo. Cette étape consiste à extraire les connaissances à partir des données en utilisant les méthodes de classification. En absence d’une règle générale pour choisir le meilleur classificateur, nous avons étudié et comparé de manière empirique les réseaux de neurones (ANN) et les SVM pour choisir celui le plus adapté à nos données. L’architecture du système est donc basée sur le contenu présenté par les deux approches: l'extraction des caractéristiques et la classification.
La première étape implique l'extraction des caractéristiques d'un document, à travers la capture des couleurs, des textures, des formes et du mouvement dans un plan, etc.
La seconde étape permet de compresser l'information extraite tout en conservant l'essentiel. La figure 1.5 illustre l'architecture générale du processus de reconnaissance des vidéos.
Figure 1. 4. Description générale du système de reconnaissance.
1.9.1 Extraction des caractéristiques
Cette approche a pour but d’extraire l’ensemble des caractéristiques à partir desquelles nous allons prendre notre décision finale sur la vidéo à analyser. Par conséquent, les caractéristiques extraites lors du processus de la détection des vidéos pour adulte capable d'apprendre et de détecter des catégories de vidéos déterminées par l’utilisateur. En fonction du type d’extraction, l’utilisateur peut alors formuler sa requête par des descripteurs de bas
niveau (tel que la couleur, la texture, la forme, etc.) et/ou par des éléments sémantiques [21]. Ce qui induisait qu’un utilisateur devait formuler une requête soit directement par des caractéristiques de bas niveau, soit par une ou plusieurs images exemples, à partir desquelles le système extrayait les descripteurs.
La structuration des documents vidéo en images, plans, scènes ou histoires induit des différences dans la nature des données extraites lors des différentes étapes du processus de reconnaissance. Ces données sont typiquement hétérogènes. Au début du processus, les premières informations extraites sont des descripteurs de bas niveau, visant à modéliser et représenter un signal. A l’autre bout du processus, les concepts sont des éléments sémantiques. Néanmoins, il existe une grande diversité de concepts susceptibles de décrire un document multimédia. Un concept peut représenter un objet, une scène (lieu, évènement), une personne, une action, etc.
1.9.2 Classification
La classification de données est définie en statistique comme une phase de décision. Elle consiste à attribuer une classe à une observation inconnue en se basant sur des observations connues ou bien sur des règles statistiques [24].