+
Towards a data model for
(inter)textual relationships
Connecting Ancient Egyptian texts and understanding scribal practices
Stéphane Polis (F.R.S.-FNRS – ULg) Vincent Razanajao (ULg)
+
Outline of the talk
n
Background information about the Ramses Project &
Ramses Online
n
Evolution of the data model between 2006 and 2016
n
Data models: state-of-the-art in digital editing
n
Towards a data model for (inter)textual relationships
in Ancient Egyptian
+
The Ramses Project &
Ramses Online
Background information
+
The Ramses Project
Goal
n Build a richly annotated corpus of Late Egyptian texts
4
1000
+
The Ramses Project
Goal
n Build a richly annotated corpus of Late Egyptian texts
5
1000
+
The Ramses Project
Goal
n Build a richly annotated corpus of Late Egyptian texts
n Useful both for philologists and linguists
+
The Ramses Project
JAVA software (MySQL – texts stored in XML)
n LexiconEditor
n TextEditor
+
The Ramses Project
What kind of data?
n Hieroglyphic spellings
+
The Ramses Project
What kind of data?
n Hieroglyphic spellings
n Lemmatization and morphological annotation
+
The Ramses Project
What kind of data?
n Hieroglyphic spellings
n Lemmatization and morphological annotation
n Textual criticism
+
The Ramses Project
What kind of data?
n Hieroglyphic spellings
n Lemmatization and morphological annotation
n Textual criticism
n Translation (French / English)
+
The Ramses Project
History (2006-2016)
+
The Ramses Project
The corpus
n Number of witnesses 13 0 1000 2000 3000 4000 5000 6000 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015+
The Ramses Project
The corpus
n Number of occurrences 14 0 100000 200000 300000 400000 500000 600000 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015+
Ramses Online (ramses.ulg.ac.be)
+
Ramses Online (ramses.ulg.ac.be)
n Responsive website based on Bootstrap
+
Ramses Online (ramses.ulg.ac.be)
n Responsive website based on Bootstrap
+
Ramses Online (ramses.ulg.ac.be)
n Responsive website based on Bootstrap
+
Ramses Online (ramses.ulg.ac.be)
n Responsive website based on Bootstrap
n With powerful linguistic searching capabilities
+
Ramses Online (ramses.ulg.ac.be)
n Responsive website based on Bootstrap
n With powerful linguistic searching capabilities
n In interaction with its users
+
Ramses Online (ramses.ulg.ac.be)
n Responsive website based on Bootstrap
n With powerful linguistic searching capabilities
n In interaction with its users
+
Collaborations
22
n
TEI interchange format
n Laurent Coulon (EPHE – Paris)
n Frederik Elwert (CERES – Bochum)
n Emmanuelle Morlock (HiSoMA – CNRS)
n Stéphane Polis (F.R.S.-FNRS – Liège)
n Vincent Razanajao (ULg – Liège)
n Serge Rosmorduc (CNAM – Paris)
n Simon Schweitzer (BBAW – Berlin)
+
Collaborations
23
n
TEI interchange format
n Laurent Coulon (EPHE – Paris)
n Frederik Elwert (CERES – Bochum)
n Emmanuelle Morlock (HiSoMA – CNRS)
n Stéphane Polis (F.R.S.-FNRS – Liège)
n Vincent Razanajao (ULg – Liège)
n Serge Rosmorduc (CNAM – Paris)
n Simon Schweitzer (BBAW – Berlin)
n Daniel A. Werning (EXC Topoi – Berlin)
n
Linked metadata
+
Collaborations
24
n
TEI interchange format
n Laurent Coulon (EPHE – Paris)
n Frederik Elwert (CERES – Bochum)
n Emmanuelle Morlock (HiSoMA – CNRS)
n Stéphane Polis (F.R.S.-FNRS – Liège)
n Vincent Razanajao (ULg – Liège)
n Serge Rosmorduc (CNAM – Paris)
n Simon Schweitzer (BBAW – Berlin)
n Daniel A. Werning (EXC Topoi – Berlin)
n
Linked metadata
n Thot (thot.philo.ulg.ac.be)
+
Collaborations
25
n
TEI interchange format
n Laurent Coulon (EPHE – Paris)
n Frederik Elwert (CERES – Bochum)
n Emmanuelle Morlock (HiSoMA – CNRS)
n Stéphane Polis (F.R.S.-FNRS – Liège)
n Vincent Razanajao (ULg – Liège)
n Serge Rosmorduc (CNAM – Paris)
n Simon Schweitzer (BBAW – Berlin)
n Daniel A. Werning (EXC Topoi – Berlin)
n
Linked metadata
n Thot (thot.philo.ulg.ac.be)
n Trismegistos (http://trismegistos.org/)
+
Evolution of the data model
Between 2006 and 2016+
Evolution of the data model
n The original model (2006)
n The Thot Data Model (TDM – 2016)
n Towards TDM 2.0
+
Evolution of the data model
n The original model (2006)
28
Following the egyptological practice, the decision was made to encode in hieroglyphs (and to annotate) every single witness of each text (envisioned as an abstraction).
The document, on the other hand, was seen as the object on which multiple witnesses could occur.
+
Evolution of the data model
n The original model (2006)
29
+
Evolution of the data model
n The original model (2006)
30
Synoptic edition of Sinuhe (Koch 1990: 8,2-7)
Witness 1 Witness 2 Witness 3 Witness 4 Witness 5 Witness 6
+
Evolution of the data model
n The original model (2006)
31
Synoptic edition of Sinuhe (Koch 1990: 8,2-7)
Witness 1 Witness 2 Witness 3 Witness 4 Witness 5 Witness 6 One text
+
Evolution of the data model
n The original model (2006)
32
+
Evolution of the data model
n The original model (2006)
33 Witness 2 Administrative text (account) Witness 1 Literary text (hymn) One document
+
Evolution of the data model
n The original model (2006)
34 One document Witness 2 Administrative text (account) Witness 1 Literary text (hymn)
+
Evolution of the data model
n The original model (2006)
35
“The [documentary and textual] dimensions are incapable of disconnection: (…) they negatively constitute one another
and (...) this consitution requires human agency at every step, from composition to reception.”
+
Evolution of the data model
n The original model (2006)
n The Thot Data Model (TDM – 2016) & material philology
+
Evolution of the data model
n The original model (2006)
n The Thot Data Model (TDM – 2016) & material philology
+
Evolution of the data model
n The original model (2006)
n The Thot Data Model (TDM – 2016) & material philology
+
Evolution of the data model
n The original model (2006)
n The Thot Data Model (TDM – 2016) & material philology
n St. Polis & V. Razanajao (2016), Ancient Egyptian texts in contexts.
Towards a conceptual data model (the Thot Data Model – TDM), to appear in Bulletin of the Institute of Classical Studies (special issue: ‘Digital approaches to the Ancient World’).
+
Evolution of the data model
n The original model (2006)
n The Thot Data Model (TDM – 2016) & material philology
+
Evolution of the data model
n The original model (2006)
n The Thot Data Model (TDM – 2016) & material philology
n Towards TDM 2.0
n Why?
+
Evolution of the data model
42
!
O. Nash 14
O. Gardiner O. DeM 1048 O. DeM 1046
P. Mag.Isis (P. CGT 54051) = the main Witness of the Text (Isis magical papyrus)
+
Evolution of the data model
43
!
P. Mag.Isis (P. CGT 54051 ro)
P. Chester Beatty XI (ro)
P. Chester Beatty XI is composed of
– The story of Isis & Ra (ro 1,1 – 4,1)
– A group of magical spells (ro 4,2–10)
– A magical text against scorpions (ro, fgmts A–L)
– The end of a magical text (vo 1,1–3)
– An account (vo 1,4–10)
– An hymn to the god Amun (vo 2–3)
– A group of formulae for “safety upon the river” (vo, fgmts A–D) P. CGT 54051 is composed of
– A group of incantations (ro 2,1–8)
– A formula for bandaging (ro 2,8–12)
– The story of Isis & Ra (ro 2,12 – 5,5)
– A group of formulae (ro 5,12 – 6,3)
+
Evolution of the data model
44 Witness A = « P. Mag. Isis » Witness B on « P. Chester Beatty XI » Section 1 Section 2 Section 3 Section 1 Section 2 Section 3 hasPart hasPart hasPart hasPart
+
Evolution of the data model
45 Witness A = « P. Mag. Isis » Witness B on « P. Chester Beatty XI » Text « Isis and Ra »
Section 1 Section 2 Section 3 Section 1 Section 2 Section 3 hasPart hasPart hasPart hasPart isActualizationOf isActualizationOf
+
Evolution of the data model
46 Witness A = « P. Mag. Isis » Witness B on « P. Chester Beatty XI » Text « Isis and Ra »
Section 1 Section 2 Section 3 Section 1 Section 2 Section 3 hasPart hasPart hasPart hasPart isActualizationOf isActualizationOf Complex Text « Magical - Isis » Complex Text « Magical - Beatty »
+
Evolution of the data model
47 Witness A = « P. Mag. Isis » Witness B on « P. Chester Beatty XI » Text « Isis and Ra »
Section 1 Section 2 Section 3 Section 1 Section 2 Section 3 hasPart hasPart hasPart hasPart isActualizationOf Complex Text « Magical - Beatty » hasPart hasPart Complex Text « Magical - Isis »
+
Evolution of the data model
n The original model (2006)
n The Thot Data Model (TDM – 2016)
n Towards TDM 2.0
n Why?
n With which model can we handle such cases?
n Relationships between witnesses
n Relationships between texts
+
Data models
State-of-the-art in digital editing+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
51
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (NLP)
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
n
Theoretical framework
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
n
Theoretical framework
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
n
Theoretical framework
59
The text is seen as “a mosaic of quotations; any text is the absorption and
transformation of another” (1986: 37)
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
n
Theoretical framework
60
“any text is a new tissue of past citations. Bits of code, formulae, rhythmic models, fragments of social languages, etc., pass into the
text and are redistributed within it, for there is always language before
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
n
Theoretical framework
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
n
Theoretical framework
G. Genette (1997 [1982]), Palimpsests: Literature in the second degree
n Intertextuality n Paratextuality n Metatextuality n Hypertextuality n Architextuality 62
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
n
Theoretical framework
n
Data models
n “In the context of digital editing, by modelling we mean at least two
types of conceptualization: the one that tries to organize entities such
as texts, documents, works, along with their relationships and how
they have happened to come into being, and the analytical process of establishing the kind and purpose for the production of a new edition, its implied community of users and what features best represent their
various needs.” (Pierazzo 2015: 48)
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
n
Theoretical framework
n
Data models
n The FRBR data model (1997 [2009])
+
Data models for digital editing
n
Four basic elements
+
Data models for digital editing
n
Four basic elements
n
Relationships between these elements
+
Data models for digital editing
n
Four basic elements
n
Relationships between these elements
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
n
Theoretical framework
n
Data models
n The FRBR data model (1997 [2009])
‘Neo-platonistic idealism’
Cf. Rafferty (2015) “the notion of work points to intertextuality, with all its potential for rich analysis, but at the
same time it embeds deep in its system
the logocentrism of the ideal signified”
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
n
Theoretical framework
n
Data models
n The FRBR data model (1997 [2009])
n FRBRoo (> CIDOC-CRM)
+
Data models for digital editing
n
FRBRoo is the FRBR ontology revised and expressed in an
object-oriented form compatible with that of the CIDOC-CRM
n Strong orientation towards modelling intellectual processes
+
Data models for digital editing
n
FRBRoo is the FRBR ontology revised and expressed in an
object-oriented form compatible with that of the CIDOC-CRM
n Strong orientation towards modelling intellectual processes
n Addition of some interesting elements
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
n
Theoretical framework
n
Data models
n The FRBR data model (1997 [2009])
n FRBRoo (> CIDOC-CRM)
n Pierazzo (2015), Digital Scholarly Editing
+
Data models for digital editing
n
Pierazzo (2015)
n Interpretative process
n Multiple dimensions
n A single occurrence of
‘intertextuality’ in the book, about the
documents’ “literary dimension: style, rhetorical features, genre, intertextuality, citations and allusions.”
+
Data models for digital editing
n
Pierazzo (2015)
n Interpretative process
n Multiple dimensions
+
Data models for digital editing
n
Pierazzo (2015)
n Interpretative process
n Multiple dimensions
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
n
Theoretical framework
n
Data models
n The FRBR data model (1997 [2009])
n FRBRoo (> CIDOC-CRM)
n Pierazzo (2015), Digital Scholarly Editing
n Hedges et al. (2016, in press) – S(haring) A(ncient) W(isdom)S project
+
Data models for digital editing
n
Hedges et al. (2016, in press) – SAWS
n They worked with an extension of FRBRoo
+
Data models for digital editing
n
Hedges et al. (2016, in press) – SAWS
n They worked with an extension of FRBRoo
78
All the ‘intertextual’
relationships are defined at the level of E33 ‘Linguistic Object’
+
Data models for digital editing
n
‘Digital approaches to intertextuality’ is a hot topic
n
Many tools (and a huge body of literature) for automatic
detection of INTERTEXTS and TEXT REUSE (TAL)
n
Theoretical framework
n
Data models
n The FRBR data model (1997 [2009])
n FRBRoo (> CIDOC-CRM)
n Pierazzo (2015), Digital Scholarly Editing
n Hedges et al. (2016, in press)
n [L(inking) A(ncient) W(orld) D(ata)
http://lawd.info] 79 WrittenWork ConceptualWork embodies Citation representedBy Edition has subclass Translation has subclass representedBy represents represents Siglum has subclass CollationItem witness Reference has subclass EditorialComment has subclass
+
Data models for digital editing
n
To sum up
n The concept work as an abstract/unifying element represented
by witnesses/expressions
+
Data models for digital editing
n
To sum up
n The concept work as an abstract/unifying element represented
by witnesses/expressions
n ‘Part-whole’ relationships
n Work-level: ‘Complex’ works made of ‘simpler’ works
n Witness-level: ‘Complex’ witnesses made of smaller witnesses
+
Data models for digital editing
n
To sum up
n The concept work as an abstract/unifying element represented
by witnesses/expressions
n ‘Part-whole’ relationships
n Work-level: ‘Complex’ works made of ‘simpler’ works
n Witness-level: ‘Complex’ witnesses made of smaller witnesses
n Other relationships
n Between different works (‘sequel’, ‘imitation’, etc.)
n Between different witnesses (‘verbatim copy of’, ‘translation’,
etc.)
+
Thot Data Model (TDM 2.0)
+
Thot Data Model (2.0)
n
Thomas Tanselle (1989),
A Ra%onale of Textual Cri%cism
n Texts of documents, namely the texts one can derive from physical documents n Texts of works, “namely the ideal texts that the author had intended to write but which have never been realized in prac@ce” (see Pierazzo 2015) 84
+
Thot Data Model (2.0)
n
Thomas Tanselle (1989),
A Ra%onale of Textual Cri%cism
n Texts of documents, namely the texts one can derive from physical documents n Texts of works, “namely the ideal texts that the author had intended to write but which have never been realized in prac@ce” (see Pierazzo 2015) 85 Witness
+
Thot Data Model (2.0)
n
Thomas Tanselle (1989),
A Ra%onale of Textual Cri%cism
n Texts of documents, namely the texts one can derive from physical documents n Texts of works, “namely the ideal texts that the author had intended to write but which have never been realized in prac@ce” (see Pierazzo 2015) 86 Witness Expression Content
+
Thot Data Model (2.0)
n
Thomas Tanselle (1989),
A Ra%onale of Textual Cri%cism
n Texts of documents, namely the texts one can derive from physical documents n Texts of works, “namely the ideal texts that the author had intended to write but which have never been realized in prac@ce” (see Pierazzo 2015) 87 Witness Expression
Content = Tanselle’s ‘Text of the document’ = Hjelmslev’ basic distinction
+
Thot Data Model (2.0)
88
n The Domain and Range of intertextual relationships become much
clearer when this distinction is made (cf. Büchler’s opposition between ‘syntactic and semantic text reuses’)
+
Thot Data Model (2.0)
89
n The Domain and Range of intertextual relationships become much
clearer when this distinction is made (cf. Büchler’s opposition between ‘syntactic and semantic text reuses’)
n An analysis of the relationships suggested in the literature suggests
that they can be organized according to three types for any element of the model
Element
Whole/part
Paradigmatic
+
Thot Data Model (2.0)
90
+
Thot Data Model (2.0)
91
n The Work
n The Witness
n Expression
+
Thot Data Model (2.0)
92
+
Thot Data Model (2.0)
93
+
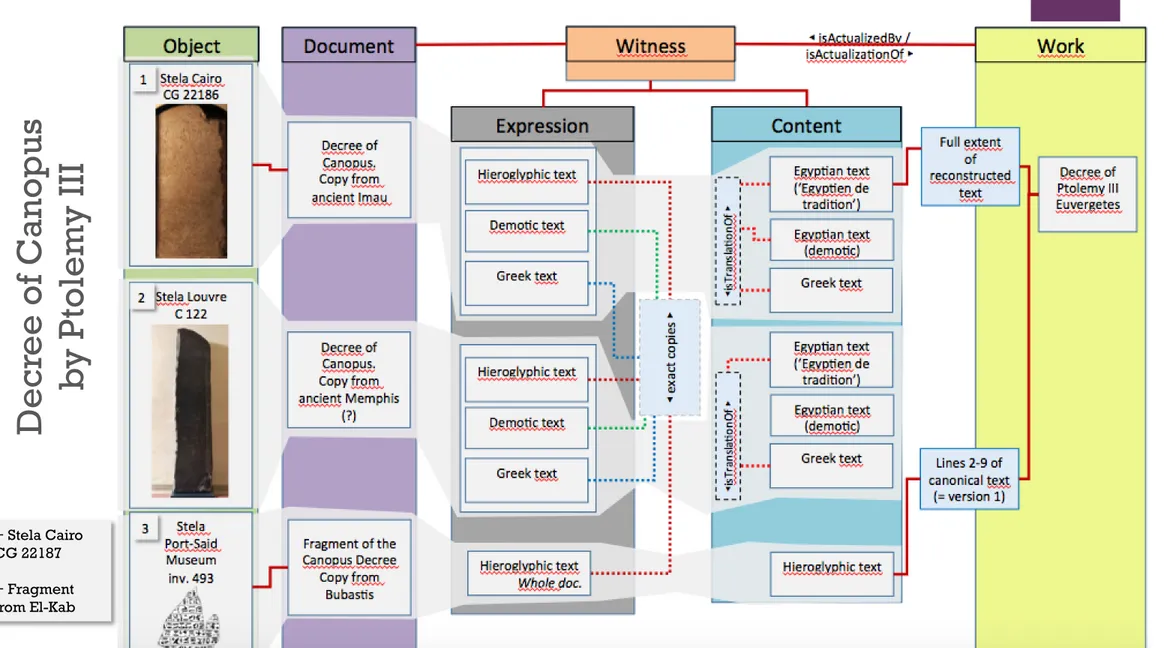
Thot Data Model (2.0)
94
Illustration 1. Multilingual decree
+ Stela Cairo CG 22187 + Fragment from El-Kab
De
cr
ee
o
f C
an
opus
b
y
Pt
ole
m
y III
+
Thot Data Model (2.0)
95
Illustration 2. Distant text reuse
P. Ramesseum IX
Roccati (2011: 141)
This papyrus is several centuries ‘older’ than P. CGT 54051. It bears a short hymnal sequence that also occurs in P. Mag. Isis
+
Thot Data Model (2.0)
96