A Document Browsing Tool Based on Book Indexes
Texte intégral
Figure


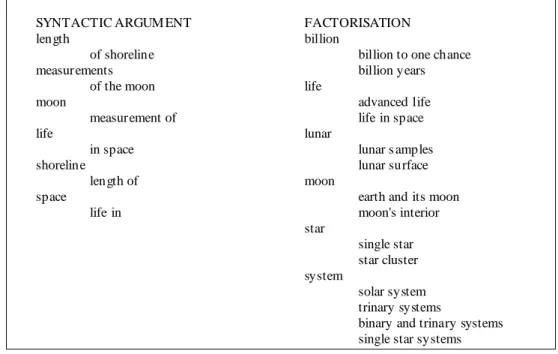

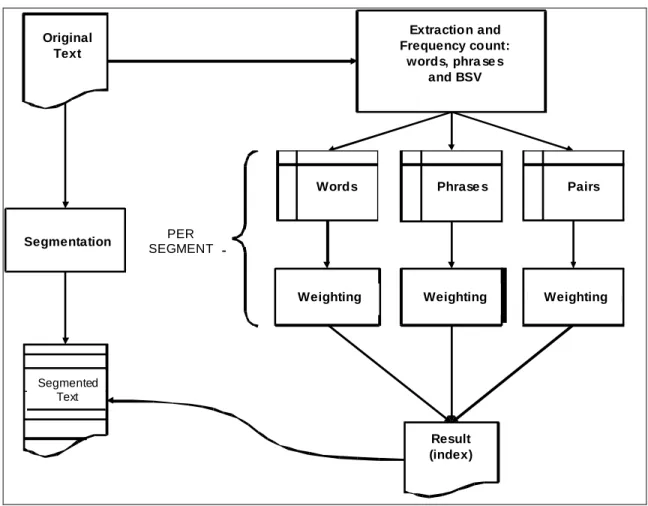
Documents relatifs
The main goal of this paper is to study the structure of the graded algebra associated to a valuation.. We show that this twisted multiplication can be chosen to be the usual one in
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
These small twist and tilt components bring the plane stacks on either side of the boundary into disregistrary and where this disregis- trary is small it can be
Liaison emerges naturally in the case of an almost complete intersection ideal and specialisation of liaison is then used to generalise aspects of work of Huneke,
Thus, according to Reinhart (1995, 2006), in order to mark focus on an phrase that cannot be marked by the projection from the object (i.e., a phrase not on the original focus
After submitting five runs on the bilingual English to Spanish subtrack from WebCLEF, we observed that it is possible to reduce terms in the documents that conform the corpus of
However, the B + tree within the palm-tree index posseses more specific properties than a general DAG (i.e., balanced height, and multiple ordered keys within nodes) that requires
Thus, by modelling the root node or each of the blank node as an object, which contains three primitive value lists, storing subnode URIs, literal values, and blank
