Incremental Learning for Bootstrapping Object Classifier Models
Texte intégral
Figure
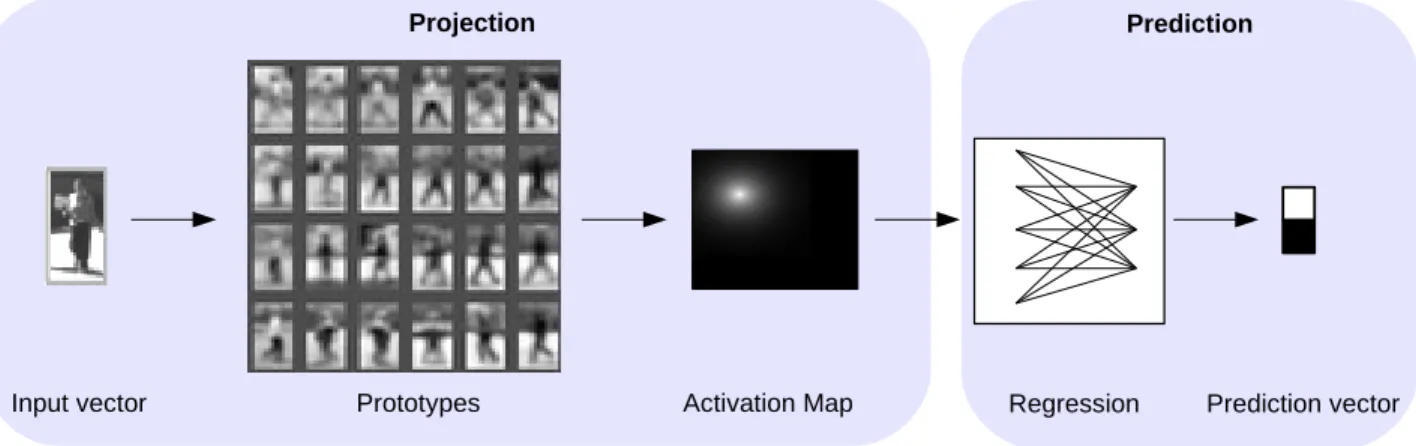

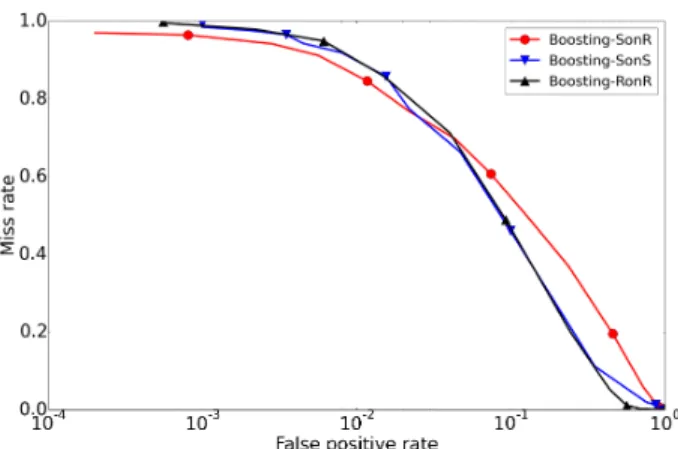
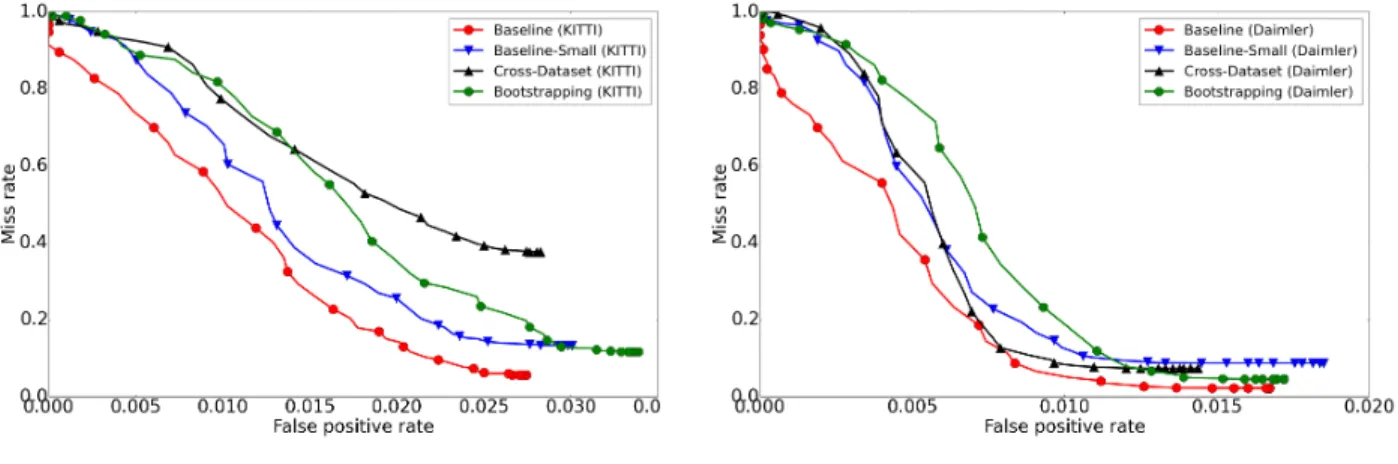
Documents relatifs
Our contribution is twofold: we propose an adaptive SLAM method that reduces the number of processed frames with minimum impact error, and we make available a synthetic flexible
Our contribution is twofold: we propose an adaptive SLAM method that reduces the number of processed frame with minimum impact error, and we make available a synthetic flexible
Results show that a learning-based sound source lo- calization method trained on this dataset yields better localization results than when trained on anechoic HRTF measurements,
(ii) the annotation of the relations of support and attack among the arguments; (iii) starting from the basic annotation of the arguments, the annotation of each argument with
Specifically, FairGRecs can create, via a fully parametrized API, synthetic patients profiles, containing the same characteristics that exist in a real medical database, including
To the best of our knowledge, this is the first publicly available dataset to in- clude continuous glucose monitoring, insulin, physiological sensor, and self-reported life-event
Therefore, the effect of physical similarity observed in both experiments sug- gests that the gist representation resulting from the anal- ysis of a low spatial resolution
We propose different methods based on Cross-Modality deep learning of CNNs: (1) a correlated model where a unique CNN is trained with Intensity, Depth and Flow images for each
