HAL Id: hal-01604610
https://hal.archives-ouvertes.fr/hal-01604610
Submitted on 7 Jun 2020
HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Comparaison de méthodes de sélection de variables
explicatives en régression PLS Application aux données
de procédés de fabrication industrielle
Jean-Pierre Gauchi, Pierre Chagnon
To cite this version:
Jean-Pierre Gauchi, Pierre Chagnon. Comparaison de méthodes de sélection de variables explica-tives en régression PLS Application aux données de procédés de fabrication industrielle. [Rapport Technique] 1999-2, auto-saisine. 1999. �hal-01604610�
Institut National de la Recherche Agronomique
Centre de Recherche de Jouy-en-Josas
Unité de Mathématiques et Informatique Appliquées
Comparaison de méthodes
de sélection de variables explicatives en régression PLS
Application aux données
de procédés de fabrication industrielle
J.P. Gauchi / INRA Jouy-en-Josas / Unité de Biométrie
&
P. Chagnon / Rhodia Recherches / Aubervilliers
Rapport technique n°1999-2
Comparaison de méthodes
de sélection de variables explicatives en régression PLS
Application aux données de procédés de fabrication industrielle
J.P. Gauchi / INRA Jouy-en-Josas / Unité de Biométrie P. Chagnon / Rhodia Recherches / Aubervilliers
Résumé
Les procédés industriels de fabrication chimique, pétrolière, agro-alimentaire sont décrits par un grand nombre de variables. Quand le fabricant ou le chercheur ont pour objectif de piloter et d’optimiser de tels procédés ils souhaitent des modèles des variables expliquées (les réponses) à la fois très explicatifs et de bonne qualité prévisionnelle, construits sur des nombres réduits de variables explicatives pertinentes. Pour atteindre cet objectif il est donc nécessaire de disposer de méthodes performantes de sélection de variables explicatives. On compare ici plusieurs méthodes de sélection de variables, dans les mêmes conditions, sur plusieurs jeux de données issus de procédés de fabrication chimique réels. Leurs efficacités, évaluées avec plusieurs critères, sont comparées à partir du modèle PLS final obtenu pour chaque jeu de données. En conclusion de l’étude nous préconisons une méthodologie de sélection de variables pas à pas, basée sur le maximum de la courbe d’évolution du en fonction du nombre de variables éliminées.
2 cum
Q
Sommaire
1. Introduction………..……….. 4
2. Pertinence de la question posée……….…….. 5
3. Description des jeux de données……….…….……….. 7
3.1 Description du jeux de données ADPN……….. 7
3.2 Description du jeux de données LATEX……….……….. 8
3.3 Description du jeux de données OXY……….. 8
3.4 Description du jeux de données SPIRA……….. 9
3.5 Description du jeux de données GRANU……….. 9
4. Caractéristiques descriptives des modèles PLS……….. 10
5. Description des méthodes de sélection de variables utilisées………... 12
5.1 Méthodes FMR, BMR, SMR ………..…….. 12
5.2 Méthode SR………..……….. 13
5.3 Méthode VARC1 et VARC2……….. 13
5.4 Méthode COR……….……….. 14 5.5 Méthode BCOR………..……….. 14 5.6 Méthode RCOR………..……….. 15 5.7 Méthode COEF……….……….…….. 15 5.8 Méthode RCOEF………..……….…….. 16 5.9 Méthode BQ et SR-BQ………..……….…….. 16
5.10 Méthode BSDEP et SR-BSDEP……….. 17
5.11 Méthode CINT……….. 17
5.12 Méthode JACK……….. 17
5.13 Méthodes GA et SR-GA……….. 18
7. Etude du jeu de données LATEX……….. 29
8. Etude du jeu de données OXY………..……….. 38
9. Etude du jeu de données SPIRA………..……….. 47
10. Etude du jeu de données GRANU……….……….…….. 56
11. Synthèse sur les critères……….….……….. 64
12. Comparaison des méthodes GA, SMR, BQ, BSDEP……….……….…….. 65
13. Proposition d’une méthodologie de sélection de variables………..……….. 68
14. Conclusion……….. 69
1. Introduction
On sait que l'on peut construire un modèle de régression PLS quand les nombres des variables explicatives (tableau X) et/ou à expliquer (tableau Y) sont très grands, même s'ils sont supérieurs au nombre d'observations disponibles. Dans les procédés de fabrication chimique, pétrolière, agro-alimentaire, très souvent décrits par un grand nombre de variables explicatives potentielles, le chercheur et le fabricant souhaitent un modèle final à nombre raisonnable de variables pour utiliser facilement le modèle dans une phase ultérieure. Celle-ci peut consister par exemple à faire du contrôle de procédé et de l'optimisation : le modèle de régression PLS doit alors être à la fois explicatif, interprétable et de bonne qualité prévisionnelle, objectifs simultanément accessibles à la régression PLS.
La difficulté réside alors dans le choix d’un sous-ensemble des variables de départ, de taille raisonnable et constitué de variables pertinentes. L’évaluation de tous les modèles possibles, soit 2p-1 modèles, si p est le nombre total de variables, n’étant pas possible dès que p approche la centaine, il faut disposer de techniques de sélection de variables.
Cette question de sélection de variables connaît de nombreuses solutions en régression usuelle (aux moindres carrés), depuis le célèbre algorithme déterministe « leaps and bounds » de Furnival & Wilson [1974] jusqu’aux méthodes stochastiques modernes telles celles basées sur l’emploi de chaînes de Markov en simulation de Monte Carlo ou encore du type de celle proposée par Stark & Fitzgerald [1997]. Toutefois, en régression PLS, il n'existe pas encore de méthode suffisamment fiable pour répondre toujours correctement à cette question du choix, même si on peut déjà trouver dans la littérature quelques méthodes pas forcément dédiées aux données de procédés mais aussi aux données de chimiométrie et de relation structure-activité : Baroni & coll. [1992], Lindgren & coll. [1994, 1995], Norinder & coll., [1997], Leardi & coll. [1992], Rodgers & Hopfinger [1994], Swierenga & coll. [1998], Gouti [1999]. L’intérêt du travail présenté ici réside dans la comparaison rigoureuse de nombreuses méthodes sur des jeux de données réels à très grand nombre de variables issus de procédés de fabrication chimique. L’efficacité des méthodes comparées est établie avec plusieurs critères du modèle PLS final obtenu avec chaque méthode, notamment la capacité de prédiction sur un jeu test. Précisons que cette publication ne concerne que la régression PLS1, c'est-à-dire que le tableau Y se réduit à une seule variable expliquée y. La régression PLS1 est bien décrite dans de nombreux ouvrages et publications, voir par exemple les ouvrages remarquables de Martens & Naes [1989] pour le point de vue du chimiométricien et de Tenenhaus [1998] pour le point de vue du statisticien.
Dans ce dernier ouvrage, en plus de l’aspect théorique, on trouve également des applications très concrètes, analysées dans le détail, et en conséquence d’une grande utilité pour le praticien. Par ailleurs, les documentations des logiciels utilisés aident efficacement dans la construction du modèle PLS. Aussi, nous ne détaillerons pas ici l'aspect théorique de la régression PLS, nous renvoyons le lecteur à ces références pour une information exhaustive. Les calculs ont été réalisés avec les logiciels SAS version 6.12 (SAS Institute, Cary, USA) et SIMCA-R version 4.0 de la société UMETRI (Umea, Suède).
Le plan de cette publication est le suivant. Dans la section 2, on expose quelques arguments pour confirmer la pertinence de la question posée. Dans la section 3 on donne une information succincte sur les cinq jeux de données étudiés. En section 4 sont définis les critères qui nous permettront de décrire complètement les modèles PLS finaux obtenus. En section 5 sont exposées les différentes méthodes comparées. En sections 6, 7, 8, 9, 10 sont fournis tous les résultats commentés respectivement pour les cinq jeux de données. La section 11 fait une courte synthèse sur les critères, la section 12 fournit une comparaison des méthodes les plus intéressantes. La section 13 propose une méthodologie de mise en œuvre d’une sélection de variables, tandis que la conclusion en section 14 indique des suites possibles à ce travail. La section 15 fournit quelques références bibliographiques.
Ajoutons enfin que cet article adopte volontairement le point de vue du praticien et n’a pas de prétention théorique. Nous avons cherché à rendre sa lecture aisée en vue de fournir au chimiométricien ou à l’ingénieur sur le terrain une méthodologie immédiatement opérationnelle.
2. Pertinence de la question posée
La pertinence de cette question de sélection de variables en régression PLS se dégage naturellement à partir de l’exposé de plusieurs arguments que nous développons ci-après.
Tout d’abord, l’argument de la parcimonie d’un modèle semble évident dans le domaine des procédés industriels où l’on souhaite un modèle pour piloter le procédé de fabrication. Le modèle doit donc renfermer peu de variables explicatives mais pertinentes, et leurs coefficients de régression doivent être interprétables c’est-à-dire présenter le même signe que celui du coefficient de régression de la régression simple correspondante. Apportons un deuxième argument. Il est vrai que le réflexe d’un spécialiste de l’analyse des données sera,
exemple de faire son choix « manuellement ». Par exemple, il choisira un nombre raisonnable de variables pertinentes à partir de l’observation des graphiques usuels, notamment celui du cercle de corrélation de l’analyse en composantes principales. Deux critiques peuvent être formulées à l’encontre de cette attitude : tout d’abord ce choix « manuel » est difficilement envisageable quand les variables sont en aussi grand nombre et aussi fortement corrélées, comme le montrent les figures 3, 10, 20, 25 et 33. En outre, même si la patience permet de venir à bout de la sélection « manuelle » à partir de graphiques, rien ne nous assure que le pouvoir de prévision, notamment sur un jeu test, sera le meilleur possible.
Enfin, on peut s’interroger sur l’avantage à faire de la sélection de variables en régression PLS puisque l’on sait que cette méthode est capable justement de traiter le cas où le nombre de variables est plus grand que celui d’observations et de gérer une extrême multicolinéarité du tableau X. Le troisième argument repose sur l’observation que la prévision faite avec le modèle PLS s’améliore considérablement quand on réalise une sélection de variables. Nous terminerons cette section en nous plaçant dans une perspective scientifique plus large. Ainsi, au-delà des exemples de procédés industriels présentés ici, la mise en œuvre d’une sélection de variables en régression PLS peut s’avérer fructueuse dans les domaines en constante progression de la spectrométrie (infra-rouge proche ou moyen, …) et de la relation structure-activité en biologie. Les praticiens de la régression PLS en spectrométrie conservent traditionnellement toutes les variables, souvent plusieurs centaines ou milliers, pour établir leurs modèles et calculer leurs prédictions. Nous souhaitons également suggérer dans cette publication que même dans cette situation où le but du modèle n’est pas en général - on peut citer toutefois le travail de Fayolle [1997] - une utilisation en conduite « on-line » de procédé, une sélection de variables (qui sont des longueurs d’onde en spectrométrie) peut conduire à beaucoup améliorer la qualité prévisionnelle du modèle PLS. La question se pose de façon semblable dans les modèles de structure-activité où il est connu qu’un grand nombre de descripteurs physico-chimiques et moléculaires n’apportent en fait que du bruit et où les descripteurs vraiment pertinents sont souvent en nombre très réduit. La sélection de variables, là aussi, est donc nécessaire.
3. Description des jeux de données
Cinq jeux de données ont été étudiés. Dans les fichiers ils sont tous représentés par des tableaux de n opérations industrielles décrites par p variables explicatives et une variable réponse. On les appellera ADPN, LATEX, OXY, SPIRA et GRANU. Décrivons succinctement ces jeux de données, une description détaillée étant impossible compte tenu de l’aspect évidemment hautement confidentiel de tels procédés industriels.
3.1 Description du jeu de données ADPN
Les données du fichier ADPN sont issues de la fabrication industrielle de l’adiponitrile (ADPN), intermédiaire de la synthèse chimique du Nylon 6-6. L’étape principale de préparation de l’ADPN repose sur une réaction catalysée par le Nickel lors d’un procédé en continu dans un atelier très complexe comportant de nombreuses opérations unitaires de génie chimique. Dans le fichier ce procédé est décrit par p variables explicatives de débit, pression, température et de compositions de mélanges réactionnels évoluant dans le temps ainsi que par la variable réponse « perte en Nickel ». En effet, même si le Nickel ne peut pas être consommé chimiquement par la réaction de par son statut de catalyseur, néanmoins au fil des semaines il se manifeste une baisse sensible et régulière de sa quantité moyenne dans le circuit de l’appareillage. La conséquence indésirable en est une diminution visible du rendement en ADPN. On peut supposer qu’un entraînement mécanique est la cause de cette baisse et donc qu’un réglage approprié des niveaux de certaines variables explicatives puisse limiter la perte en Nickel tout en conservant un niveau nominal de productivité en ADPN. Afin d’atteindre le réglage optimal il est indispensable de disposer d’un modèle de bonne qualité de la perte en Nickel en fonction de quelques variables explicatives ; on cherchera un modèle réaliste à la fois parcimonieux et pertinent à pf variables explicatives avec pf << p. On a pour ce fichier : n = 71, n
L = 57 observations pour la
construction du modèle PLS, tirées aléatoirement parmi les n observations (80% de n), n
T = 14
observations restantes (20% de l’ensemble) constituant un jeu test et p = 100 variables explicatives.
3.2 Description du jeu de données LATEX
Les données du fichier LATEX sont issues de la fabrication industrielle, en opérations discontinues, de latex pour le couchage du papier par polymérisation en émulsion. Les variables explicatives sont des températures, des durées de paliers, des vitesses d’introduction de monomères, des taux de catalyseurs et des concentrations réactionnelles. La variable réponse est le taux de produits secondaires appelés de façon générique « insolubles » par l’homme de l’art. L’objectif de ce dernier est de déterminer un modèle du taux d’insolubles en fonction de variables du procédé en vue d’agir sur celles-ci pour aboutir à un latex en fin de réaction à très faible taux de ces produits secondaires. La difficulté inhérente au type de réaction mise en jeu rend impossible l’action sur un grand nombre de variables du procédé, en outre toutes fortement corrélées. Par exemple, une température de palier et la durée de ce palier ne peuvent pas être ajustées indépendamment. Pour trouver un optimum de réglage il est donc nécessaire de disposer d’un modèle le plus parcimonieux possible et s’appuyant sur les coefficients de régression les plus fiables, c’est-à-dire les moins influencés par des coefficients de variables peu explicatives. Celles-ci peuvent apportent effectivement du bruit et sont toujours en nombre important quand le nombre de variables explicatives est grand. On a pour ce fichier : n = 262, nL = 210 , nT = 52 et p = 117.
3.3 Description du jeu de données OXY
Les données du jeu OXY proviennent de la fabrication industrielle de l'oxyde de Titane, produit de très gros tonnage, qui entre dans la composition de très nombreux produits finis, par exemple une bonne partie de toutes les peintures fabriquées sur la planète. On cherche à expliquer une réponse, une caractéristique de blancheur, en fonction des variables des étapes dites d’hydrolyse, de mûrissement et de calcination. Il est particulièrement difficile de fixer correctement les niveaux des variables de ces deux dernières étapes et le besoin de disposer d’un modèle fiable de contrôle de la dérive de la caractéristique de blancheur est d’autant plus crucial que les réactions mises en jeu sont irréversibles et de très fort tonnage. On a : n = 25, n
3.4 Description du jeu de données SPIRA
Les données du jeu SPIRA proviennent de la fabrication par fermentation (biotechnologie) de l'antibiotique Spiramycine. Les observations sont des opérations de fermentation conduites dans plusieurs fermenteurs (procédé "batch") décrites par des variables du procédé, c'est-à-dire des puissances d'agitation, des températures de palier, des pics de consommation de l’oxygène consommé par les bactéries et les temps auxquels se manifestent ces pics, .... informations enregistrées sur 240 heures à intervalles réguliers. Une analyse de données antérieure ayant montré des corrélations importantes entre le profil de la courbe de l’oxygène consommé et le titre final en Spiramycine dans le "moût" de fabrication, il a été entrepris la mise au point d’un modèle de régression PLS pour relier cette réponse de titre à un sous-ensemble de ces variables explicatives. La fermentation est de longue durée et l’existence d’un modèle fiable peut permettre de stopper cette réaction précocement si le titre prévu par le modèle dès les premières 50 heures est trop faible par rapport au standard de production. En effet, on sait qu’un titre trop faible conduira à une extraction trop difficile de la Spiramycine : en conséquence le moût est inutilisable et il est alors préférable d’enchaîner une autre opération de fermentation. Ce type de conduite de procédé se rapproche de celui proposé par Nomikos & MacGrégor [1995]. On a : n = 145, nL = 115, nT = 29 et p = 96.
3.5 Description du jeu de données GRANU
Les données du jeu GRANU proviennent de la fabrication d'émulsions antimousse pour l'industrie du papier. Les opérations sont décrites par des variables explicatives usuelles telles des teneurs en monomères, des températures, ainsi que des courbes granulométriques mesurées en cours de la fabrication. La réponse à modéliser ici est la viscosité de la formulation finale. Cette viscosité dépend en effet, de manière très complexe, de températures du procédé et de tranches-clés des courbes granulométriques. Si on établit un modèle de régression PLS performant avec quelques-unes de ces variables explicatives, on pourra alors dans un deuxième temps agir sur d’autres variables (déjà connues par l’homme de l’art) qui gouvernent les variables explicatives du modèle PLS. On a : n = 29, nL = 23, nT = 6 et p = 78.
Les critères suivants des modèles de régression PLS ont été choisis pour comparer les méthodes de cette étude. Ce sont :
- pf : le nombre de variables explicatives du modèle PLS final ; selon le principe de parcimonie un pf faible sera préférable pour le modèle PLS final,
- h : le nombre de composantes PLS obtenues par la validation croisée du logiciel SIMCA,
- Qcum : critère de qualité de prédiction ; il doit être le plus proche possible de 1 ;
2
en régression PLS1 il est défini par :
Q PRESS RSS cum j j j h 2 1 1 1 = − − =
∏
avec :• PRESSj le PRESS associé au modèle PLS à j composantes, on a :
(
)
21 ˆ( )
∑
= − −= nL
i yi y i
PRESS , où est la prédiction de yi alors que yi est absente lors de la construction du modèle,
) (
ˆ i y−
• RSSj-1 le RSS associé au modèle PLS à j-1 composantes, on a : , où est la prédiction de yi alors que yi est présente lors de la construction du modèle,
(
)
2 1 ˆ∑
= − = nL i yi yi RSS yˆi-RXh2 : taux d'explication du tableau X (en %) avec un modèle à h composantes PLS ; on a pour un tableau X centré-réduit à p colonnes :
100 ) 1 ( 1 2 2 2 × − =
∑
= p n p t RX L h i i ih , où les ti sont les composantes PLS et les pi les
- : taux d'explication ajusté du tableau Y (en %), ici réduit à un vecteur y, avec h composantes PLS, on a : 2 ,adj h RY 2 ,adj h RY 100 1 1 ) 1 ( 1 2 ⎥× ⎦ ⎤ ⎢ ⎣ ⎡ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − − − = h n n RY L L h , où
∑
∑
= = − − = L L n i i n i h i i h y y y y RY 1 2 1 2 ] [ 2 ) ( ) ˆ (avec la reconstitution de l’observation yi avec un modèle de régression PLS à h composantes, et ] [ ˆ h i y
y la moyenne des nL observations yi ,
- Cmax : rapport du plus grand coefficient centré-réduit de régression PLS (en valeur absolue) au plus faible (en valeur absolue), soit :
min PLS max PLS max C β β ˆ ˆ =
- RDMODX : rapport du plus grand DMODX au plus faible, où DMODX est une distance normalisée d’une observation au modèle, dans l’espace des variables explicatives ; elle est définie rigoureusement dans la documentation du logiciel SIMCA et dans Tenenhaus [1998] page 89,
- NDMODX : nombre de DMODX supérieur au seuil du logiciel SIMCA,
- RDMODY : rapport du plus grand DMODY au plus faible, où DMODY est une distance analogue au DMODX mais par rapport aux observations yi ,
- LSE : écart-type résiduel, défini par :
(
)
LSE y y n i i i n L L =∑
= − $ 2 1- RTo p2, : coefficient de corrélation au carré, de la droite de régression du nuage [observé , prédit] des données de test,
(
)
SDEP y y n i i i n T T =∑
= − $(−) 2 15. Description des méthodes de sélection de variables utilisées
Les méthodes que nous utilisons ici, bien connues pour la plupart, sont très différentes. L’originalité de notre travail réside dans le couplage de certaines d’entre elles d’une part et leur comparaison rigoureuse d’autre part. En effet, ces méthodes de sélection peuvent agir directement sur l'ensemble des p variables explicatives de départ ou bien sur une présélection pertinente S de s variables explicatives. La constitution de ce sous-ensemble pertinent S peut se faire par des régressions simples, le nom de la méthode commencera alors par SR. On peut aussi imaginer que la constitution du sous-ensemble S trouve son origine dans un choix particulier des variables explicatives par un expert du domaine. Celui-ci peut vouloir en effet imposer certaines variables explicatives, au moins lors de cette présélection, à partir de considérations de bilans matière, énergétique, de traçabilité, ....
5.1 Méthodes FMR, BMR, SMR
Les acronymes FMR, BMR et SMR signifient respectivement "Forward Multiple Regression", "Backward Multiple Regression" et "Stepwise Multiple Regression". Ce sont des méthodes bien connues. La méthode FMR est la méthode usuelle de sélection de variables de la régression multiple aux moindres carrés ordinaires, avec introduction une à une des variables dans le modèle, selon un seuil d'entrée choisi (c’est par exemple l’option Forward de la procédure REG du logiciel SAS/STAT). La méthode BMR élimine une à une des variables du modèle, selon un seuil de sortie choisi (c’est par exemple l’option Backward de la procédure REG du logiciel SAS/STAT). La méthode SMR permet l'introduction et l'élimination une à une des variables du modèle, selon des seuils d'entrée et de sortie choisis (c’est par exemple l’option Stepwise de la procédure REG du logiciel SAS/STAT). Chacune de ces méthodes conduit à un sous-ensemble de pf variables explicatives sélectionnées parmi les p ; pf n’est évidemment pas forcément identique pour chacune des méthodes. Dans un deuxième temps, on construit un modèle PLS sur ces pf variables explicatives.
5.2 Méthode SR
Les lettres SR signifient "simple regression". Dans cette méthode, déjà proposée dans le cadre de la formulation en Chimie [Gauchi, 1995], on réalise d'abord p régressions simples de la réponse y en fonction de chacune des variables explicatives. Parmi les p régressions simples on conserve les pf variables pour lesquelles la probabilité du test de Student associé au coefficient de la pente est inférieure à un seuil donné. Traditionnellement le seuil choisi est 0.05, on baissera ce seuil à 0.01 ou 0.001 si trop de variables sont sélectionnées, typiquement si pf > 0.75p ; inversement, on l'augmentera à 0.10 puis 0.20 si nécessaire c’est-à-dire si le nombre de variables sélectionnées est vraiment trop faible, typiquement si pf < 0.10p. Avec cette façon de faire on peut supposer que :
- les pf variables sélectionnées, même si elles sont très corrélées entre elles, influencent
significativement la réponse y,
- on a diminué le niveau de bruit du tableau X.
Enfin, le modèle PLS final sera construit sur ces seules pf variables explicatives.
5.3 Méthodes VARC1 et VARC2
Il est connu en Analyse des Données que l'on peut résumer l'information portée par un grand nombre de variables par un faible nombre de variables en réalisant une typologie de l'ensemble des variables avec une méthode de classification de variables [Harman, 1976]. On réalise ici cette typologie sur les p variables avec la procédure VARCLUS du logiciel SAS/STAT, selon deux options : "proportion = 0.7 à 0.9" (méthode VARC1) et "maxeigen=1" (méthode VARC2). Nous renvoyons le lecteur à la documentation de la procédure VARCLUS pour des détails sur ces options. Avec ces méthodes VARC1 et VARC2, on réduit ainsi le nombre p à un sous-ensemble de pf variables résumant au mieux la typologie des p variables. Chacune de ces pf variables représentant « au mieux » le cluster de variables dont elle fait partie, on construit le modèle PLS sur ces pf variables. On utilisera aussi ces méthodes sur le sous-ensemble présélectionné par la méthode SR. Ce seront les méthodes SR-VARC1 et SR-VARC2. On pourra objecter à ces méthodes que beaucoup de variables parmi les pf expliqueront faiblement la réponse puisque le but de ces pf variables est avant tout de balayer l'espace des variables sans se préoccuper de leur corrélation avec la réponse. En effet, ceci semble un but contraire à celui poursuivi ici qui est de constituer un sous-ensemble dont la priorité est d'abord d'expliquer et de prédire au mieux la réponse. Nous proposons cependant ces méthodes dans notre étude pour
aider à qualifier les autres méthodes, en quelque sorte pour les borner inférieurement : d'une certaine façon, les autres méthodes devront se montrer meilleures que ces méthodes VARC1, VARC2, SR-VARC1 et SR-VARC2.
La méthode GOLPE [Baroni & al, 1992] conduit également à explorer l’espace des variables explicatives pour sélectionner uniquement celles qui le décrivent optimalement (au sens de l’enveloppe convexe constituée des extrémités des vecteurs de ces variables sélectionnées). A notre sens, cette méthode n’est pas adaptée à l’objectif que l’on s’est fixé ici puisque cette exploration n’est pas orientée dans l’explication conjointe de la réponse.
5.4 Méthode COR
Elle est basée sur les étapes suivantes :
a) on calcule d'abord le modèle PLS sur les p variables de départ, avec h composantes PLS significatives par validation croisée,
b) on examine ensuite les tests de significativité des coefficients de corrélation de chaque variable explicative avec chacune des h composantes PLS significatives, soit q = p×h coefficients de corrélation ; on élimine d'un coup toutes les variables dont tous les q coefficients de corrélation ne sont pas significativement différents de zéro ; si aucune des variables explicatives ne satisfait cette dernière condition on abandonne la méthode et on s’oriente vers la méthode suivante BCOR,
c) on calcul un modèle PLS final avec les variables restantes.
Le test utilisé pour tester si le coefficient de corrélation linéaire ρ est nul est le test classique de Fisher [Saporta, 1990].
5.5 Méthode BCOR
Elle est basée sur les étapes suivantes (BCOR comme « Backward Correlations ») :
a) on calcule d'abord le modèle PLS sur les p variables de départ, avec h composantes PLS significatives par validation croisée,
b) on examine ensuite, comme dans la méthode COR, les tests de significativité des coefficients de corrélation de chaque variable explicative avec chacune des h
composantes PLS significatives, soit q = p×h coefficients de corrélation ; on élimine la variable qui présente le plus petit coefficient de corrélation (en valeur absolue) parmi les variables dont tous les q coefficients de corrélation ne sont pas significativement
différents de zéro ; si aucune des variables explicatives ne satisfait cette dernière condition, on élimine la variable qui présente le plus petit coefficient de corrélation (en valeur absolue) parmi les variables qui présentent le plus de coefficients de corrélation non significativement différents de zéro,
c) on calcul un modèle PLS avec les p-1 variables restantes et on itère en reprenant en b). On aboutit à un modèle PLS à pf variables explicatives.
5.6 Méthode RCOR
Elle est basée sur les étapes suivantes (RCOR comme « Random Correlations ») :
a) on calcule d'abord un premier modèle PLS sur les p variables de départ, avec h composantes PLS significatives par validation croisée,
b) on bruite chaque variable du tableau X avec un bruit gaussien de variance proportionnelle à la contribution de la variable en question dans les composantes PLS non sélectionnées par validation croisée,
c) on calcule un second modèle PLS sur les p variables bruitées ; on repère ainsi :
- les c1 coefficients de corrélation non significativement différents de zéro, dans le second modèle,
- les c2 coefficients de corrélation qui ont changé de signe entre les deux modèles, - les c3 coefficients de corrélation, de même signe, mais dont la valeur absolue a
changé significativement (test au moyen de la transformation Z de Fisher, Saporta [1990]).
d) on calcule un modèle PLS final sur les pf = p - c1 - c2 - c3 variables.
5.7 Méthode COEF
Elle est basée sur les étapes suivantes :
a) on calcule d'abord un premier modèle PLS sur les p variables de départ, avec h composantes PLS significatives par validation croisée,
b) on calcule tous les rapports
j max j C β β ˆ ˆ = , j = 1,…, p,
c) on élimine en un coup toute variable Xj pour laquelle le rapport Cj dépasse la valeur
de variables ne diminue pas sensiblement. On nomme alors la méthode COEF5. C’est une méthode évidemment très empirique, mais qui a pu se montrer utile dans certains cas.
5.8 Méthode RCOEF
Elle est basée sur les étapes suivantes (RCOEF comme « Random Coefficients ») :
a) on calcule d'abord un premier modèle PLS sur les p variables de départ, avec h composantes PLS significatives par validation croisée,
b) on bruite chaque variable du tableau X comme dans la méthode RCOR,
c) on calcule un second modèle PLS sur les p variables bruitées ; on repère les c coefficients de régression PLS (centrés-réduits) qui ont changé de signe,
d) on calcule un modèle PLS final sur les p - c variables restantes.
5.9 Méthodes BQ et SR-BQ
Elles sont basées sur les étapes suivantes (BQ comme « Backward » et SR-BQ comme « Simple Regressions- Backward ») :
2 cum Q 2 cum Q
a) on calcule d'abord un premier modèle PLS sur les p variables de départ (ou s variables présélectionnées pour la méthode SR-BQ), avec h composantes PLS significatives par validation croisée ainsi que le Qcum2 ,
b) on supprime la variable explicative présentant le plus petit (en valeur absolue) des coefficients de régression PLS puis on recalcule un nouveau modèle sur les p-1 variables et le Qcumcorrespondant,
2
c) on réitère la démarche de suppression en stockant à chaque fois l’identifiant de la variable supprimée ainsi que la valeur du . Finalement, on trace le graphe du en fonction du nombre de variables et on choisit le nombre de variables correspondant à un des maximum de ce graphe associé au nombre de variables le plus faible ; souvent, il n’existe qu’un maximum.
Qcum2 Qcum2
Une variante possible pour sélectionner la variable à supprimer à chaque étape serait, au lieu de se baser sur le coefficient de régression, d’éliminer la variable contribuant le plus faiblement au du modèle PLS courant. La méthode se nommerait alors BQQ ; nous n’avons pas évalué cette méthode. Nous privilégions toutefois la méthode BQ à la méthode BQQ pour la raison
2 cum
suivante. Le coefficient de régression étant directement lié à la corrélation entre la variable explicative concernée et la réponse, supprimer une variable associée à un faible coefficient de régression revient donc en quelque sorte à supprimer une variable expliquant faiblement la réponse. On peut dire que la méthode BQ est une sélection de variables avec pour objectifs simultanés de bien expliquer la réponse (choix des variables basé sur les valeurs des coefficients de régression) et de conduire à un modèle à bonne capacité de prévision (choix du critère du
), ce qui sont bien les qualités attendues des modèles de pilotage des procédés industriels.
2 cum
Q
5.10 Méthodes BSDEP et SR-BSDEP
C'est le même type de méthode que le précédent mais le critère de choix est maintenant le SDEP.
5.11 Méthode de sélection CINT
Le sigle CINT signifie "confidence interval". La méthode revient à sélectionner en une seule fois les coefficients dont les intervalles de confiance à un niveau donné (on choisira ici 95%) ne contiennent pas zéro. Pour cette méthode, l'intervalle de confiance est construit en utilisant la formule de la variance de l'estimateur PLS, donnée dans Tenenhaus [1998] et que nous rappelons ci-dessous :
( )
(
)
var $βPLS ≈s S S X XSh h' ' h Sh' − 2 1 avec :- Sh = [ u , X'Xu , X'XX'Xu , ... , (X'X)h-1u] où u = X'y
- s2 estimation de la variance expérimentale donnée par la variance résiduelle de la
régression de y sur les h composantes PLS.
Les bornes d’un intervalle de confiance approximatif au risque de 5% pour βPLSseront définies
par : βˆPLS ±1.96 var(βˆPLS).
5.12 Méthode JACK
Le principe de cette méthode est basé sur des intervalles de confiance construits avec des estimations d’écart-types des βˆPLS par la méthode bien connue de rééchantillonnage Jacknife.
On trouve par exemple dans Efron et Tibshirani [1994] la formule de l'estimation Jacknife de l'écart-type d'un paramètre T$ (erreur-standard), formule que nous rappelons ci-dessous :
(
)
s n n T T Jack i i n = ⎡ − − ⎣⎢ ⎤ ⎦⎥ − =∑
1 2 1 1 2 $( ) $(.) /où est la moyenne des n valeurs de et la moyenne des n-1 valeurs de , la valeur ayant été ôtée. Les bornes d’un intervalle de confiance approximatif au risque de 5% pour
$(.)
T T$ T$(−i) T$
$ Ti
PLS
β seront définies par : où est l’estimateur Jacknife de l’écart-type de . ] [ ˆ 96 . 1 ˆ Jack PLS sβPLS β ± [ ] ˆ Jack PLS sβ PLS βˆ
Dans la méthode JACK on supprime en un coup les variables dont les coefficients de régression PLS ont des intervalles de confiance Jacknife (à 95%) qui contiennent zéro. On a considéré un instant la possibilité d’opérer pas à pas en supprimant à chaque fois, parmi les coefficients dont les intervalles de confiance Jacknife contiennent zéro, le plus petit en valeur absolue. Les résultats décevants obtenus (trop grandes valeurs de pf) ne nous ont pas encouragé à poursuivre dans cette voie .
5.13 Méthodes GA et SR-GA
Les lettres GA signifient « Genetic Algorithms ». Ces méthodes sont basées sur l’usage des algorithmes génétiques orientés dans la sélection de variables. C'est Holland [1970] qui, le premier, propose ce type d'algorithmes stochastiques pour optimiser diverses fonctions. Rodgers & Hopfinger [1994] d'une part, Leardi & coll. [1992] d'autre part, utilisent les GA pour faire de la sélection de variables en régression usuelle et également en régression PLS. On trouve aussi dans Swierenga & coll [1998] de la sélection de variables en régression PLS au moyen de l’algorithme de recuit simulé (« annealing algorithm ») fournissant des résultats proches de ceux obtenus avec les GA. On trouvera dans Chaterjee [1996] une bonne introduction aux GA dans une perspective statistique. Les problèmes traités par exemple par Rodgers ou Leardi ont beaucoup moins de 100 variables. Dans notre situation à 100 variables ou plus, l'emploi des GA est peut-être très discutable ; en effet, on verra que la variabilité des solutions est très grande. Nous avons néanmoins retenu cette méthode et utilisé le programme Cerius2/QSAR version 3.7 PDC de la société MSI pour mener à bien les calculs. Les conditions choisies dans ce programme, après une optimisation préliminaire du réglage des paramètres de l'algorithme, sont les suivantes : nombre de générations égal à 100000, une taille de population de 500 modèles de régression PLS, une taille initiale de 20 variables explicatives par modèle et l'option "add new
term" de Cerius2 fixée à 50%. Plusieurs essais ont été réalisés pour chaque méthode, initiés de façon aléatoire.
6. Etude du jeu de données ADPN
Pour chaque jeu de données on réalise au préalable une étude détaillée du modèle PLS avec les p variables explicatives pour permettre une comparaison plus poussée des résultats après mise en œuvre de la méthode de sélection. La détermination de ces modèles complets a été effectuée avec le logiciel SIMCA déjà signalé dans l’introduction.
6.1 Le modèle PLS complet
Le modèle PLS complet pour le jeu ADPN, avec les 100 variables et 57 observations, s'appuie sur 3 composantes PLS significatives t1, t2, t3 (au sens de la validation croisée). Au vu de la valeur des caractéristiques apparaissant au tableau 1 ainsi qu’au travers des différents graphiques qui suivent, ce modèle est acceptable, notamment au plan de sa capacité prédictive.
Caractéristique Valeur pf 100 h 3 RX2 (%) 33 (%) RYadj2 94 Qcum 2 0.78 Cmax 828 RDMODX 4.09 NDMODX 5 RDMODY 190 LSE 0.98 LOF 0.16 RTo p2, 0.85 SDEP 2.21
On trouve en figure 1 les graphiques [ t1 , t2 ] et [ t1 , t3 ] qui montrent que presque toutes les observations sont inscrites à l'intérieur de l'ellipse de Hotelling, les quelques unes extérieures restant très proches de la frontière de l'ellipse. L'absence d'une structure disparate nous laisse espérer une comparaison fiable des différentes méthodes.
-10 -5 0 5 10 -4 -2 0 2 4 Ellipse: Hotelling T2 (0.05) t[ 2] t[1] -10 -5 0 5 10 -6 -4 -2 0 2 4 6 Ellipse: Hotelling T2 (0.05) t[ 3] t[1]
Figure 1 : Graphiques [ t1 , t2 ] et [ t1 , t3 ] du modèle complet de ADPN.
La figure 2 illustre un modèle PLS de bonne qualité globale au travers des graphiques [u1 , t1] , [u2 , t2] et [u3 , t3].
-10 -8 -6 -4 -2 0 2 4 6 8 10 -16 -12 -8 -4 0 4 8 12 u[ 1] t[1] -10 -8 -6 -4 -2 0 2 4 6 8 10 -16 -12 -8 -4 0 4 8 12 u[ 2] t[2] -10 -8 -6 -4 -2 0 2 4 6 8 10 -16 -12 -8 -4 0 4 8 12 u[ 3] t[3]
Figure 2 : Graphiques [ u1 , t1 ] , [ u2 , t2 ] , [ u3 , t3 ] du modèle complet de ADPN.
La figure 3 illustre la structure de forte corrélation du tableau X, chaque point représentant l’extrémité du vecteur d’une variable explicative. Ce type de graphique donne aussi la position du vecteur réponse Y
-0.2 -0.1 0.0 0.1 0.2 -0.3 -0.2 -0.1 0.0 0.1 0.2 Y w* c [2 ] w*c[1] -0.2 -0.1 0.0 0.1 0.2 -0.3 -0.2 -0.1 0.0 0.1 0.2 Y w* c [3 ] w*c[1]
Figure 3 : Graphiques [w*c[1] , w*c[2] ] et [w*c[1] , w*c[3] ] du modèle complet de ADPN.
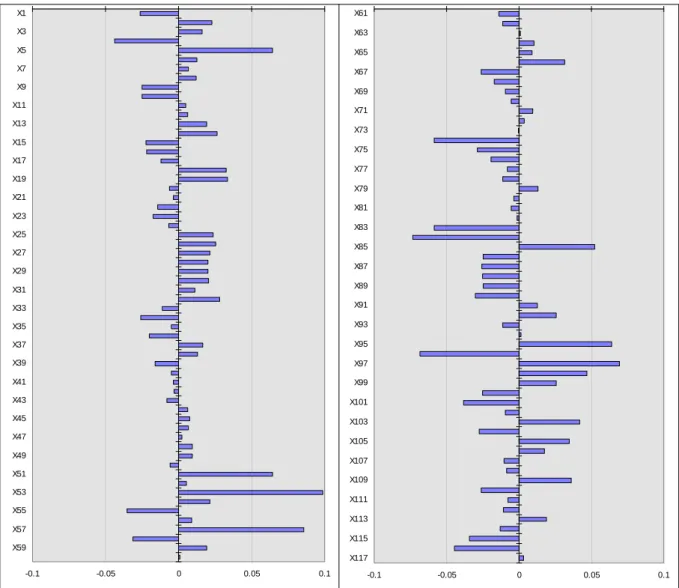
La figure 4 donne les coefficients de régression PLS centrés-réduits (pour permettre les comparaisons ultérieures des méthodes) sous forme de barres horizontales.
-0.15 -0.1 -0.05 0 0.05 0.1 x1 x4 x7 x10 x13 x16 x19 x22 x25 x28 x31 x34 x37 x40 x43 x46 x49 -0.15 -0.1 -0.05 0 0.05 0.1 x51 x54 x57 x60 x63 x66 x69 x72 x75 x78 x81 x84 x87 x90 x93 x96 x99
De façon simplifiée on dira que la figure 5 donne des indications sur la distance des observations au modèle, dans l'espace des X et dans l'espace de Y. Par exemple, sur cette figure 5 le graphique de gauche montre 4 observations dépassant le seuil au delà duquel SIMCA déclare les observations mal reconstituées par le modèle.
0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 DCrit (0.05)
Dcrit [3] = 1.218 , Normalized distances, Non weighted residuals
DM o d X [3] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 DM o d Y [3]
Figure 5 : Distances des observations au modèle complet de ADPN.
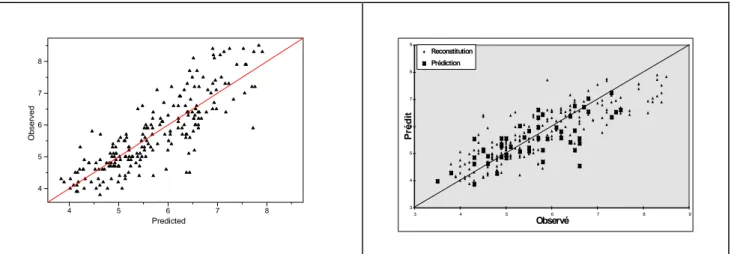
Enfin, la figure 6 donne des indications sur la capacité du modèle à reconstituer les données et surtout à prédire les données du jeu test. Sur le graphique de droite, apparaissent les 14 points du jeu test en gros carrés noirs.
85 90 95 100 105 85 90 95 100 105 Ob se rv e d Predicted 80 85 90 95 100 105 110 80 85 90 95 100 105 110 Observé Préd it Reconstitution Prédiction
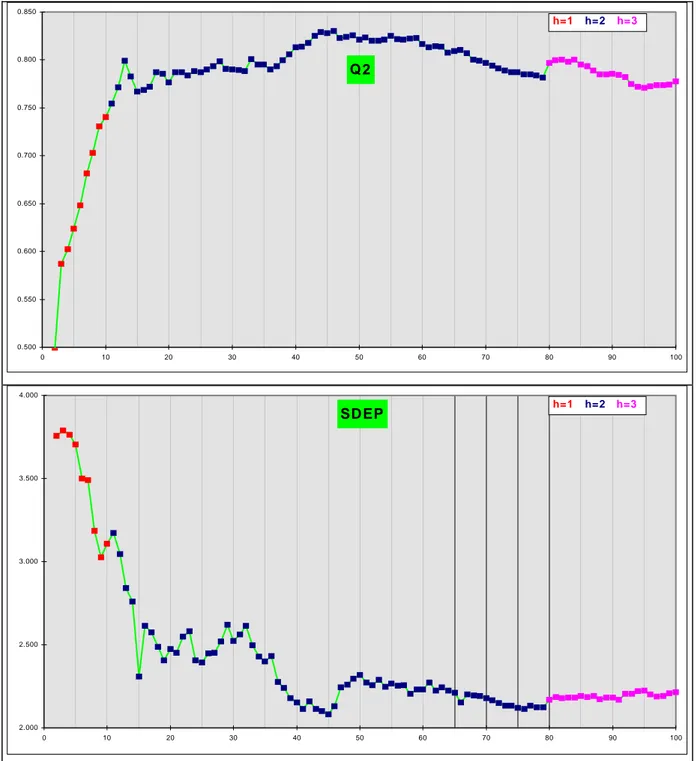
Plutôt que de donner tous les graphiques relatifs à toutes les méthodes, ce qui rendrait fastidieux la lecture de ce document, on récapitulera les résultats à l'aide du tableau 2 où apparaissent également les résultats du modèle complet déjà exposés. Au tableau 3, sont consignés les résultats des méthodes basées sur les algorithmes génétiques, les méthodes GA et SR-GA. Enfin, la figure 7 montre l’évolution des deux critères Qcum et SDEP pour les méthodes BQ et BSDEP.
2 Méthode pf h RX2 (%) RYadj2 (%) Qcum 2 Cmax R D M O D X N D M O D X R D M O D Y LSE RTo p, 2 (%) SDEP NONE 100 3 33 94 0.78 828 4.09 5 190 0.98 85 2.21 SR 45 2 44 75 0.62 148 2.85 5 442 2.09 73 2.72 SR-FMR 4 1 36 45 0.37 1.57 7.40 1 198 3.11 46 3.90 SR-BMR 23 2 50 68 0.54 654 5.67 3 196 2.38 73 2.91 SR-SMR 6 2 51 83 0.75 3.66 8.80 3 275 1.74 85 2.01 SR-BQ 32 2 43 78 0.64 128 2.54 4 635 1.94 88 2.73 SR-BSDEP 32 2 43 78 0.64 128 2.54 4 635 1.94 88 2.73 SR-VARC1 11 1 26 66 0.59 2.45 4.07 2 857 2.43 68 3.14 SR-VARC2 9 1 30 64 0.58 2.17 6.36 3 99 2.52 62 3.40 FMR 20 3 36 95 0.86 16.9 4.32 3 118 0.95 78 2.57
BMR méthode non applicable à ce jeu de données
SMR 17 3 41 93 0.85 26.1 4.27 2 397 1.07 73 2.75 BQ 13 2 46 85 0.80 1.672 4.45 3 54 1.60 71 2.84 BSDEP 15 2 44 84 0.77 1.46 3.76 3 488 1.64 80 2.31 VARC1 20 1 17 57 0.51 27.1 3.42 3 141 2.75 65 3.31 VARC2 23 1 16 55 0.47 276 2.93 3 1337 2.82 57 3.72 COR 83 3 38 92 0.78 317 4.04 6 112 1.19 80 2.49 BCOR 77 3 41 91 0.77 84 3.81 5 10849 1.24 82 2.29 RCOR 78 3 40 91 0.78 180 3.82 4 179 1.21 80 2.48 COEF5 66 3 36 95 0.84 20.9 4.78 5 47 0.94 87 2.06 RCOEF 89 3 34 94 0.79 415 4.19 4 109 0.99 84 2.32 CINT 93 3 32 95 0.78 47.9 3.65 6 1310 0.91 85 2.21 JACK 29 2 37 84 0.78 78.7 3.34 4 161 1.66 69 2.97 CV% 81 37 25 19 20 138 36 35 261 39 15 19
Tableau 2 : Caractéristiques du modèle PLS obtenu pour chaque méthode, pour ADPN.
NB : Le coefficient de variation (écart-type/moyenne)×100 (CV%) figure pour chaque critère sur les tableaux 2 et 3. Il figurera également sur les tableaux correspondants des quatre autres jeux de données.
Méthode pf h RX2 (%) RYadj2 (%) Qcum2 Cmax R D M O D X N D M O D X R D M O D Y LSE RTo p, 2 (%) SDEP GA1 30 3 33 95 0.82 1011 6.09 6 12532 0.91 93 1.51 GA2 29 3 23 91 0.75 34 4.11 3 84 1.22 86 2.04 GA3 27 3 37 96 0.90 55 3.53 2 480 0.84 89 1.80 GA4 34 3 27 92 0.81 80 2.81 2 66 1.17 87 1.84 GA5 29 3 23 91 0.75 84 3.17 2 281 1.23 82 2.18 GA6 21 3 26 92 0.81 26 3.42 5 80 1.20 80 2.51 GA7 27 3 24 91 0.78 58 3.02 1 58 1.25 83 2.11 GA8 39 3 21 94 0.81 605 4.58 5 107 1.00 83 2.50 GA9 38 3 29 95 0.79 362 3.77 3 36 0.89 88 1.83 CV% 19 0 19 2 6 134 26 53 271 15 5 16 SR-GA1 12 2 34 86 0.77 22 3.42 4 224 1.57 86 2.17 SR-GA2 20 2 33 86 0.72 174 2.71 3 28 1.53 86 2.10 SR-GA3 14 2 37 87 0.79 41 2.78 3 1263 1.48 88 1.80 SR-GA4 12 2 30 87 0.73 43 3.08 2 175 1.51 90 1.83 SR-GA5 18 2 34 87 0.71 32 2.91 3 225 1.49 71 3.05 CV% 24 0 7 0.6 5 101 10 24 130 2 9 23 Tableau 3 : Caractéristiques des modèles PLS obtenus pour 9 essais de la méthode GA et pour 5 essais de la
méthode SR-GA, pour ADPN.
NB : les méthodes GA et SR-GA sont initiées par une solution aléatoire ; en effet, on sait que le principe de ces méthodes d’optimisation stochastique est de réaliser plusieurs essais en changeant la solution aléatoire de départ. Pour la méthode GA dix essais ont été réalisés dont un a aboutit à une divergence (valeurs infinies de certains critères). Cinq ont été réalisés pour la méthode SR-GA. Ces nombres peuvent paraître faibles mais ils représentent déjà (avec l’optimisation préalable des réglages de l’algorithmes) des temps calcul considérables, soit un temps moyen d’environ 100 fois plus long que le temps moyen des autres méthodes.
Q2 0.500 0.550 0.600 0.650 0.700 0.750 0.800 0.850 0 10 20 30 40 50 60 70 80 90 100 h=1 h=2 h=3 SD EP 2.000 2.500 3.000 3.500 4.000 0 10 20 30 40 50 60 70 80 90 100 h=1 h=2 h=3
Figure 7 : Graphiques d'évolution des critères Qcum et SDEP(méthodes BQ et BSDEP)pour ADPN. 2
6.3 Analyse des résultats
Structure de corrélation des critères
On peut synthétiser cette structure de corrélation des critères par le plan [1,2] des « loadings » d’une ACP à deux composantes retenues par validation croisée (64 % d’inertie), réalisée sur la fusion des tableaux 2 et 3. Ce plan apparaît en figure 8.
-0.20 -0.10 0.00 0.10 0.20 0.30 0.40 0.50 -0.40 -0.30 -0.20 -0.10 0.00 0.10 0.20 0.30 0.40 p[ 2] p[1] pf h rx2 ry2a q2 cm rdmodx ndmodx rdmody ls rt2 sdep
Figure 8 :Plan [1,2] des « loadings » de l’ACP pour ADPN.
On perçoit nettement sur la figure 8 :
- le groupe constitué par les critères h, , , très corrélés entre eux, qui s’oppose à LSE et SDEP,
RTo p2, RYh2,adj Qcum2
- le groupe constitué par les critères pf , NDMODX, RDMODY, Cmax orthogonal au groupes précédent.
Compte tenu de l’objectif de cette étude, les critères à privilégier sont pf et Q ; on cherche à obtenir des valeurs faibles de pf et des valeurs les plus proches possibles de 1 pour Q . La figure 8 nous laisse à penser que cette solution est accessible.
cum 2
cum 2
Regroupement des méthodes
Examinons maintenant le graphique de la figure 9 où sont positionnées les différentes méthodes de sélection dans l’espace des critères pf et . On privilégie en effet ce graphique plutôt que celui du plan factoriel de l’ACP car, comme on l’a souligné ci-dessus, ces deux critères sont prioritaires.
Qcum 2
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 20 40 60 80 100 120 pf Q2cum
COEF5 , BCOR , RCOR , COR , RCOEF , CINT , NONE
1
2
3
SR-FMR , SR-VARC2 , SR-VARC1 , VARC1 , VARC2, SR-BMR , SR-BQ , SR-BSDEP , SR
GA, SR-GA et SR-SMR , FMR,SMR,BQ,BSDEP,JACK
Figure 9 :graphique [pf , Qcum2 ]pour ADPN.
Sur cette figure 9, l’ensemble 1 regroupe les méthodes intéressantes conduisant à des pf faibles et des forts ; on les appellera par la suite méthodes candidates. On observe que les méthodes GA et SR-GA sont dans cet ensemble 1.
Qcum2
Evolution des critères Qcum et SDEP 2
On donne en figure 7 les graphiques d'évolution des critères et SDEP pour les méthodes BQ et BSDEP. Il est tout à fait instructif d’observer un maximum pour la courbe du Q : cette observation confirme l’hypothèse que le Q peut s’améliorer quand le nombre de variables diminue, c’est-à-dire en fait quand on élimine des variables qui n’apportent probablement que du bruit. En outre, la figure 7 fait apparaître des optima qui se correspondent à une variable près. On confirmera ce comportement avec les autres jeux de données. Qcum2 cum 2 cum 2
Variabilité des solutions des méthodes GA et SR-GA
Ces méthodes conduisent à des solutions extrêmement variables comme le résume le coefficient de variation de chacun des critères indiqué au tableau 3.
7. Etude du jeu de données LATEX
7.1 Le modèle PLS complet
Le modèle PLS complet, avec les 117 variables et les 210 observations, s'appuie sur 2 composantes PLS significatives t1 et t2 . La valeur des caractéristiques apparaissant au tableau 4, indique que ce modèle est acceptable.
Caractéristique Valeur pf 117 h 2 RX2 (%) 22 (%) RYadj2 71 Qcum2 0.65 Cmax 236 RDMODX 4.82 NDMODX 34 RDMODY 4796 LSE 0.61 RTo p2, 0.55 SDEP 1.27
Tableau 4 : Caractéristiques du modèle PLS complet de LATEX.
-5 0 5 10 -8 -6 -4 -2 0 2 4 6 Ellipse: Hotelling T2 (0.05) t[ 2 ] t[1] -0.2 -0.1 0.0 0.1 0.2 0.3 -0.2 -0.1 0.0 0.1 0.2 0.3 Y w* c [2 ] w*c[1]
Figure 10 : Graphiques [ t1 , t2 ] et [w*c[1] , w*c[2] ] du modèle complet de LATEX.
-5 0 5 10 -5 0 5 10 u[1] t[1] -8 -6 -4 -2 0 2 4 6 -10 -5 0 5 10 u[2] t[2]
Figure 11 : Graphiques [ u1 , t1] et [ u2 , t2] du modèle complet de LATEX.
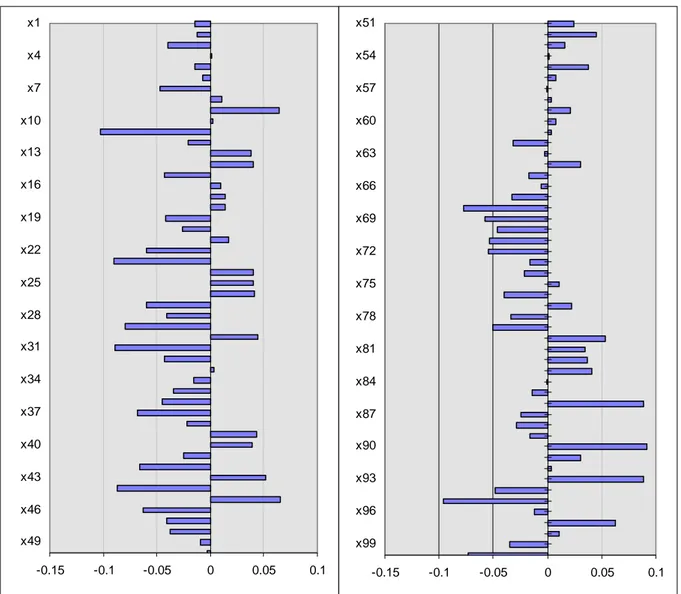
La figure 12 donne les coefficients de régression PLS centrés-réduits sous forme de barre horizontale. La présence de très faibles coefficients (en valeur absolue) nous incite encore à faire de la sélection de variables.
-0.1 -0.05 0 0.05 0.1 X1 X3 X5 X7 X9 X11 X13 X15 X17 X19 X21 X23 X25 X27 X29 X31 X33 X35 X37 X39 X41 X43 X45 X47 X49 X51 X53 X55 X57 X59 -0.1 -0.05 0 0.05 0.1 X61 X63 X65 X67 X69 X71 X73 X75 X77 X79 X81 X83 X85 X87 X89 X91 X93 X95 X97 X99 X101 X103 X105 X107 X109 X111 X113 X115 X117
Figure 12 : Coefficients de régression PLS centrés-réduits du modèle complet de LATEX.
0.0 0.5 1.0 1.5 2.0 2.5 3.0 DCrit (0.05)
Dcrit [2] = 1.163 , Normalized distances, Non weighted residuals
D M od X [2] 0.0 0.5 1.0 1.5 S im ca -P 3 .01 by U m et ri A B 1 999-01-08 1 1 :3 8 D M od Y [2]
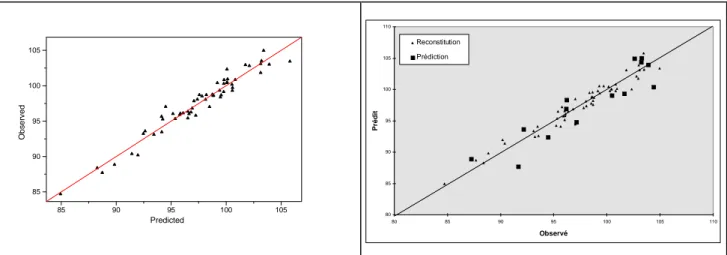
4 5 6 7 8 4 5 6 7 8 Ob se rv e d Predicted 3 4 5 6 7 8 9 3 4 5 6 7 8 Observé Prédit 9 Reconstitution Prédiction
7.2 Résultats des méthodes de sélection
On récapitule au tableaux 5 et 6 les résultats des méthodes de sélection.
Méthode pf h RX2 (%) RYadj2 (%) Qcum2 Cmax R D M O D X N D M O D X R D M O D Y LSE RTo p, 2 (%) SDEP NONE 117 2 22 71 0.65 234 6.34 34 5098 0.61 55 0.66 SR 63 2 36 66 0.63 348 5.86 40 464 0.67 49 0.70 SR-FMR 16 2 28 73 0.68 173 6.33 20 2675 0.59 66 0.56 SR-BMR 26 2 42 62 0.59 31 9.30 23 1654 0.70 44 0.75 SR-SMR 15 2 37 68 0.64 63 5.08 17 2062 0.64 57 0.64 SR-BQ 11 2 52 71 0.70 8 9.56 12 1492 0.62 52 0.70 SR-BSDEP 13 2 49 70 0.67 15 11 13 1351 0.63 57 0.66 SR-VARC1 15 2 31 68 0.65 6 7.44 21 1103 0.64 42 0.32 SR-VARC2 14 1 19 62 0.60 4 6.21 19 2012 0.71 50 0.32 FMR 19 2 31 70 0.66 8 5.05 26 2933 0.62 50 0.68 BMR 27 2 29 64 0.58 33 11.22 16 680 0.69 46 0.72 SMR 18 2 33 70 0.65 210 5.42 24 191 0.63 47 0.72 BQ 24 2 39 72 0.70 3 5.95 20 646 0.60 60 0.62 BSDEP 24 2 39 72 0.70 3 5.95 20 646 0.60 60 0.62 VARC1 23 2 26 58 0.51 30 6 23 370 0.74 50 0.68 VARC2 37 2 18 66 0.56 513 6 23 48207 0.66 56 0.64 COR 100 2 26 69 0.64 87 6.25 33 1295 0.63 55 0.65 BCOR 101 2 26 69 0.64 109 6.63 33 1050 0.63 55 0.66 RCOR 89 2 29 69 0.32 183 5.75 34 91 0.63 54 0.67 COEF5 54 2 28 72 0.68 13 5.37 27 602 0.61 58 0.64 RCOEF 106 2 23 71 0.66 125 6.55 29 540 0.61 55 0.65 CINT 112 2 22 71 0.65 90 5.88 30 762 0.61 55 0.65 JACK 53 2 30 72 0.69 154 4.33 32 4254 0.60 51 0.70 CV% 80 11 28 6 396 121 27 30 282 6 11 17 Tableau 5 : Caractéristiques du modèle PLS obtenu pour chaque méthode, pour LATEX.
R
Méthode p f h RX2 (%) RYadj2 (%) Qcum 2 C max O D X O D X O D Y LSE RT o p, 2 (%) SDEP GA1 20 2 20 80 0.75 178 5.70 20 265 0.51 70 0.53 GA2 16 2 22 80 0.75 22 9.00 21 1196 0.51 67 0.56 GA3 14 2 21 80 0.76 252 9.28 19 1021 0.51 74 0.49 GA4 27 2 17 81 0.75 338 6.95 27 5827 0.50 75 0.48 GA5 16 2 24 80 0.75 37 9.36 17 507 0.51 67 0.56 GA6 17 2 23 80 0.76 15 9.54 22 281 0.51 71 0.52 GA7 20 2 25 73 0.67 56 8.23 17 696 0.59 61 0.61 GA8 14 2 23 80 0.76 17 8.64 18 817 0.51 73 0.50 GA9 16 2 21 81 0.75 153 7.26 23 1380 0.50 72 0.52 GA10 10 2 26 79 0.76 16 17.24 18 2261 0.52 70 0.53 CV% 27 0 12 3 4 107 34 16 116 5 6 7 SR-GA1 12 2 29 77 0.73 14 10 17 8188 0.55 70 0.54 SR-GA2 10 1 17 75 0.73 5 7 16 1711 0.57 59 0.63 SR-GA3 13 2 29 77 0.73 18 9 16 3056 0.55 59 0.65 SR-GA4 12 1 19 75 0.73 5 10 16 842 0.58 76 0.32 CV% 11 38 27 2 0 62 16 3 95 3 13 28 Tableau 6 : Caractéristiques des modèles PLS obtenus pour 10 essais de la méthode GA et pour 4 essais de la
méthode SR-GA, pour LATEX.
On donne en figure 15 les graphiques d'évolution des critères et SDEP en fonction du nombre de variables explicatives pour les méthodes BQ et BSDEP.
Q2 0.610 0.620 0.630 0.640 0.650 0.660 0.670 0.680 0.690 0.700 0.710 0 10 20 30 40 50 60 70 80 90 100 110 120 h=1 h=2 SDEP 0.61 0.63 0.65 0.67 0.69 0.71 0.73 0.75 0 10 20 30 40 50 60 70 80 90 100 110 120 h=1 h=2
7.3 Analyse des résultats
Structure de corrélation des critères
On obtient maintenant le plan [1,2] des « loadings » de la figure 16.
-0.40 -0.30 -0.20 -0.10 0.00 0.10 0.20 0.30 0.40 0.50 -0.40 -0.30 -0.20 -0.10 0.00 0.10 0.20 0.30 0.40 p[ 2] p[1] pf h rx2 ry2a q2 cm rdmodx ndmodx rdmody ls rt2 sdep
Figure 16 :Plan [1,2] des « loadings » de l’ACP pour LATEX.
La structure de corrélation des critères diffère assez peu pour LATEX par rapport à celle du jeu de données précédent, si ce n’est que h et s’expriment maintenant plutôt selon une troisième dimension.
Qcum 2
Regroupement des méthodes
Il apparaît sur la figure 17. L’ensemble 3 est à peu près le même que pour ADPN. Dans l’ensemble candidat les méthodes communes à ADPN et LATEX sont les GA et GA, et SR-SMR, SR-SMR, FMR, BQ, BSDEP.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0 20 40 60 80 100 120 140 pf Q2cum
RCOR , COR , BCOR , RCOEF , CINT , NONE
1
2
3
SR-VARC2 , VARC1 , SR-BMR , BMR , VARC2, JACK , COEF5 , SR
GA, SR-GA et SR-SMR , SR-FMR , SMR , FMR , SR-BQ , BQ , SR-BSDEP , BSDEP , SR-VARC1
Figure 17 :graphique [pf , Qcum2 ]pour LATEX.
Evolution des critères Qcum et SDEP
2
On retrouve les mêmes allures pour ces courbes d’évolution (figure 15) que dans le cas de ADPN. Là encore, les optima se correspondent presque exactement.
Variabilité des solutions des méthodes GA et SR-GA
Pour la méthode SR-GA on remarque la constance du mais qui n'empêche pas une grande variabilité du SDEP.
8. Etude du jeu de données OXY
8.1 Le modèle PLS complet
Le modèle PLS complet, avec 95 variables et 20 observations, s'appuie sur 3 composantes PLS significatives t1, t2 , t3 . La valeur des caractéristiques apparaissant au tableau 7 indique que ce modèle est acceptable.
Caractéristique Valeur pf 95 h 3 RX2 (%) 54 (%) RYadj2 87 Qcum2 0.65 Cmax 164 RDMODX 2.29 NDMODX 3 RDMODY 125 LSE 0.24 RTo p2, 0.94 SDEP 0.63
Tableau 7 : Caractéristiques du modèle PLS complet de OXY.
Comme pour les jeux précédents, on trouve ci-après quelques graphiques illustratifs.
-10 -5 0 5 10 -8 -6 -4 -2 0 2 4 6 8 Ellipse: Hotelling T2 (0.05) t[2] t[1] -10 -5 0 5 10 -6 -4 -2 0 2 4 6 Ellipse: Hotelling T2 (0.05) t[3] t[1]
-15 -10 -5 0 5 10 -10 -5 0 5 10 15 20 u[1] t[1] -15 -10 -5 0 5 10 -10 -5 0 5 10 15 20 u[2] t[2] -15 -10 -5 0 5 10 -10 -5 0 5 10 15 20 u[3] t[3]
Figure 19 : Graphiques [ u1 , t1 ] , [ u2 , t2 ] , [ u3 , t3 ] du modèle complet de OXY.
-0.2 -0.1 0.0 0.1 0.2 -0.2 0.0 0.2 0.4 -0.2 -0.1 0.0 0.1 0.2 -0.2 -0.1 0.0 0.1 0.2 0.3 Y Y w* c [2 ] w*c[1] w* c [3 ] w*c[1]
-0.1 -0.05 0 0.05 0.1 0.15 X1 X3 X5 X7 X9 X11 X13 X15 X17 X19 X21 X23 X25 X27 X29 X31 X33 X35 X37 X39 X41 X43 X45 X47 -0.1 -0.05 0 0.05 0.1 0.15 X49 X51 X53 X55 X57 X59 X61 X63 X65 X67 X69 X71 X73 X75 X77 X79 X81 X83 X85 X87 X89 X91 X93 X95
Figure 20 : Coefficients de régression PLS centrés-réduits du modèle complet de OXY.
0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 DCrit (0.05)
Dcrit [3] = 1.316 , Normalized distances, Non weighted residuals
D M od X [3] 0.0 0.2 0.4 0.6 0.8 D M od Y [3]
6.0 6.5 7.0 7.5 8.0 6.0 6.5 7.0 7.5 8.0 Ob s e rv ed Predicted 4 5 6 7 8 9 4 5 6 Prédit 7 8 9 O b ser vé Reconstitution Prédiction
8.2 Résultats des méthodes de sélection
On récapitule au tableaux 8 et 9 les résultats des méthodes de sélection.
Méthode pf h RX2 (%) RYadj2 (%) Qcum2 Cmax R D M O D X N D M O D X R D M O D Y LSE RTo p, 2 (%) SDEP NONE 95 3 54 87 0.65 164 2.29 3 125 0.24 94 0.63 SR 16 2 70 66 0.48 76 3.98 1 23 0.41 33 0.90 SR-FMR 2 1 70 61 0.54 1.09 29.1 1 32 0.44 25 1.00 SR-BMR 9 1 65 45 0.41 1.5 4.09 0 46 0.53 1* 1.28 SR-SMR 2 1 70 61 0.54 1 29.10 1 32 0.44 25 1.00 SR-BQ 3 1 69 64 0.59 1 12.7 1 100 0.43 20 1.10 SR-BSDEP 9 2 75 66 0.53 47 7.1 1 88 0.40 57 1.40 SR-VARC1 3 1 59 57 0.48 1 15 0 22 0.47 51 1.18 SR-VARC2 4 1 53 59 0.55 1 4 0 71 0.46 36 0.70 FMR 5 2 63 84 0.75 3 12.31 1 10 0.28 96 1.01
BMR méthode non applicable à ce jeu de données
SMR 5 2 63 84 0.75 3 12.3 1 10 0.28 96 1.01 BQ 12 2 50 85 0.77 2 3.6 0 138 0.27 88 0.67 BSDEP 29 2 46 81 0.73 3 3.42 1 146 0.30 98 0.22 VARC1 18 3 45 83 0.23 35 3.6 1 59 0.28 9 1.32 VARC2 16 2 48 58 0.28 10 2.9 2 123 0.45 80 0.88 COR 79 3 63 84 0.66 77 2.2 2 32 0.27 92 0.89 BCOR 73 3 68 83 0.66 285 2.5 1 23 0.28 95 0.99 RCOR 60 3 71 83 0.69 158 2.3 2 39 0.28 94 1.20 COEF5 58 3 54 87 0.73 8 2.4 2 51 0.24 98 0.41 RCOEF 72 3 55 89 0.72 136 2.4 2 2038 0.23 97 0.55 CINT 90 3 55 88 0.67 45 2.3 3 14283 0.24 95 0.62 JACK 21 2 62 82 0.77 9 2.4 0 115 0.29 97 0.54 CV% 105 39 15 18 26 154 110 77 380 28 52 35 Tableau 8 : Caractéristiques du modèle PLS obtenu pour chaque méthode, pour OXY.
* cette valeur n'est pas une erreur ; en effet sur les 5 points du jeu test un seul point mal placé peut suffire à perturber beaucoup les différentes caractéristiques de ce jeu test.
Méthode pf h RX2 (%) RYadj2 (%) Qcum2 Cmax R D M O D X N D M O D X R D M O D Y LSE RTo p, 2 (%) SDEP GA1 17 3 64 98 0.83 8 3.89 1 61 0.10 28 1.24 GA2 16 3 60 97 0.72 9 3.86 1 460 0.12 30 1.55 GA3 21 3 58 97 0.67 22 3.95 1 13 0.12 21 1.29 GA4 18 3 70 98 0.87 8 2.82 0 34 0.10 66 1.98 GA5 15 3 68 98 0.86 7 2.92 0 51 0.10 69 0.92 GA6 14 3 62 97 0.71 296 2.58 0 279 0.13 63 1.10 GA7 20 3 68 91 0.74 129 2.59 0 14 0.19 70 0.59 GA8 17 3 63 97 0.87 72 3.87 1 83 0.12 73 2.22 GA9 18 3 61 98 0.72 38 3.15 1 34 0.11 57 0.61 CV% 13 0 6 2 10 146 18 95 134 23 39 44 SR-GA1 8 1 59 52 0.41 1.50 4.79 0 35 0.49 0.01 1.49 SR-GA2 8 1 59 52 0.41 1.50 4.79 0 35 0.49 0.01 1.49 SR-GA3 5 1 57 62 0.53 1.44 5.38 0 32 0.44 7 1.44 SR-GA4 5 1 57 62 0.53 1.44 5.38 0 32 0.44 7 1.44 SR-GA5 5 1 57 62 0.53 1.44 5.38 0 32 0.44 7 1.44 CV% 24 0 2 10 14 2 6 0 5 6 97 2
Tableau 9 : Caractéristiques des modèles PLS obtenus pour 9 essais de la méthode GA et pour 5 essais de la
méthode SR-GA, pour OXY.
On donne en figure 23 les graphiques d'évolution des critères Qcum et SDEP.
Q2 0.500 0.550 0.600 0.650 0.700 0.750 0.800 0 10 20 30 40 50 60 70 80 90 100 h=1 h=2 h=3 SDEP 0.200 0.300 0.400 0.500 0.600 0.700 0.800 0.900 1.000 1.100 1.200 1.300 1.400 1.500 0 10 20 30 40 50 60 70 80 90 h=1 100 h=2 h=3
Figure 23 : Graphiques d'évolution des critères Qcum et SDEP(méthodes BQ et BSDEP)pour OXY. 2
8.3 Analyse des résultats
Structure de corrélation des critères
On obtient maintenant le plan [1,2] des « loadings » de la figure 24.
-0.40 -0.30 -0.20 -0.10 0.00 0.10 0.20 0.30 0.40 -0.40 -0.30 -0.20 -0.10 0.00 0.10 0.20 0.30 0.40 p[ 2] p[1] pf h rx2 ry2a q2 cm rdmodx ndmodx rdmody ls rt2 sdep
Figure 24 :Plan [1,2] des « loadings » de l’ACP pour OXY.
La structure de corrélation des critères reste, pour l’essentiel, assez proche de celles des deux jeux de données précédents. On remarque toutefois la différence de comportement du critère SDEP ce qui s’explique facilement par la taille particulièrement réduite du jeu test, et donc pour lequel quelques observations un peu éloignées des autres peuvent suffire à influencer beaucoup le critère comme on peut le constater sur le graphique de droite de la figure 22.
Il apparaît sur la figure 25. L’ensemble 3 est à peu près le même que pour ADPN et LATEX. Dans l’ensemble candidat les méthodes communes à ADPN, LATEX et OXY sont les GA, SMR, FMR, BQ, BSDEP. On note que la méthode SR-GA n’est plus maintenant dans l’ensemble candidat 1. 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 20 40 60 80 pf Q2cum 100
COEF5 , RCOR , RCOEF , BCOR , COR , CINT, NONE
1
2
3
SR-GA , SR , SR-FMR , SR-BMR , SR-SMR , SR-BQ , SR-BSDEP , SR-VARC2 , SR-VARC1 , VARC1 , VARC2 GA, FMR , SMR , BQ , BSDEP , JACK
Figure 25 :graphique [pf , Qcum2 ]pour OXY.
Evolution des critères Qcum et SDEP 2
La courbe du présente un maximum pour 12 variables qui ne correspond pas cette fois-ci à un minimum de la courbe du SDEP. On peut en trouver la raison dans la remarque faite plus haut au sujet de la taille du jeu test.
![Figure 2 : Graphiques [ u 1 , t 1 ] , [ u 2 , t 2 ] , [ u 3 , t 3 ] du modèle complet de ADPN](https://thumb-eu.123doks.com/thumbv2/123doknet/7791402.259960/23.892.102.795.151.684/figure-graphiques-modèle-complet-adpn.webp)
![Figure 8 :Plan [1,2] des « loadings » de l’ACP pour ADPN.](https://thumb-eu.123doks.com/thumbv2/123doknet/7791402.259960/29.892.115.649.126.469/figure-plan-loadings-l-acp-adpn.webp)
![Figure 9 :graphique [ p f , Q cum 2 ] pour ADPN.](https://thumb-eu.123doks.com/thumbv2/123doknet/7791402.259960/30.892.111.805.105.613/figure-graphique-p-f-q-cum-pour-adpn.webp)