Efficient Gaussian Sampling for Solving Large-Scale Inverse Problems using MCMC
Texte intégral
Figure





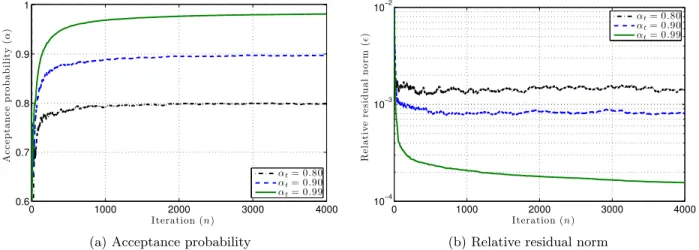


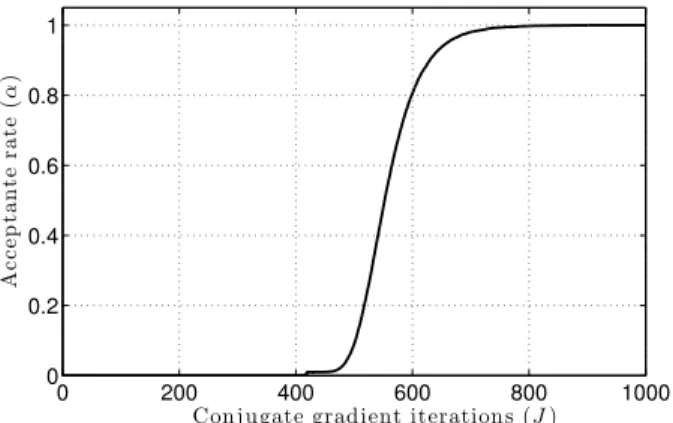
Documents relatifs
Following this first round of analysis, samples found to be contaminated with aflatoxins (7 field samples and 12 silo samples) were further analyzed to identify fungal contamination
Odijk (1996) proposes the PCG (PESP Cut Generation) algorithm to generate timetables for train operations using a mathematical model consisting of periodic
The in- dividual performance ProPerf p of each target property is computed using the type of Gaussian function (see Eq. 3 ) and their respective parameters val and tol are also
An adaptive sampling method using Hidden Markov Random Fields for the mapping of weed at the field scaleM. Mathieu Bonneau, Sabrina Gaba, Nathalie Peyrard,
Keywords: large berth allocation problem, long term horizon, algorithm portfolio, quality run-time trade-off, real traffic
In Liu Hui’s preface, mathematics is given not only to have unfolded, but also to have unfolded throughout Antiquity in a specific way: starting from the “table of multiplication”,
The challenges of these computations are related to: (i) the size of our 8387-bus system, which models a large part of Europe, is roughly three times larger than previously
However, the original reservoir sam- pling algorithm is not designed for distributed computing environments: data shuffling among clusters for a single query is required because
