SimScene : a web-based acoustic scenes simulator
Texte intégral
Figure
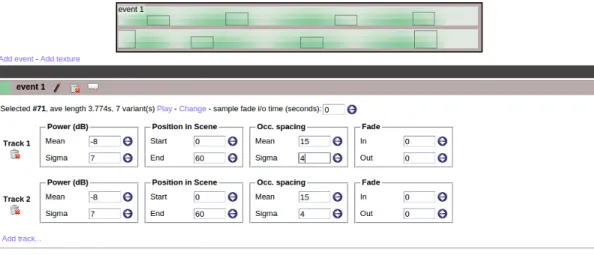
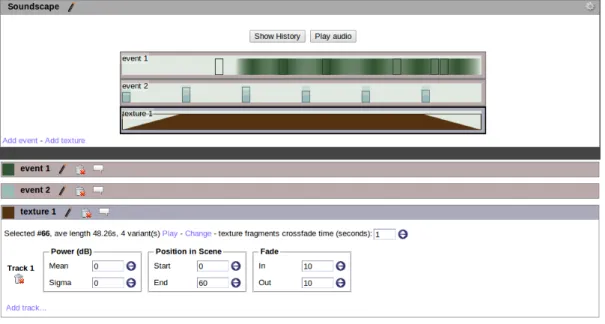
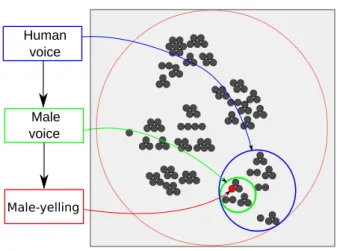
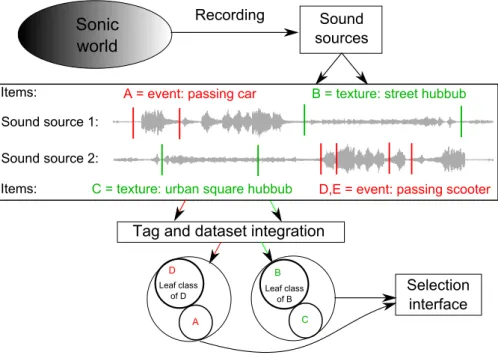
Documents relatifs
If an abstract graph G admits an edge-inserting com- binatorial decomposition, then the reconstruction of the graph from the atomic decomposition produces a set of equations and
The aim of this paper is to describe the simulation software which is being developed by the URE-CNS of the ENAC for the prediction of the errors induced by obstacles on the code
In the infrared range, the spectral flux coming from an object depends upon the meteorological conditions existing in the scene: surface temperature, air temperature, humidity of
To be able to characterize the population’s distribution for non-vanishing effects of mutations, one should prove a uniqueness property for the viscosity solution of the
Sensory information was manipulated by providing visual (optic flow, limited lifetime star field), vestibular-kinaesthetic (passive self motion with eyes closed), or visual
• Figure 10 shows the experimental daily distribution of the household current consumption in the winter season;. • Figure 11 shows The experimental daily distribution of the
We propose to use the formulations of answers that are correct for other states (vertices in the algorithm graph) as distractors, as well as use the correct
The author thanks the students of the university course in Design and Management of Cultural Tourism of the Univer- sity of Padova for participating to the crowdsourcing exper-
