A path following algorithm for the graph matching problem
Texte intégral
Figure


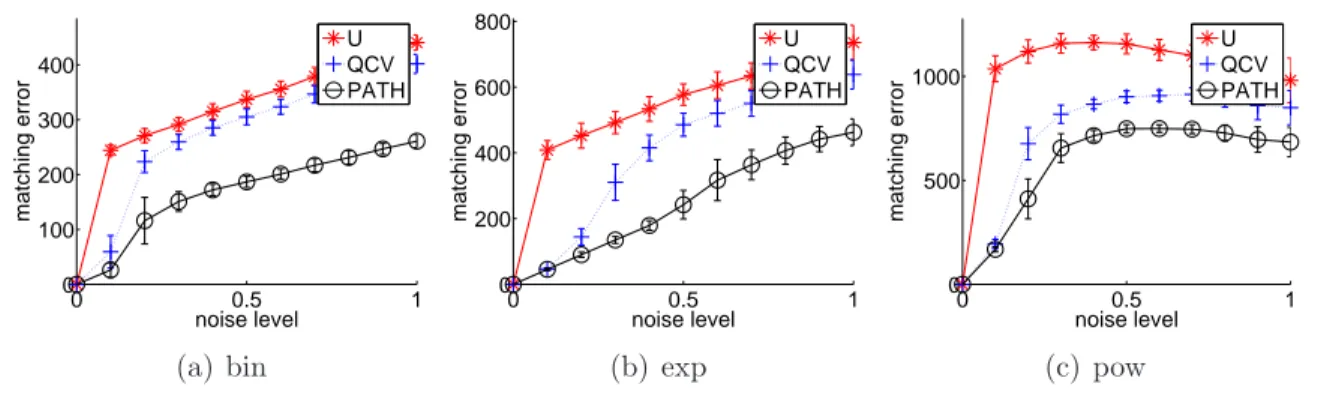



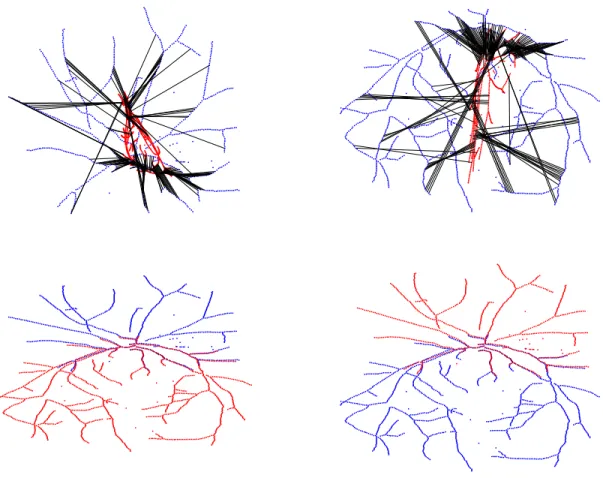

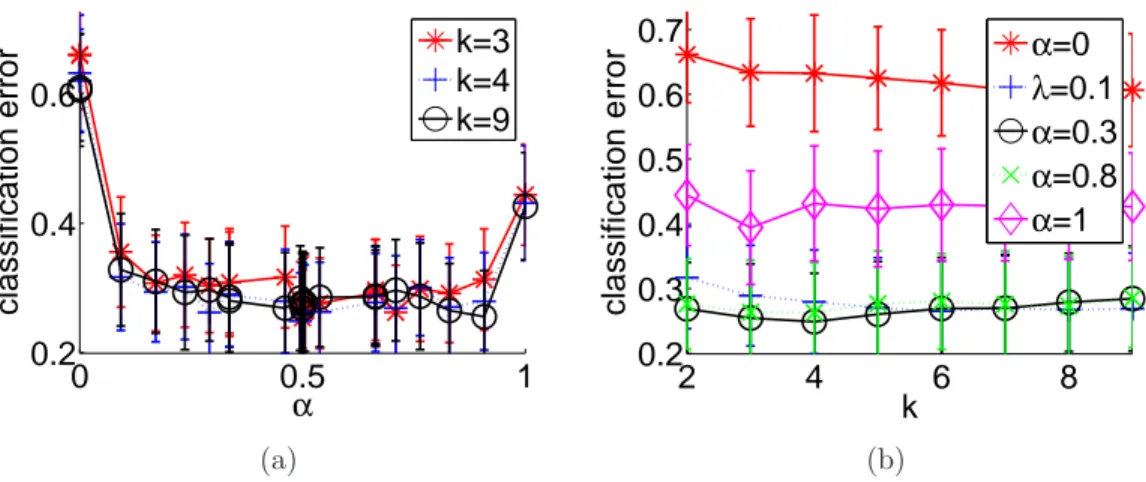

Documents relatifs
Because this problem is an NP- hard problem there is not a known deterministic efficient (polinomial) method. Non- deterministic methods are in general more efficient but an
In the absence of transaction costs and restrictions on the available investment universe the bank can easily solve the TPMP by liquidating the initial portfolio, collecting
The graph edit distance is a very flexible distance measure for attributed graphs, which is widely used in the pattern recognition community.. It can be viewed as the minimum cost
Distinctive parts for scene classification, in: Proceedings of the IEEE Con- ference on Computer Vision and Pattern Recognition, 2013.
Despite these solutions are effective in producing a proper coloring, generally minimizing the number of colors, they produce highly skewed color classes, undesirable for
In order to allow constraint solvers to handle GIPs in a global way so that they can solve them e ciently without loosing CP's exibility, we have in- troduced in [1] a
In this article, we discussed a multi-valued neural network to solve the quadratic assignment problem (QAP) using four dynamic starting from pseudo feasible solutions
Higher order connected link averages could be included in (19) as well, but in this paper we shall only consider the effect of triangular correlations in order to keep
