Modélisation de la dépendance entre les garanties
applicables en assurance automobile
Mémoire présenté
à la Faculté des études supérieures de l’Université Laval dans le cadre du programme de maîtrise en statistique pour l’obtention du grade de Maître ès sciences (M.Sc.)
FACULTÉ DES SCIENCES ET DE GÉNIE UNIVERSITÉ LAVAL
QUÉBEC
2011
c
Dans un portefeuille d’assurance automobile, différents types de réclamations peu-vent survenir pour chaque police en vigueur. En cas de collision entre deux véhicules, l’assuré peut déposer une réclamation pour dommages corporels et matériels à lui-même et à autrui. Traditionnellement, ces types de risques ont été considérés comme indépendants afin d’en faciliter la modélisation stochastique. Dans la pratique, on ob-serve toutefois une dépendance entre les montants de ces réclamations dont il importe de tenir compte pour mieux quantifier le risque global du portefeuille. Frees et Valdez
(2008) ont proposé un modèle permettant de considérer certaines dépendances entre les fréquences et les sévérités des garanties impliquées dans les réclamations d’une même police d’assurance. Dans ce mémoire, deux structures de modèles inspirées de celle de
Frees et Valdez(2008) sont proposées pour modéliser les sinistres d’un portefeuille d’as-surance automobile de l’Ontario. L’ajustement des modèles est réalisé par la méthode de vraisemblance maximale ainsi que par une approche bayésienne.
Je tiens tout d’abord à remercier mon directeur de recherche, M. Thierry Duchesne, professeur au Département de mathématiques et de statistique de l’Université Laval, ainsi que mon co-directeur, M. Christian Genest, professeur au Département de ma-thématiques et de statistique de l’Université McGill, pour leur disponibilité, mais aussi pour toute l’aide et le soutien qui ont été nécessaires à la réalisation de ce projet. Je tiens spécialement à remercier M. Duchesne pour la qualité de ses conseils dans ce projet et dans la rédaction de ce mémoire, mais aussi pour avoir partagé tant d’enrichissantes discussions au cours de la dernière année.
J’aimerais aussi remercier mes superviseurs de la compagnie d’assurance, M. Étienne Plante-Dubé et M. Danaïl Davidov, qui m’ont permis d’apprendre énormément dans le domaine de l’assurance et qui m’ont aussi très bien guidé lors de la réalisation de ce projet. Je tiens d’ailleurs à remercier Danaïl pour toutes les heures où nous avons échangé des courriels afin de discuter du projet. Un merci spécial à M. Mathieu Fran-cœur qui a contribué au projet en apportant des informations et des suggestions qui furent très utiles dans sa conception et sa réalisation.
Mes remerciements vont aussi au Fonds québécois de la recherche sur la nature et les technologies (FQRNT), au fonds de subvention MITACS Accélération, ainsi qu’à l’Université Laval pour les fonds octroyés à la réalisation de ce projet.
Finalement, je suis reconnaissant envers ma fiancée Lucie et toute ma famille pour leur soutien et leur amour qui ont été une motivation supplémentaire à la réussite de ce projet et de mes études.
Résumé ii
Avant-Propos iii
Table des matières vi
Liste des tableaux ix
Liste des figures xi
1 Introduction 1
1.1 Problématique . . . 2
1.2 Objectifs du projet . . . 3
2 Revue de la littérature 4 2.1 Structure des données . . . 5
2.2 Modèle . . . 7
2.2.1 Composante 1 : Fréquence des demandes d’indemnisation . . . . 7
2.2.2 Composante 2 : Type de réclamations effectuées lors des de-mandes d’indemnisation . . . 9
2.2.3 Composante 3 : Sévérité des montants pour chaque type de ré-clamation . . . 11
3 Analyses préliminaires 14 3.1 Provenance des données . . . 14
3.1.1 Covariables préliminaires . . . 14
3.1.2 Variables dépendantes d’intérêt . . . 15
3.1.3 Utilisation de la fréquence des demandes d’indemnisation . . . . 18
3.1.4 Autres détails sur le jeu de données . . . 18
3.1.5 Logiciel utilisé pour le projet . . . 19
3.2 Analyses préliminaires de la dépendance . . . 20
3.2.1 Modélisation de la dépendance entre les sévérités . . . 20
3.2.3 Modélisation de la fréquence étant donné la sévérité . . . 24
3.2.4 Modélisation de la sévérité étant donné la fréquence . . . 25
3.3 Imputation de données . . . 27
3.4 Résumé des analyses préliminaires . . . 29
4 Structure des modèles 32 4.1 Structure hybride . . . 33
4.1.1 Choix de la loi pour les modèles de sévérité . . . 35
4.1.2 Loi multinomiale . . . 40
4.1.3 Sélection des covariables . . . 43
4.1.4 Utilisation du modèle hybride dans la pratique actuarielle . . . . 46
4.2 Structure hiérarchique . . . 49
4.2.1 Régression logistique . . . 50
4.2.2 Utilisation du modèle hiérarchique dans la pratique actuarielle . 53 5 Résultats des analyses 54 5.1 Structure hybride . . . 54 5.1.1 Modèle de tarification . . . 55 5.1.2 Modèle d’indemnisation . . . 60 5.2 Structure hiérarchique . . . 62 6 Analyses bayésiennes 63 6.1 Modèle . . . 64 6.2 Résultats de l’ajustement . . . 68
6.3 Reproduction d’un portefeuille . . . 69
7 Conclusion 73 Bibliographie 75 A Autres résultats des analyses préliminaires 78 A.1 Résultats de la régression logistique . . . 78
A.2 Résultats complémentaires de l’analyse de la variance . . . 79
A.3 Résultats complémentaires sur la dépendance des montants de sévérité 80 A.4 Histogrammes des montants de sévérité . . . 83
B Théorie : Imputation multiple 87 C Résultats de l’ajustement des modèles 89 C.1 Résultats du choix des modèles de sévérité . . . 89
C.2 Résultats pour les modèles logistiques . . . 91
D.1 Structure hybride . . . 94
D.1.1 Modèle de tarification . . . 94
D.1.2 Modèle d’indemnisation . . . 99
D.2 Structure hiérarchique . . . 104
E Échantillonneur de Gibbs 107
2.1 Covariables utilisées lors de l’ajustement des modèles pour la composante
de la fréquence . . . 9
2.2 Combinaison possible de chaque type de réclamation . . . 10
2.3 Définition de chaque type de réclamation . . . 10
3.1 Covariables préliminaires à considérer dans le projet . . . 15
3.2 Explication des garanties considérées . . . 16
3.3 Mesures de dépendance entre les sévérités des garanties . . . 22
3.4 Tests sur les rapports de cotes . . . 24
3.5 Moyenne des montants de chaque garantie selon le type de garanties réclamées lors d’un même accident . . . 25
3.6 Estimation des paramètres de la régression logistique de la fréquence de la garantie AB en fonction du montant de dommages matériels DOMM 25 3.7 Effets significatifs de la fréquence des garanties sur le montant de dom-mages AB par une analyse de la variance . . . 26
3.8 Combinaisons possibles des types de réclamation pour les analyses de ce projet . . . 30
3.9 Moyenne des montants de chaque garantie selon le type de garanties réclamées lors d’un même accident : Retrait de la garantie TPL-PD . . 30
4.1 Distributions considérés pour l’ajustement des modèles de sévérité . . . 36
5.1 Coefficients estimés pour le modèle de sévérité des dommages matériels pour la covariable relative à l’âge du conducteur principal assuré . . . . 57
5.2 Variation des coefficients du modèle multinomial en considérant la pro-babilité de deux modalités fixées . . . 59
6.1 Covariables utilisées lors de l’ajustement du modèle bayésien . . . 67
6.2 Comparaison des valeurs prédites de la valeur totale des indemnités ver-sées selon la première approche avec les valeurs observées des 1000 por-tefeuilles . . . 71
6.3 Comparaison des valeurs prédites de la valeur totale des indemnités ver-sées selon la deuxième approche avec les valeurs observées des 1000 por-tefeuilles . . . 72
A.1 Estimation des paramètres de la régression logistique de la fréquence de la garantie TPL-BI en fonction du montant de dommages matériels DOMM 78
A.2 Estimation des paramètres de la régression logistique de la fréquence de la garantie TPL-PD en fonction du montant de dommages matériels DOMM . . . 78
A.3 Effets de la fréquence des garanties sur le montant de dommages DOMM par une analyse de la variance . . . 79
A.4 Effets de la fréquence des garanties sur le montant de dommages BI par une analyse de la variance . . . 79
C.1 Résultats de l’ajustement des distributions considérées pour le modèle de sévérité des dommages matériels . . . 89
C.2 Résultats de l’ajustement des distributions considérées pour le modèle de sévérité des blessures corporelles . . . 90
D.1 Explication des covariables utilisées dans les modèles présentés . . . 93
D.2 Résultats partiels de l’estimation des paramètres du modèle de sévérité de dommages matériels du véhicule assuré (garantie DOMM) pour la structure hybride de tarification selon la méthode du maximum de vrai-semblance . . . 94
D.3 Résultats partiels de l’estimation des paramètres du modèle multinomial pour la structure hybride de tarification selon la méthode du maximum de vraisemblance . . . 95
D.4 Résultats partiels de l’estimation des paramètres du modèle de sévérité des blessures corporelles subies par l’assuré (garantie AB) pour la struc-ture hybride de tarification selon la méthode du maximum de vraisemblance 96
D.5 Résultats partiels de l’estimation des paramètres du modèle de sévé-rité des dommages matériels du véhicule assuré (garantie DOMM) pour la structure hybride d’indemnisation selon la méthode du maximum de vraisemblance. . . 99
D.6 Résultats partiels de l’estimation des paramètres du modèle multinomial pour la structure hybride d’indemnisation selon la méthode du maximum de vraisemblance. . . 100
D.7 Résultats partiels de l’estimation des paramètres du modèle de sévé-rité pour les blessures corporelles subies par l’assuré (garantie AB) pour la structure hybride d’indemnisation selon la méthode du maximum de vraisemblance. . . 101
D.8 Résultats partiels de l’estimation des paramètres du modèle logistique expliquant la présence d’une réclamation pour les blessures corporelles subies par l’assuré (garantie AB) pour la structure hiérarchique d’indem-nisation selon la méthode du maximum de vraisemblance. . . 104
D.9 Résultats partiels de l’estimation des paramètres du modèle de sévérité pour les blessures corporelles subies par l’assuré (garantie AB) pour la structure hiérarchique d’indemnisation selon la méthode du maximum de vraisemblance. . . 105
F.1 Estimation des paramètres par la méthode bayésienne et par la méthode du maximum de vraisemblance pour le modèle de sévérité des dommages matériels du véhicule assuré. . . 109
F.2 Estimation des paramètres par la méthode bayésienne et par la méthode du maximum de vraisemblance pour la loi multinomiale. . . 110
4.1 Structure du modèle hybride . . . 34
4.2 Structure du modèle hiérarchique . . . 50
A.1 Graphique des rangs pour les sévérités des garanties AB et DOMM . . 80
A.2 Graphique des rangs pour les sévérités des garanties TPL-PD et DOMM 81
A.3 Graphique des rangs pour les sévérités des garanties TPL-BI et AB . . 82
A.4 Histogramme des montants de sévérité des dommages matériels . . . . 83
A.5 Histogramme des montants de sévérité des blessures à la personne assurée sachant qu’il n’y a pas de réclamation pour des blessures à une tierce personne . . . 84
A.6 Histogramme des montants de sévérité des blessures à la personne assurée sachant qu’il y a aussi une réclamation pour des blessures à une tierce personne . . . 84
A.7 Histogramme des montants de sévérité des blessures à une tierce personne sachant qu’il n’y a pas de réclamation pour des blessures à la personne assurée . . . 85
A.8 Histogramme des montants de sévérité des blessures à une tierce personne sachant qu’il y a aussi une réclamation pour des blessures à la personne assurée . . . 85
A.9 Histogramme des montants de sévérité des dommages matériels avec la densité estimée de la loi gamma . . . 86
C.1 Courbe ROC obtenue pour le modèle logistique concernant la présence d’une réclamation pour les blessures corporelles à l’assuré. . . 91
D.1 Valeurs observées et prédites du montant de sévérité des dommages ma-tériels par le modèle hybride de tarification pour la population classée selon l’âge. . . 97
D.2 Différentiels du montant de sévérité des dommages matériels par le mo-dèle hybride de tarification pour la population classée selon l’âge. . . . 97
D.3 Valeurs observées et prédites de la probabilité de la présence d’une ré-clamation pour la garantie AB et d’une réré-clamation pour la garantie BI par le modèle hybride de tarification pour la population classée selon l’âge. 98
D.4 Différentiels de la probabilité de la présence d’une réclamation pour la garantie AB et d’une réclamation pour la garantie BI par le modèle hybride de tarification pour la population classée selon l’âge. . . 98
D.5 Valeurs observées et prédites du montant de sévérité des dommages ma-tériels par le modèle hybride d’indemnisation selon le pourcentage de responsabilité. . . 102
D.6 Différentiels du montant de sévérité des dommages matériels par le mo-dèle hybride d’indemnisation selon le pourcentage de responsabilité. . . 102
D.7 Valeurs observées et prédites de la probabilité de la présence d’une récla-mation pour la garantie AB et d’une réclarécla-mation pour la garantie BI par le modèle hybride d’indemnisation selon le pourcentage de responsabilité. 103
D.8 Différentiels de la probabilité de la présence d’une réclamation pour la garantie AB et d’une réclamation pour la garantie BI par le modèle hybride d’indemnisation selon le pourcentage de responsabilité. . . 103
D.9 Valeurs observées et prédites de la probabilité de la présence d’une récla-mation pour la garantie AB par le modèle hiérarchique d’indemnisation selon le pourcentage de dommages matériels réclamés par rapport à la valeur actuelle du véhicule. . . 106
D.10 Différentiels de la probabilité de la présence d’une réclamation pour la garantie AB par le modèle hiérarchique d’indemnisation selon le pour-centage de dommages matériels réclamés par rapport à la valeur actuelle du véhicule. . . 106
Introduction
Le domaine de l’assurance en est un où la recherche de nouvelles méthodes est omniprésente afin d’améliorer et de peaufiner les pratiques actuelles dans le but d’attirer de nouveaux clients, mais aussi de convaincre les anciens clients de renouveler leurs assurances au sein de la même compagnie. En général, ce qui va attirer les clients à demander une soumission d’une compagnie d’assurances, c’est sa renommée. Les clients potentiels sont aussi attirés par les stratégies de marketing des compagnies, notamment par le truchement de la télévision, de la radio ou d’Internet. Il y a aussi toutes les nouvelles applications en ligne qui permettent de soumettre rapidement une demande d’assurances, et depuis peu, les compagnies commencent à offrir ces applications sur les cellulaires intelligents comme le iPhone et les BlackBerry afin de rejoindre une plus vaste clientèle.
Toutefois, on oublie souvent que derrière toutes ces nouvelles publicités et applica-tions, c’est la recherche actuarielle qui permet aux compagnies d’assurances d’être à la fois compétitives avec des tarifs concurrentiels et à l’abri de la faillite. Ces efforts constants permettent à chaque compagnie d’assurances d’améliorer sa compétitivité dans un marché où il est difficile de faire sa place. La recherche permet aussi à la compagnie d’assurances de s’assurer qu’elle prend les dispositions nécessaires pour faire face aux imprévus et qu’elle dispose des réserves monétaires suffisantes pour pallier aux différents problèmes qui peuvent se présenter.
Dans le cadre de ce projet, notre intérêt s’est porté vers l’assurance automobile. Chaque compagnie connaît l’importance de bien cibler les personnes qui sont suscep-tibles d’avoir un accident et de déposer une réclamation auprès de l’assureur. De plus, lorsqu’un accident se produit, il est important pour l’assureur de bien évaluer les coûts qui seront associés à l’indemnisation de l’assuré. En ciblant les différents groupes à
risque, la compagnie peut alors offrir des tarifs avantageux aux groupes de personnes présentant un risque moins élevé. Aux personnes jugées plus à risque, l’assureur pourra offrir un tarif plus élevé que la moyenne ou tout simplement refuser de les assurer. L’objectif de ce projet est de cibler ces différents groupes de personnes afin que l’assu-reur puisse prendre connaissance des risques qui leur sont liés et instaurer les mesures appropriées.
1.1
Problématique
Au Québec, l’assurance automobile est en partie gérée par les assureurs privés et par le gouvernement via la Société d’assurance automobile du Québec (SAAQ). La SAAQ s’occupe de l’indemnisation des blessures corporelles subies lors d’un accident, alors que les compagnies d’assurances s’occupent de l’indemnisation des dommages matériels aux véhicules assurés. Toutefois, dans le reste du Canada, la situation est différente. Par exemple, en Ontario, il n’y a aucune indemnisation offerte par une société d’état pour les blessures corporelles subies dans un accident de la route. Ce sont donc les compa-gnies d’assurances qui ont le mandat de régler le total de la facture pour les dommages matériels et corporels. Pour ces derniers, on inclut les différents dédommagements rela-tifs aux blessures subies, soit le remplacement de salaire de l’assuré, une indemnisation pour vices corporels (cicatrice ou toute marque apparente), le remboursement de frais afférents à la blessure (location de béquilles ou d’un fauteuil roulant, etc.), ainsi que toute autre réclamation relative aux blessures subies lors de l’accident.
Pour les compagnies d’assurances, il est donc primordial d’élaborer des modèles de prévision fiables pour les différents types de réclamations qui peuvent se produire. Les compagnies possèdent généralement des informations très détaillées pour les réclama-tions de dommages matériels, car on connaît les caractéristiques de l’assuré et de son véhicule. L’indemnité ne peut d’ailleurs jamais dépasser un certain seuil qui est généra-lement la valeur actuelle du véhicule assuré. Pour ce qui est des dommages corporels, les montants de réclamation sont plus difficiles à prédire. L’indemnité peut dépendre d’une multitude de facteurs, surtout pour les cas où une personne est blessée grièvement lors de l’accident. Par exemple, si l’assuré ne peut retourner travailler suite à l’accident, il y aura notamment une indemnité de remplacement de salaire qui dépendra de la durée de l’absence, du salaire de l’assuré, etc.
1.2
Objectifs du projet
Ce mémoire résume les analyses effectuées dans le cadre d’un projet de recherche subventionné par l’organisme MITACS et réalisé en collaboration avec une compagnie d’assurances canadienne. Dans ce projet, plusieurs modèles ont été envisagés afin de bien répondre à la problématique exposée. Ces modèles ont été construits à partir d’une structure hiérarchique proposée par Frees et Valdez (2008) dont un résumé sera présenté au chapitre 2. Ce modèle permet d’incorporer la corrélation qui peut exister entre les sévérités et les fréquences des réclamations pour différentes garanties présentes dans une police d’assurances.
Le premier objectif de ce mémoire est d’ajuster cette structure à la banque de données d’assurance automobile de la compagnie en Ontario. Si la structure proposée par Frees et Valdez s’avère inadéquate, quelques modifications y seront apportées afin qu’elle soit la plus représentative possible. Afin de valider l’utilisation de la structure de Frees et Valdez, certaines analyses préliminaires seront présentées au chapitre 3. À partir de celles-ci, il sera alors plus facile de proposer des structures de modèles qui sont appropriées à notre problématique. Les différentes structures utilisées dans le projet sont décrites au chapitre 4, où la théorie sous-jacente aux différents modèles proposés sera exposée. De plus, une liste des différentes applications actuarielles de ces modèles sera présentée. Les résultats concrets obtenus à partir des modèles seront présentés au chapitre 5.
Le deuxième objectif du mémoire consiste à appliquer une approche bayésienne appropriée pour l’une des structures utilisées dans ce projet. Le but est de développer un algorithme de simulation par chaîne de Markov afin d’obtenir les lois a posteriori et prédictives applicables à la base de données de l’Ontario. Cette approche bayésienne, ainsi que la théorie s’y rattachant, est expliquée au chapitre 6.
Revue de la littérature
Il existe une multitude de modèles actuariels permettant d’obtenir des prévisions fiables des montants de futures réclamations à partir de différentes observations faites sur un assuré. Parmi les informations utiles aux modèles actuariels, on retrouve notam-ment les caractéristiques de l’assuré (âge, sexe, etc.), les caractéristiques du véhicule assuré (marque et modèle du véhicule, cylindrée du moteur, etc.), le type d’assurance, ainsi que les réclamations effectuées dans le passé. Ces différentes observations sont souvent connues pour chaque année de validité du contrat d’assurance.
Le modèle qui sert de base à l’élaboration de ce projet est celui proposé par Frees et Valdez (2008). Ces auteurs se sont intéressés aux trois types de réclamations qui peuvent être effectuées dans le cadre d’une demande d’indemnisation, soient :
– les blessures à une tierce partie ;
– les dommages subis par l’assuré, ce qui inclut les blessures de l’assuré, les dom-mages subis par le véhicule de l’assuré, l’incendie du véhicule, le vol du véhicule ; – les dommages causés à une propriété (véhicule, etc.) appartenant à une tierce
partie.
Leur objectif était d’établir un modèle qui permette de prédire un montant pour chaque type de garantie impliquée. Par comparaison, les modèles traditionnels visent seulement à fournir une prévision du montant global de la réclamation, c’est-à-dire la somme des garanties impliquées. Pour atteindre leur but, Frees et Valdez ont pro-posé de travailler avec un modèle hiérarchique à trois composantes qui correspondent respectivement à la fréquence, au type et à la sévérité des réclamations.
Les données utilisées par Frees et Valdez proviennent du Bureau de l’Assurance Gé-nérale (GIA) de Singapour. Il s’agit d’une organisation regroupant la majorité des com-pagnies d’assurances générales de cette région. Les observations utilisées proviennent de chaque police d’assurance qui était valide entre les mois de janvier 1993 et décembre 2001, soit une période de neuf ans. Les observations proviennent de trois bases de don-nées : les polices d’assurance, les dossiers de réclamations et les dossiers d’indemnisation. Les dossiers des polices d’assurance permettent de connaître les différentes caractéris-tiques du véhicule et de l’assuré, ainsi que la période où l’assurance a été valide. Les dossiers de réclamations permettent d’obtenir le nombre d’accidents pour lesquels l’as-suré a effectué une réclamation. Finalement, les dossiers d’indemnisation permettent de connaître les montants payés pour chaque type de réclamation.
Frees et Valdez n’ont considéré que les polices d’assurance où seul un véhicule était assuré. Ceci représente environ 90% des polices d’assurance de l’ensemble des compa-gnies étudiées. Donc, l’unité d’observation pour leurs analyses était un véhicule assuré par l’une des neuf compagnies d’assurances pendant une année comprise entre 1993 et 2001. Afin de s’assurer que chaque type de réclamation était possible pour chaque demande d’indemnisation, seules les polices d’assurance comprenant une couverture complète ont été considérées ; une couverture complète comprend une assurance pour chaque type de réclamation, tandis qu’une couverture partielle peut ne couvrir que les dommages commis à une tierce partie.
2.1
Structure des données
Pour faciliter la compréhension des données, nous employons la même notation que Frees et Valdez (2008). Tout d’abord, chaque véhicule admissible assuré par la compagnie d’assurances est dénoté par i et chaque année entre 1993 et 2001 par t. Pour chaque unité d’observation it, les différentes variables réponses observées sont les suivantes :
– Nit, le nombre de demandes d’indemnisation effectuées durant l’année t pour le véhicule i ;
– Mit,j, le type de réclamation pour chaque demande d’indemnisation, j = 1,. . . ,Nit; – Cit,jk, le montant de chaque type de réclamation, k = 1,2,3 et pour chaque
de-mande d’indemnisation, j = 1,. . . ,Nit.
Lorsqu’une demande d’indemnisation est déposée, elle peut être constituée d’une seule réclamation ou d’une combinaison de plusieurs types de réclamations. Comme il
y a trois types de réclamations dans les données considérées par Frees et Valdez, il y a sept possibilités différentes de combinaisons de ces types, à savoir : les trois types de réclamations individuelles, trois combinaisons formées par deux types de réclamations, et la combinaison regroupant les trois types de réclamations.
Un autre aspect important que Frees et Valdez ont relevé dans leur base de données est la présence d’une franchise pour la réclamation des dommages subis par l’assuré. En effet, lors d’une demande d’indemnisation, le montant réclamé pour les pertes subies par l’assuré peut être inférieur à la valeur de la franchise. Frees et Valdez ont donc défini Cit,2k comme étant le montant excédant la franchise dit, et celui-ci est posé égal à zéro si le montant de la réclamation est inférieur à la valeur de la franchise. Par conséquent, le montant de la réclamation pour les pertes subies par l’assuré est une variable censurée par la valeur 0.
De plus, toutes les caractéristiques du véhicule assuré, ainsi que celles de la personne assurée, sont contenues dans le vecteur xit où x⊤it = (xit1, . . . , xitp). Une autre variable importante du jeu de données est la durée d’exposition du véhicule à risque pendant une année donnée. Cette variable, dénotée eit, est mesurée en fraction d’année. L’ensemble des informations contenues dans le jeu de données peut donc être résumé comme suit :
{dit, eit, Nit, Mit, Cit, xit; t = 1, . . . , Ti; i = 1, . . . , n},
où Mit est un vecteur de Nit valeurs identifiant le type de garanties impliquées et Cit est la matrice de dimensions 3× Nit des montants de chaque type de réclamation de la police i lors de l’année t. Si aucune réclamation n’a été faite pour la police i lors de l’année t, on impute la valeur 0 à Mit et Cit.
La base de données comprend n = 96 014 véhicules assurés où le ième véhicule a été observé Ti années entre 1993 et 2001 ; un véhicule peut donc avoir été observé pendant un maximum de neuf années. Le jeu de données totalise 199 352 observations, pour une moyenne de 2.08 observations par véhicule assuré. À l’examen du facteur d’exposition eit, Frees et Valdez ont conclu que les véhicules étaient observés sur une moyenne de 1.29 années.
2.2
Modèle
Le modèle utilisé par Frees et Valdez comporte trois composantes. La première sert à établir la fréquence des demandes d’indemnisation qui seront effectuées par l’assuré dans une année donnée. La deuxième vise à modéliser les types de réclamations qui seront incluses dans la demande d’indemnisation effectuée par l’assuré. Finalement, la troisième modélise le montant qui sera versé pour chaque type de réclamation de chaque demande d’indemnisation déposée par l’assuré. On peut donc exprimer la distribution conjointe de ces trois composantes de la façon suivante :
f (N, M, C) = f (N )× f(M|N) × f(C|M, N),
Conjointe = (Fréquence)× (Type de réclamations sachant la fréquence) × (Sévérité des réclamations sachant leur type et leur fréquence).
Frees et Valdez ont analysé chaque composante indépendamment des deux autres. Il peut exister une corrélation entre le nombre de demandes d’indemnisation effectuées dans une année, le type de réclamation, ainsi que le montant accordé pour chaque réclamation. Toutefois, cette corrélation n’a pas été mesurée et n’a pas été prise en compte dans leur analyse. De plus, Frees et Valdez avaient choisi préalablement des covariables, toutes présentes dans le vecteur x, qui étaient communes à la fréquence, aux types et à la sévérité des réclamations. Ceci avait pour but de faciliter la présentation de leur modèle. Toutefois, ils ont décidé de n’utiliser, dans chaque composante du modèle, que les covariables qui avaient un effet significatif.
2.2.1
Composante 1 : Fréquence des demandes
d’indemnisa-tion
Les modèles de prévision de la fréquence des demandes d’indemnisation ont fait l’ob-jet de multiples analyses dans la littérature actuarielle. Pour leurs analyses des données de Singapour, Frees et Valdez ont décidé d’utiliser des modèles standards de dénombre-ment avec effets aléatoires (Frees,2004). Parmi les modèles considérés pour cette étude, on retrouve notamment un modèle de Poisson et un modèle binomial négatif, avec ou sans la présence d’effets aléatoires.
La formule employée par Frees et Valdez pour modéliser la fréquence est de la forme : λit = eitexp ( αλi+ x⊤itβλ ) , où
λit = moyenne pour l’unité d’observation it ;
αλi = variable qui permet de tenir compte de la dépendance entre les différentes années d’observations pour une même unité it ; eit = proportion de l’année t où la police d’assurance de l’assuré i
était en vigueur.
La vraisemblance de ce modèle de fréquence pour l’assuré i est alors exprimée par : LF,i=
∫
Pr (Ni1= ni1, . . . , NiTi = niTi|αλi) f (αλi) dαλi,
où f (αλi) = 1 σ√2π exp{− 1 2 ( αλi− µ σ )2 }.
Frees et Valdez ont supposé que les nombres Ni1, . . . , NiTi de demandes
d’indemni-sation sont indépendants étant donné αλi, ce qui implique que la probabilité conjointe des fréquences de réclamation de l’assuré i est donnée par :
Pr (Ni1 = ni1, . . . , NiTi = niTi|αλi) =
Ti
∏ t=1
Pr (Nit= nit|αλi) .
Pour l’ajustement de ce modèle, les covariables retenues par Frees et Valdez sont énumérées au tableau2.1. Les interactions entre certaines de ces covariables, ainsi que certaines relations non-linéaires, ont aussi été ajoutées au modèle. Après avoir examiné les données, Frees et Valdez se sont concentrés sur cinq modèles de prévision, soient :
– le modèle de Poisson sans covariable ; – le modèle de Poisson avec covariables ;
– le modèle de Poisson avec covariables et effets aléatoires ; – le modèle avec loi binomiale négative avec covariables ;
Tableau 2.1 – Covariables utilisées lors de l’ajustement des modèles pour la composante de la fréquence
Covariable Description
Année Années 1993 à 2001 inclusivement
Type de véhicule Le type de véhicule assuré, soit l’usage privé ou commercial Âge du véhicule Âge du véhicule groupé en 7 catégories
Sexe de l’assuré Homme ou femme
Âge de l’assuré Âge de l’assuré groupé en 7 catégories
NCD (No Claims Discount) Rabais basé sur les réclamations effectuées dans le passé par l’assuré. Si le rabais est élevé, cela signifie que l’assuré a effectué peu ou pas de réclamations dans le passé. Il s’agit d’une valeur continue.
Pour chaque modèle, les mêmes covariables ont été considérées afin de cerner le meilleur choix possible. Les auteurs ont utilisé le maximum de vraisemblance pour l’ajustement de chaque modèle, ainsi que la méthode de Bayes empirique pour la prévi-sion des effets aléatoires. Pour déterminer le modèle qui fournit les meilleures préviprévi-sions, Frees et Valdez ont opté pour le test de Pearson fondé sur la statistique du khi-deux. Ce test permet de comparer les valeurs réelles aux valeurs prédites du nombre de demandes d’indemnisation de chaque unité d’observation. Dans le cas des données de Singapour, le meilleur modèle était celui de la binomiale négative avec covariables. Les deux modèles comportant des effets aléatoires ont conduit aux pires prévisions.
2.2.2
Composante 2 : Type de réclamations effectuées lors des
demandes d’indemnisation
Lors de la discussion de la structure des données utilisées à la section 2.1, nous avons présenté les trois types de réclamations possibles, ainsi que les sept combinaisons susceptibles de se produire lors d’une demande d’indemnisation. Conditionnellement au fait que l’assuré effectue au moins une demande d’indemnisation durant l’année, la variable M représente la combinaison des types de réclamations observée dans chaque demande d’indemnisation. Les définitions de chaque type de réclamation et de chaque combinaison se trouvent respectivement aux tableaux 2.2 et2.3.
Frees et Valdez ont utilisé un modèle « logit » multinomial pour décrire la probabilité que la combinaison M soit présente lors de la prochaine demande d’indemnisation de
Tableau 2.2 – Combinaison possible de chaque type de réclamation
Valeur de M 1 2 3 4 5 6 7
Types de réclamations
C1 C2 C3 C1, C2 C1, C3 C2, C3 C1, C2, C3 impliquées
Tableau 2.3 – Définition de chaque type de réclamation
Paramètre Type de réclamation
C1 Montant des blessures à une tierce partie
C2 Montant des dommages subis par l’assuré, ce qui inclut les blessures de l’assuré, les dommages subis par le véhicule de l’assuré, l’incendie du véhicule, le vol du véhicule
C3 Montant des dommages subis par une propriété (véhicule, etc.) appartenant à une tierce partie.
l’assuré i durant l’année t. Afin d’inclure les covariables dans le modèle, les auteurs ont spécifié des probabilités de la forme suivante :
Pr (M = m) = ∑7exp (Vit,m) s=1exp (Vit,s)
, m = 1, . . . , 7,
où les covariables sont incluses via la variable Vit,m = x⊤itβM,m. Pour le jeu de don-nées de Singapour, Frees et Valdez ont jugé que les caractéristiques concernant l’assuré n’étaient pas des covariables significatives du modèle. Les seules covariables influentes étaient celles concernant les caractéristiques de l’automobile et l’année d’observation. Frees et Valdez ont aussi inclus différentes interactions entre ces variables. Ils ont di-chotomisé certaines covariables pour qu’elles soient plus faciles à traiter dans le modèle. Par exemple, ils ont remplacé l’année par la variable indicatrice « Year1996 » qui précise si l’année d’observation est antérieure ou postérieure à 1996.
Frees et Valdez ont choisi leurs covariables en fonction de maximiser la valeur de la log-vraisemblance du modèle ajusté. Ils sont venus à la conclusion que les covariables qui permettaient d’obtenir le meilleur ajustement étaient les trois suivantes :
– le type de véhicule assuré, soit l’usage privé ou commercial ;
– l’âge du véhicule assuré, dichotomisé selon que le véhicule est âgé de plus de deux ans ou non ;
2.2.3
Composante 3 : Sévérité des montants pour chaque type
de réclamation
Cette composante du modèle est la plus importante, car elle permet de prédire les montants pour chaque type de réclamation. Tout d’abord, Frees et Valdez ont obtenu un modèle marginal pour les trois types de réclamation. Ils ont ensuite testé différentes copules paramétriques afin de modéliser la dépendance entre les montants des trois types de réclamation.
Choix du modèle marginal
Pour chaque type de réclamation, les histogrammes des données de Singapour suggé-raient l’utilisation de distributions à queue lourde pour le montant de sévérité. Plusieurs types de distributions pour données non-négatives possèdent cette propriété. Frees et Valdez ont opté pour la distribution bêta généralisée de deuxième type, dont la fonction de densité est fC(c) = exp (α1z) c|σ|B (α1, α2) [1 + exp(z)] α1+α2, c≥ 0, où z = (ln c− µ) /σ et B (α1, α2) = Γ(α1)Γ(α2)/Γ(α1+ α2).
Dans ce modèle, µ est un paramètre de localisation et σ est un paramètre d’échelle, tandis que α1 et α2 sont des paramètres de forme. Les auteurs ont choisi cette distri-bution, car elle est fréquemment employée dans la littérature actuarielle. Ses quatre paramètres lui donnent une grande flexibilité pour l’ajustement de données où les va-leurs extrêmes sont plausibles.
Pour l’ajustement de cette fonction aux montants des réclamations de chaque type, Frees et Valdez ont décidé que seuls les paramètres d’échelle et de forme pourraient varier selon le type de réclamation. Afin d’inclure les covariables dans le modèle, le paramètre de localisation est défini de la façon suivante : µk= x⊤βC,k. La sélection des covariables pour chaque type de réclamation s’est faite indépendamment, c’est-à-dire que les covariables incluses dans un modèle marginal peuvent ne pas être retenues dans le modèle marginal d’un autre type de réclamation. L’estimation des paramètres a été faite à l’aide de la méthode du maximum de vraisemblance. Les auteurs ont utilisé des graphiques quantiles-quantiles afin de valider les modèles marginaux obtenus.
Dans le cas des réclamations pour les dommages à l’assuré (C2), il y a présence de censure (voir section 2.1). Dans le jeu de données de Singapour, 2 529 des 20 503 réclamations présentent des montants réclamés inférieurs à la franchise, ce qui induit une censure à zéro. Frees et Valdez ont donc fait appel à une vraisemblance qui tenait compte de la censure afin d’estimer les paramètres pour le modèle marginal de sévérité des dommages à l’assuré.
Choix de la copule
L’utilisation d’une copule paramétrique permet de modéliser la dépendance qui existe entre les montants lorsque plusieurs types de réclamation sont présents dans une demande d’indemnisation. La distribution conjointe entre les trois montants peut s’écrire de la façon suivante :
F (c1, c2, c3) = Pr(C1 ≤ c1, C2 ≤ c2, C3 ≤ c3)
= Pr (F1(C1)≤ F1(c1), F2(C2)≤ F2(c2), F3(C3)≤ F3(c3)) = H (F1(c1), F2(c2), F3(c3)) .
La loi marginale du montant Cj de chaque type de réclamation est dénotée Fj(·). La copule qui combine ces fonctions de répartition est H(·). Frees et Valdez se sont concentrés sur deux types de copules, soient la copule normale et celle de Student. Ils se sont intéressés à ces copules de façon particulière parce qu’elles font partie de la grande famille des copules elliptiques. Cette famille a la propriété intéressante d’être invariante par marginalisation, ce qui est un avantage lorsqu’on observe seulement une partie des variables marginales (Genest et Nešlehová,2010). Cette propriété était très importante pour leur analyse, car les copules normale et de Student peuvent être utilisées même lorsqu’un ou deux types de réclamations sont observés.
Frees et Valdez ont évalué la pertinence de modéliser la dépendance entre les mon-tants de chaque type de réclamation en confrontant les copules normale et de Student à la copule d’indépendance. Les vraisemblances de ces trois types de copules peuvent être comparées, car ces structures de dépendance sont emboîtées. En effet, quand la copule normale présente un paramètre de corrélation dont la valeur est nulle, elle devient alors la copule d’indépendance ; par ailleurs, la copule normale est un cas limite de la copule de Student correspondant au cas où le nombre de degrés de liberté tend vers l’infini. Les degrés de liberté de la copule de Student sont déterminés par la méthode du maximum de vraisemblance.
Suite aux différentes modélisations, Frees et Valdez ont conclu que l’utilisation d’une copule paramétrique était nécessaire, car les copules normale et de Student ont conduit à un accroissement significatif de la vraisemblance du modèle. Enfin, la comparaison des copules elliptiques entre elles a mené Frees et Valdez à privilégier la copule normale, car elle est plus pratique et permet néanmoins d’obtenir d’aussi bons résultats que la copule de Student.
Analyses préliminaires
3.1
Provenance des données
Les données utilisées pour nos analyses proviennent du registre des polices d’assu-rances souscrites en Ontario auprès d’une compagnie d’assud’assu-rances canadienne pendant la période s’étendant de 2003 à 2007. Il s’agit du même type de registre que la banque de données utilisée par Frees et Valdez, soient les polices d’assurance, les dossiers de réclamation et les dossiers d’indemnisation. Un total de 2 350 464 observations sont présentes dans le jeu de données pour l’ensemble des cinq années analysées.
3.1.1
Covariables préliminaires
À partir de la banque de données des polices d’assurance, une liste de covariables préliminaires a été établie afin de cibler les caractéristiques de l’assuré et du véhicule qui devaient être considérées dans nos modèles. Ce sont des informations qui sont ac-tuellement utilisées par la majorité des assureurs dans leur modèles respectifs. Cette liste est présentée au tableau3.1. Les modèles préliminaires ont tous été établis à partir des informations de cette liste. Pour les modèles complets, une vingtaine de covariables qui représentent d’autres caractéristiques de l’assuré viendront s’ajouter aux modèles préliminaires.
Tableau 3.1 – Covariables préliminaires à considérer dans le projet
Covariable Type de Description Valeurs possibles
Covariable
Age Nombre Entier Âge de la personne assurée 16 à 97 ans
Gender Dichotomique Sexe de la personne assurée Homme ou femme Cie Dichotomique Division auprès de laquelle 1 ou 2
l’assurance a été souscrite
Faq20 Catégorique Indique si l’assuré possède Non, oui, deluxe l’avenant concernant la location
d’une voiture de remplacement MaritalStatus Catégorique
Statut marital de l’assuré Célibataire, marié veuf ou divorcé NAP Nombre entier Nombre d’années de possession 0 à 78 ans
d’un permis
NBVT Nombre entier Nombre de véhicules assurés 1 à 4 par cette police d’assurance
Kmpleasure Valeur continue Kilométrage effectué par 0 à 99 999 km l’assuré durant l’année
Categmod Catégorique Catégorie du véhicule assuré 20 possibilités : Compact, VUS, etc. Vehage Nombre Entier Âge du véhicule assuré 0 à 77 ans
3.1.2
Variables dépendantes d’intérêt
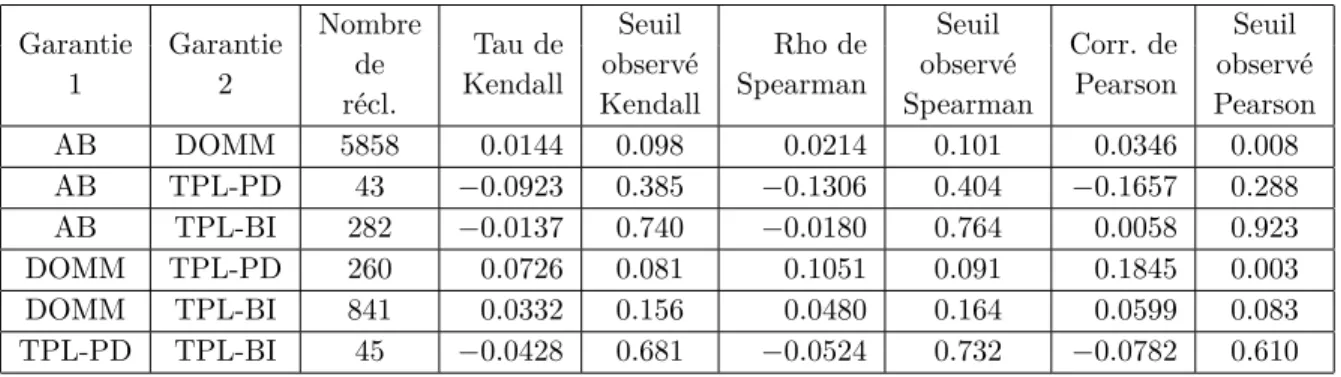
Dans ce projet, deux types de variables dépendantes nous intéressent. Il s’agit d’une part de la sévérité des montants qui sont déboursés par la compagnie d’assurances pour le remboursement des demandes d’indemnisation et d’autre part, de la fréquence relative de chaque type de garantie sur l’ensemble des demandes d’indemnisations. Pour chaque accident signalé, il peut y avoir un remboursement pour cinq types de garanties différentes. Ces garanties sont présentées au tableau 3.2.
Dans la pratique, le montant associé à certaines de ces garanties est connu très rapidement, alors que d’autres ne sont connus qu’au terme d’un processus judiciaire qui détermine le coût du règlement. Pour DCPD et COLL, à savoir les garanties relatives aux dommages matériels du véhicule assuré, le montant est fixé suite à la réparation ou au remplacement du véhicule accidenté. L’assureur dispose donc rapidement de cette information. Cependant, la valeur totale de l’indemnité pour la garantie AB, relative
Tableau 3.2 – Explication des garanties considérées
Garantie Abréviation Obligatoire Description Direct Compensation
DCPD
Dommages matériels
Property Damage Oui subis par la voiture de l’assuré pour la proportion non-responsable
Collision COLL
Dommages matériels
Non subis par la voiture de l’assuré pour la proportion responsable Accident Benefit AB Oui Dommages corporels à l’assuré
et aux victimes non-couvertes par AB Third Party Liabilities
TPL-PD Oui
Dommages matériels à autrui
Property Damage pour les situations où
DCPD ne s’applique pas
TPL-BI Oui
Dommages corporels à des victimes Third Party Liabilities non-responsables de l’accident autres
Body Injury que l’assuré pour la portion
au-delà du seuil non-couvert par AB
aux blessures subies par l’assuré, ne sera connue que suite au rétablissement complet de l’assuré. Celle-ci comprend le remboursement des frais engendrés par les soins, le remplacement de salaire, etc. De plus, la garantie AB indemnise les personnes impliquées dans l’accident qui n’étaient pas assurées par une police valide au moment de l’accident. Cela contribue à augmenter l’indemnité déboursée.
Finalement, les montants des deux garanties TPL, relatives aux dommages subis par autrui, ne sont généralement connus qu’à la suite d’un jugement de cour. En Ontario, les personnes impliquées dans un accident ont la possibilité de poursuivre le responsable de l’accident lorsqu’elles considèrent ne pas avoir été indemnisées à une juste valeur. Seule une minorité de ces situations se règle hors cours par une entente entre l’assureur et le requérant. Comme les procédures judiciaires sont généralement longues, le règlement final n’est connu que quelques années après l’accident. Les montants de ces garanties dé-pendent de plusieurs facteurs externes aléatoires qui peuvent avoir une grande influence sur le débours final. Par exemple, si l’auteur de ces lignes entrait en collision avec la Maserati de Pierre-Karl Péladeau, il y a de fortes chances que le montant réclamé soit plus élevé que s’il s’agissait d’une Honda Civic d’un étudiant de 20 ans.
Dans un autre constat beaucoup plus technique, si un jugement de cour devait at-tribuer un montant d’assurance plus élevé que le maximum applicable pour la garantie AB, l’assuré pourrait alors réclamer la valeur excédentaire sur la garantie TPL.
Toute-fois, comme on ne connaît pas le plafond applicable à la garantie AB de chaque assuré, il est impossible d’identifier les observations qui présentent cette particularité. Il est fort probable que les hauts montants de AB qui sont accompagnés d’une valeur non nulle pour TPL proviennent d’une telle situation. De plus, une autre particularité du jeu de données est que pour la garantie AB, les montants de sévérité sont écrêtés à 82 000 $, alors que pour les deux garanties TPL, ils sont écrêtés à 100 000 $. Par écrêtement, on entend que si le montant réclamé excède une certaine valeur, par exemple 82 000 $ pour la garantie AB, sa valeur est automatiquement remplacée dans la base de données par le plafond allouable, soit 82 000 $. Nous avons pris cette mesure afin d’éviter que les accidents catastrophiques viennent influencer indûment l’ajustement des modèles.
Pour chaque demande de remboursement, on connaît le montant réclamé pour cha-cune des cinq garanties admissibles. Il est toutefois important de noter que contraire-ment aux quatre autres, la garantie Collision est facultative. Cette garantie, dénotée COLL, indemnise l’assuré pour les dommages matériels à son véhicule lorsque l’assuré est responsable de l’accident. Il y a donc deux sous-populations dans la banque de don-nées : les gens souscrits à COLL et les gens qui ne le sont pas. Ceci peut présenter un problème si on veut connaître le total des dommages matériels subis par l’assuré pour la sous-population des assurés qui ne sont pas souscrits à COLL. En effet, lors-qu’ils subissent un accident dont ils sont responsables, ces assurés ne feront pas de demande d’indemnisation car ils ne sont pas assurés pour les dommages matériels de leur véhicule. Ainsi, la compagnie d’assurances ne sera pas en mesure de connaître cette information qui est essentielle à l’ajustement des modèles. Pour éviter cette situation, seule la sous-population qui a souscrit à COLL sera considérée dans la modélisation. Cette sous-population génère 80 % des observations disponibles dans la base de don-nées. Il est à noter que Frees et Valdez ont fait face au même type de problèmes et ont eux aussi opté pour cette approche.
De plus, pour faciliter l’étude de la dépendance entre les garanties, une nouvelle variable a été créée à partir des garanties DCPD et COLL. Cette nouvelle garantie, nommée DOMM, est la somme des montants réclamés pour DCPD et COLL. Cette ga-rantie DOMM représente donc le montant total des dommages subis par le véhicule de l’assuré, peu importe si l’assuré est responsable ou non de l’accident. De plus, une cor-rection est nécessaire afin de bien représenter le montant total des dommages subis par le véhicule de l’assuré. Lors d’une réclamation où le client est responsable de l’accident, celui-ci doit débourser une franchise sur les montants des dommages matériels réclamés pour sa voiture, alors qu’il ne paye pas cette franchise lorsqu’il n’est pas responsable.
Par exemple, un assuré subit un accident où sa voiture nécessite 2500 $ en répara-tions. S’il est responsable, l’assuré devra assumer la franchise mentionnée sur sa police
d’assurance, par exemple, 1000 $, et l’assureur défrayera les 1500 $ supplémentaires. S’il n’est pas responsable, l’assuré pourra alors réclamer les 2500 $ en totalité à l’assu-reur. Afin que les montants soient homogènes entre DCPD et COLL pour une même observation, la franchise payée par le client est automatiquement ajoutée au montant réclamé sur la garantie DCPD.
Un autre paramètre qu’il est très important de considérer est la fréquence relative d’une demande de remboursement pour une garantie donnée. Sans cette fréquence, il est impossible de bien quantifier le montant total qui sera réclamé par une population donnée dans les prochaines années. Les fréquences pour chaque garantie sont définies comme le rapport du nombre de montants réclamés supérieurs à zéro sur le nombre total de demandes d’indemnisation.
3.1.3
Utilisation de la fréquence des demandes
d’indemnisa-tion
Une troisième variable d’intérêt pour compléter le modèle présenté par Frees et Valdez est le nombre de demandes d’indemnisation effectuées par année pour chaque assuré. Cette variable était modélisée par une loi binomiale négative dans la première composante de la structure de Frees et Valdez. Toutefois, dans notre jeu de données, il était difficile de cerner le nombre exact de demandes d’indemnisation pour chaque assuré à chaque année. Même si les données peuvent être regroupées par numéro de police d’assurance, il se peut que plusieurs personnes d’une même famille soient couvertes par une même police. Par exemple, les conducteurs occasionnels des véhicules assurés sont indiqués dans la police d’assurance, mais la banque de données fournie par l’assureur ne permet pas de retracer quel conducteur a subi l’accident menant à la demande d’indemnisation. De plus, les résultats obtenus suggèrent que le nombre de demandes dépasse rarement deux pour un assuré donné dans une même année. Pour ces diverses raisons, cette étape n’a pas été incluse dans la modélisation. On s’est plutôt concentré sur la dépendance qui existe entre les sévérités et les fréquences relatives des différentes garanties.
3.1.4
Autres détails sur le jeu de données
Suite à diverses consultations avec des actuaires associés au projet, certaines autres modifications ont été effectuées à la banque de données initiale. Tout d’abord, seuls les accidents impliquant deux véhicules ou plus ont été considérés dans les modèles.
La raison pour laquelle les accidents à un seul véhicule ont été éliminés provient tout simplement de la définition des garanties utilisées. Pour les accidents à un seul véhicule, les types de réclamation qui sont faites pour les dommages matériels à autrui sont des dommages mineurs, tels un panneau routier, une clôture, un poteau électrique, et certains dommages majeurs, tels une maison ou tout autre bâtiment endommagé par l’accident. Dans un accident à deux véhicules, les réclamations effectuées pour les dommages à autrui concerneront en majorité des dommages matériels aux autres véhicules impliqués dans l’accident. Les montants sont donc plus homogènes pour les accidents à deux véhicules. La même situation se produit pour les dommages corporels à autrui. Lorsqu’il s’agit d’un accident à un seul véhicule, il peut y avoir une demande de réclamation pour dommages corporels à autrui dans les situations suivantes :
– les blessures infligées à un piéton impliqué dans l’accident,
– les blessures infligées à une personne se trouvant dans la voiture de l’assuré, mais qui ne réside pas à la même adresse.
Encore une fois, les montants pour ces blessures sont très volatiles, notamment dans le cas où un piéton est impliqué. Le fait de se restreindre aux accidents à deux véhicules permet d’éviter la majorité de ces situations.
3.1.5
Logiciel utilisé pour le projet
L’ensemble des analyses du projet ont été réalisées au moyen du logiciel R (R De-velopment Core Team, 2010). Ce logiciel permet de télécharger une multitude d’outils afin de mettre en œuvre la majorité des applications statistiques existantes à ce jour. De plus, des mises à jour qui apportent des améliorations aux outils existants ou qui implantent de nouveaux outils sont souvent disponibles. R permet aussi d’échanger des bases de données facilement avec d’autres logiciels, comme Excel, et il permet de trans-férer des résultats d’analyses vers d’autres logiciels mieux adaptés à certaines tâches. Par exemple, dans le cas d’inférences bayésiennes, le logiciel R permet d’interagir avec le logiciel WinBUGS qui est mieux adapté pour ce type d’analyse.
Toutefois, R souffre de certaines lacunes. Comme il s’agit d’un logiciel gratuit, cer-tains outils importés par d’autres utilisateurs peuvent contenir des erreurs de code susceptibles de fausser les analyses. Il faut donc s’assurer que l’outil utilisé est fiable en vérifiant sa provenance. La majorité des programmes proviennent de statisticiens expérimentés, ce qui permet de croire que ces outils sont fiables. Certains pourront aussi critiquer la documentation minimale fournie par R, ainsi que son interface peu développée, alors que SAS présente un logiciel très élaboré et documenté. Malgré tout,
ces dernières années, les chercheurs ont eu tendance à migrer vers R, grâce notamment à la facilité d’y intégrer des techniques d’analyses modernes, ainsi qu’à sa gratuité.
3.2
Analyses préliminaires de la dépendance
Une des lacunes du modèle présenté par Frees et Valdez était l’absence d’une éven-tuelle corrélation entre la sévérité et la fréquence d’une garantie. Dans les analyses préliminaires de ce projet, quatre types de dépendance ont été évalués :
1. dépendance entre les sévérités ; 2. dépendance entre les fréquences ;
3. dépendance de la fréquence étant donné la sévérité ; 4. dépendance de la sévérité étant donné la fréquence.
Frees et Valdez ont concentré leurs efforts sur un modèle dont la dépendance entre les sévérités (Item 1) était modélisée par une copule et la dépendance entre les fréquences (Item 2) par un modèle multinomial. Toutefois, les deux derniers types d’association n’ont pas été considérés. Logiquement, on s’attend à ce que la sévérité des dommages matériels du véhicule accidenté ait une influence sur la fréquence d’une demande de réclamation pour des blessures corporelles. Aussi, la présence d’une demande de récla-mation pour dommages corporels à l’assuré peut avoir une influence sur la sévérité du montant réclamé pour les dommages corporels à autrui, spécialement dans le cas d’un accident à plusieurs véhicules.
Appelons Ci,k, le montant de sévérité de chaque garantie, k = 1,. . .,4, pour la demande d’indemnisation i. Les types de réclamation pour chaque observation sont connus, ce qui permet de déduire la présence ou l’absence de chaque garantie pour chaque observation. L’indicatrice de cette information est dénotée Pi,k, k = 1,. . .,4, pour la demande d’indemnisation i. Pi,k prend la valeur 1 lorsqu’une réclamation pour la garantie k est présente pour l’observation i, et la valeur 0 sinon.
3.2.1
Modélisation de la dépendance entre les sévérités
Tout d’abord, on cherche à mesurer la dépendance entre les montants de sévérité, traités comme des variables continues. Dans le cas de la garantie AB, les montants sont
écrêtés à 82 000 $ et pour les deux garanties TPL, ils sont écrêtés à 100 000 $. Comme on travaille sur des valeurs continues, des mesures de corrélation sont évaluées deux à deux entre les sévérités des quatre garanties lorsque les montants engendrés pour un même accident sont différents de zéro. Trois différentes mesures de corrélation ont été utilisées, soient le coefficient de corrélation de Pearson, le tau de Kendall, ainsi que le rho de Spearman. De plus, des graphiques de rangs ont été effectués afin de déceler une dépendance susceptible de justifier l’utilisation d’une copule pour l’ajustement des modèles de sévérité.
Considérons un échantillon (X1, Y1), . . . , (Xn, Yn) de la paire (X, Y ), deux variables aléatoires continues et posons ¯X = (X1+· · · + Xn)/n et ¯Y = (Y1+· · · + Yn)/n. Voici les formules empiriques permettant de calculer les différentes mesures de corrélation sur ces vecteurs :
Coefficient de corrélation de Pearson :
rn(X, Y ) = 1 n n ∑ i=1 (X√i − ¯X)(Yi− ¯Y ) d Var(X)Var(Y )d ,
où n représente le nombre de valeurs présentes dans un vecteur, et d Var(X) = 1 n n ∑ i=1 (xi− ¯x)2 et d Var(Y ) = 1 n n ∑ i=1 (yi− ¯y)2. Rho de Spearman : ρ = 1− 6 n(n2− 1) n ∑ i=1 (Ri− Si),
où (R1, S1), . . . , (Rn, Sn) représentent les paires de rangs associées à l’échantillon. Tau de Kendall :
τ = (Nombre de paires concordantes)1 − (Nombre de paires discordantes) 2n(n− 1)
,
où deux paires (Xi, Yi), (Xj, Yj) sont dites concordantes si et seulement si (Xi−Xj)(Yi− Yj)≥ 0, alors qu’elles sont dites discordantes lorsque (Xi− Xj)(Yi− Yj) < 0.
Le coefficient de corrélation de Pearson est l’une des mesures les plus anciennes de dépendance entre deux variables continues. Bien que ce coefficient mesure correctement la dépendance linéaire, il ne détecte pas efficacement les autres types de corrélation. Dans certains cas où une forte association est présente, le coefficient de corrélation de Pearson peut se trouver très près de zéro, ce qui suggèrerait l’indépendance entre les deux variables étudiées. Afin de pallier ces importants défauts, de nouvelles mesures de dépendance ont été introduites suivant les axiomes suggérés parScarsini (1984).
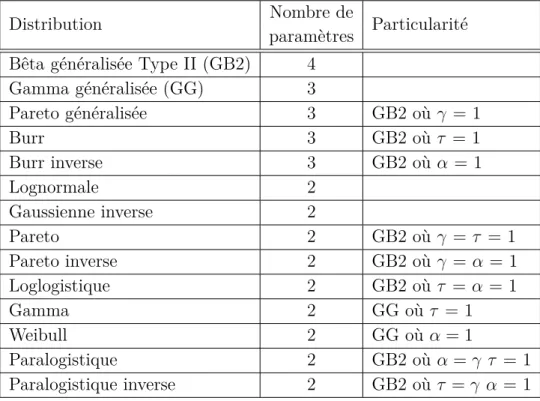
Le rho de Spearman et le tau de Kendall sont deux mesures respectant ces axiomes. Ces coefficients, qui sont largement employés dans la littérature, utilisent les rangs des données des deux vecteurs afin de mesurer la dépendance. Ce sont d’ailleurs les mesures qui sont les plus souvent considérées afin de juger de la pertinence d’utiliser une copule lors d’une modélisation conjointe de deux variables continues. Les résultats de l’application de ces mesures à nos données sont présentés au tableau 3.3.
Tableau 3.3 – Mesures de dépendance entre les sévérités des garanties
Garantie Garantie Nombre Tau de Seuil Rho de Seuil Corr. de Seuil 1 2 de Kendall observé Spearman observé Pearson observé
récl. Kendall Spearman Pearson
AB DOMM 5858 0.0144 0.098 0.0214 0.101 0.0346 0.008 AB TPL-PD 43 −0.0923 0.385 −0.1306 0.404 −0.1657 0.288 AB TPL-BI 282 −0.0137 0.740 −0.0180 0.764 0.0058 0.923 DOMM TPL-PD 260 0.0726 0.081 0.1051 0.091 0.1845 0.003 DOMM TPL-BI 841 0.0332 0.156 0.0480 0.164 0.0599 0.083 TPL-PD TPL-BI 45 −0.0428 0.681 −0.0524 0.732 −0.0782 0.610
Les seuils observés sont obtenus à partir d’un test bilatéral d’indépendance entre les deux variables étudiées. Les distributions asymptotiques pour chaque mesure sous l’hypothèse nulle de l’indépendance entre les deux variables sont :
Tau de Kendall : τn ≈ N ( 0, 2(2n + 5) 9n(n− 1) ) Rho de Spearman : ρn ≈ N ( 0, 1 n− 1 ) Corrélation de Pearson : r√n√n−2 1−r2 n ≈ t(n−2)
En examinant le tableau 3.3, on remarque que les deux mesures de dépendance ba-sées sur les rangs suggèrent l’absence d’une dépendance entre les sévérités des différentes garanties. Pour le coefficient de corrélation de Pearson, on remarque deux paires de ga-ranties qui ont une dépendance significative. Toutefois, lorsqu’on observe les graphiques de rangs pour ces deux paires de garanties (A.1etA.2), aucune tendance n’est détectée. Cela nous permet d’affirmer qu’une copule ne sera pas nécessaire dans la modélisation des différentes garanties, contrairement au cas considéré par Frees et Valdez.
3.2.2
Modélisation de la dépendance entre les fréquences
À ce stade-ci, la dépendance est mesurée entre les fréquences des quatre variables d’intérêt afin d’en connaître l’importance. À cette fin, des tests sur les rapports de cotes calculés sur les différentes fréquences ont été utilisés. Par exemple, le rapport de cotes qui évalue la dépendance entre la proportion de réclamations AB et la proportion de réclamations DOMM sa calcule ainsi :
Proportion de réclamations AB = p = 1 n n ∑ i=1 Pi,AB
Proportion de réclamations DOMM = q = 1 n n ∑ i=1 Pi,DOM M Rapport de cotes = p/(1− p) q/(1− q)
S’il y a indépendance entre les deux fréquences, la valeur obtenue pour le rapport de cotes sera proche de 1. Comme tous les accidents comprennent une réclamation de dommages matériels pour le véhicule assuré (DOMM), cette garantie n’a pas été incluse dans les calculs, car sa fréquence est égale à 1 ; les autres garanties n’ont donc aucune influence sur cette fréquence. Un test d’indépendance a été effectué par la méthode de Wald qui utilise une approximation normale. Les résultats de ces comparaisons se trouvent au tableau3.4.
Les seuils observés des tests sont tous inférieurs à 5%, ce qui nous confirme que la fréquence d’une garantie a une influence significative sur la fréquence d’une autre garantie. Le modèle qui sera utilisé dans ce projet doit donc inclure une composante qui pourra tenir compte de cette corrélation. À l’instar de Frees et Valdez, cette composante peut être représentée par un modèle multinomial.
Tableau 3.4 – Tests sur les rapports de cotes
Garantie 1 Garantie 2 Rapport de cotes Intervalle de confiance Seuil observé Borne Inf. Borne Sup.
TPL-BI TPL-PD 12.9156 9.1838 17.7738 0.00000
AB TPL-BI 3.9250 3.3867 4.5390 0.00000
AB TPL-PD 1.5039 1.0687 2.0662 0.01975
3.2.3
Modélisation de la fréquence étant donné la sévérité
Dans cette section, on considère l’un des deux types de dépendance qui n’étaient pas pris en compte dans le modèle de Frees et Valdez. L’objectif est de vérifier si la sévérité d’un type de garantie a un impact sur la présence ou l’absence d’une réclamation pour d’autres types de garantie dans l’accident. Dans un accident à deux véhicules, la sévérité des dommages matériels au véhicule de l’assuré devrait avoir une influence sur la présence d’une réclamation pour les blessures corporelles de l’assuré, ainsi que la présence d’une réclamation pour les dommages subis par autrui.
Le tableau 3.5 permet de connaître la moyenne des montants consentis en fonction des garanties réclamées dans un accident. On constate en premier lieu que le montant des dommages matériels augmente lorsque le nombre de garanties impliquées dans un accident augmente. Le montant de DOMM pourrait donc servir à prédire la présence ou l’absence des autres garanties. De plus, d’un point de vue pratique, c’est généra-lement ce montant qui est connu en premier par l’assureur ; dans l’implantation d’un modèle hiérarchique, ce montant pourrait donc être utilisé afin de prédire la suite des évènements. On remarque ensuite que le montant réclamé pour les blessures corporelles à l’assuré est plus élevé en présence d’une réclamation pour le montant des blessures corporelles à autrui, ce qui signifie que la présence d’une réclamation pour la garantie BI pourrait avoir un impact sur le montant réclamé pour la garantie AB.
Afin de vérifier l’hypothèse à l’effet que le montant des dommages matériels a une influence sur la présence d’une demande de réclamation pour les autres garanties, trois régressions logistiques ont été effectuées. Par exemple, pour l’effet sur la présence de blessures corporelles à l’assuré, on ajuste le modèle de régression logistique suivant :
Tableau 3.5 – Moyenne des montants de chaque garantie selon le type de garanties réclamées lors d’un même accident
Type Nombre de AB TPL-BI DOMM TPL-PD Moyenne Moyenne Moyenne Moyenne
réclamations AB TPL-BI DOMM TPL-PD
4 15 Oui Oui Oui Oui 16 726 35 814 13 443 2637
3 28 Oui Non Oui Oui 14 835 0 11 010 3182
3 265 Oui Oui Oui Non 29 698 52 230 9870 0
3 0 Oui Oui Non Oui N/A N/A 0 N/A
3 30 Non Oui Oui Oui 0 40 856 10 398 5461
2 5508 Oui Non Oui Non 14 659 0 6243 0
2 0 Oui Non Non Oui N/A 0 0 N/A
2 0 Oui Oui Non Non N/A N/A 0 0
2 186 Non Non Oui Oui 0 0 6660 3944
2 526 Non Oui Oui Non 0 53 564 6974 0
2 0 Non Oui Non Oui 0 N/A 0 N/A
1 0 Oui Non Non Non N/A 0 0 0
1 0 Non Oui Non Non 0 N/A 0 0
1 42 951 Non Non Oui Non 0 0 3736 0
1 0 Non Non Non Oui 0 0 0 N/A
Note : « Oui » et « Non » dénotent respectivement la présence et l’absence d’une récla-mation de ce type de garantie.
Les résultats de cette modélisation pour la présence d’une réclamation de AB se trouvent au tableau 3.6. Le seuil observé pour l’effet du montant de dommages ma-tériels est nettement inférieur à 5%. Comme le coefficient est positif, cela indique que plus le montant augmente, plus la probabilité qu’une réclamation pour AB soit effec-tuée s’accroît. L’hypothèse d’une influence des montants de dommages matériels sur la présence des autres garanties est aussi confirmée par les analyses faites sur TPL-BI et TPL-PD dont les résultats se trouvent aux tableauxA.1 et A.2.
Tableau 3.6 – Estimation des paramètres de la régression logistique de la fréquence de la garantie AB en fonction du montant de dommages matériels DOMM
Paramètres Estimation Erreur Valeur Seuil
Standard Z observé
Ordonnée à l’origine −2.552 0.021 −123.39 <2e-16 Montant DOMM 1.11E-04 2.77E-06 40.08 <2e-16
3.2.4
Modélisation de la sévérité étant donné la fréquence
Cette section présente le deuxième type de dépendance qui n’était pas considéré par Frees et Valdez. Toutefois, il s’agit d’une association qui est étroitement liée à celle de la
sous-section précédente. Comme il a été démontré que la sévérité a une influence sur la présence d’une réclamation pour une autre garantie, il est logique que la présence d’une réclamation pour une garantie ait une influence sur la sévérité d’une autre garantie.
Afin de vérifier cette hypothèse, une analyse de la variance a été effectuée avec la sévérité de chacune des garanties comme variable réponse. Dans chaque analyse de la variance, les indicateurs de la présence de chacune des autres garanties sont les facteurs fixes inclus dans le modèle. De plus, les interactions doubles ont été incluses dans chaque modèle.
Voici l’équation du modèle pour la sévérité de AB :
Ci,AB = µ + α1Pi,P D+ α2Pi,BI+ α12Pi,BIPi,P D+ ei, où
µ = Moyenne générale,
α1 = Effet de la présence de la garantie TPL-PD, α2 = Effet de la présence de la garantie TPL-BI,
α12 = Effet de l’interaction de la présence de la garantie TPL-PD et de la garantie TPL-BI,
ei = Terme d’erreur du modèle où ei ∼ N (0, σ2).
Pour chaque analyse, une transformation de la variable réponse a été nécessaire afin que les modèles puissent respecter les postulats d’une analyse de la variance. Dans chaque cas, la méthode de Box–Cox a été effectuée afin de trouver la transformation adéquate. Lorsque celle-ci ne permettait pas de respecter les postulats, une analyse non paramétrique sur les rangs a été effectuée afin de valider les résultats.
Tableau 3.7 – Effets significatifs de la fréquence des garanties sur le montant de dom-mages AB par une analyse de la variance
Effets Degrés de liberté Valeur Seuil Numérateur Dénominateur F observé
TPL-BI 1 5812 0.04 0.8321
TPL-PD 1 5812 3.13 0.0769