Measuring Public Opinion Using Big Data: Applications
in Computational Social Sciences
Thèse
Mickael Temporao
Doctorat en science politique
Philosophiæ doctor (Ph. D.)
Measuring Public Opinion Using Big Data
Applications in Computational Social Sciences
Thèse
Mickael Temporão
Sous la direction de:
François Gélineau, directeur de recherche Thierry Giasson, co-directeur de recherche
Résumé
La démocratie est fondée sur l’idée que les gouvernements sont sensibles à l’opinion des citoyens qu’ils sont élus pour représenter. Des mesures fiables de l’opinion pu-blique sont requises afin de permettre aux élus de gouverner de manière efficace. Les sources traditionnelles d’information sur l’opinion publique se complexifient avec l’accroissement des modalités de communication et les changements culturels qui y sont associés. La diversification des technologies de l’information et de la com-munication ainsi que la forte baisse des taux de réponse aux enquêtes de sondages provoquent une crise de confiance dans les méthodes d’échantillonnage probabiliste classique. Une source d’information sur l’opinion publique de plus en plus riche, mais relativement peu exploitée, se présente sous la forme d’ensembles de données extraordinairement volumineuses et complexes, communément appelées Big Data. Ces données présentent de nombreux défis liés à l’inférence statistique, notamment parce qu’elles prennent généralement la forme d’échantillons non probabilistes. En combinant des avancées récentes en sciences sociales numériques, en statistiques et en technologie de l’information, cette thèse, constituée de trois articles, aborde cer-tains de ces défis en développant de nouvelles approches, permettant l’extraction d’informations adaptées aux larges ensembles de données. Ces nouvelles approches permettent d’étudier l’opinion publique sous de nouveaux angles et ainsi de contri-buer à des débats théoriques importants dans la littérature sur la recherche sur l’opinion publique en rassemblant les preuves empiriques nécessaires afin de tes-ter des théories de la science politique qui n’avaient pas pu être abordées, jusqu’à présent, en raison du manque des données. Dans le premier article, sur le placement idéologique des utilisateurs sur les médias sociaux, nous développons un modèle permettant de prédire l’idéologie et l’intention de vote des utilisateurs sur les mé-dias sociaux en se basant sur le jargon qu’ils emploient dans leurs interactions sur les plateformes de médias sociaux. Dans le second article, sur l’identité nationale au Canada, nous présentons une approche permettant d’étudier l’hétérogénéité de
l’identité nationale en explorant la variance de l’attachement à des symboles natio-naux parmi les citoyens à partir de données provenant d’un vaste sondage en ligne. Dans le troisième article portant sur les prédictions électorales, nous introduisons une approche se basant sur le concept de la sagesse des foules, qui facilite l’utilisation de données à grande échelle dans le contexte d’études électorales non-aléatoires afin de corriger les biais de sélection inhérents à de tels échantillons. Chacune de ces études améliore notre compréhension collective sur la manière dont les sciences so-ciales numériques peuvent accroître notre connaissance théorique des dynamiques de l’opinion publique et du comportement politique.
Abstract
Democracy is predicated on the idea that governments are responsive to the publics which they are elected to represent. In order for elected representatives to govern effectively, they require reliable measures of public opinion. Traditional sources of public opinion research are increasingly complicated by the expanding modalities of communication and accompanying cultural shifts. Diversification of information and communication technologies as well as a steep decline in survey response rates is producing a crisis of confidence in conventional probability sampling. An increa-singly rich, yet relatively untapped, source of public opinion takes the form of extra-ordinarily large, complex datasets commonly referred to as Big Data. These datasets present numerous challenges for statistical inference, not least of which is that they typically take the form of non-probability sample. By combining recent advances in social science, computer science, statistics, and information technology, this thesis, which combines three distinct articles, addresses some of these challenges by deve-loping new and scalable approaches to facilitate the extraction of valuable insights from Big Data. In so doing, it introduces novel approaches to study public opinion and contributes to important theoretical debates within the literature on public opi-nion research by marshalling the empirical evidence necessary to test theories in political science that were previously unaddressed due to data scarcity. In our first article, Ideological scaling of social media users, we develop a model that predicts the ideology and vote intention of social media users by virtue of the vernacular that they employ in their interactions on social media platforms. In our second article, The symbolic mosaic, we draw from a large online panel survey in Canada to make inferences about the heterogeneous construction of national identities by exploring variance in the attachment to symbols among various publics. Finally, in our third article, Crowdsourcing the vote, we endeavour to draw on the wisdom of the crowd in large, non-random election studies as part of an effort to control for the selection bias inherent to such samples. Each of these studies makes a contribution to our
col-lective understanding of how computational social science can advance theoretical knowledge of the dynamics of public opinion and political behaviour.
Contents
Résumé iii Abstract v Contents vii List of Tables ix List of Figures x Acknowledgments xiii Foreword xvi Introduction 1 0.1 Introduction . . . 10.2 The measurement of public opinion . . . 5
0.3 Modern Data and Methods. . . 8
0.4 Organization and Overview . . . 16
0.5 Bibliography . . . 22
1 Ideological Scaling of Social Media Users: A Dynamic Lexicon Approach 32 1.1 Résumé . . . 33
1.2 Abstract. . . 34
1.3 Introduction . . . 35
1.4 Deriving ideological scales from social media text . . . 37
1.5 Data . . . 42
1.6 Results And Validation . . . 44
1.7 Validating ideological estimates using voting intention . . . 51
1.8 Conclusion and Discussion. . . 55
1.9 Bibliography . . . 58
2 The Symbolic Mosaic:
An Empirical Typology of National Symbolic Webs and its Effect on
2.1 Résumé . . . 63
2.2 Abstract. . . 64
2.3 Introduction . . . 65
2.4 Canadian Nationalists and Their Symbols . . . 67
2.5 Data and method . . . 71
2.6 Results . . . 72
2.7 Conclusion . . . 78
2.8 Bibliography . . . 81
3 Crowdsourcing the Vote: New Horizons in Citizen Forecasting 85 3.1 Résumé . . . 86
3.2 Abstract. . . 87
3.3 Introduction . . . 88
3.4 Election Forecasting . . . 89
3.5 The Canadian context . . . 92
3.6 Data and Measurement . . . 94
3.7 Can Canadian Citizens Predict? . . . 97
3.8 Discussion . . . 102
3.9 Bibliography . . . 106
Conclusion 109 3.10 Introduction . . . 109
3.11 Motivation and Contributions . . . 110
3.12 Ethical Considerations and Limitations. . . 116
3.13 Future Research . . . 119
3.14 Bibliography . . . 122
A Ideological Scaling of Social Media Users: Supplementary Materials 124 A.1 Generating Network Ideologies . . . 124
A.2 N-gram Optimization . . . 124
A.3 Citizens’ Bigram Threshold Filtering . . . 127
A.4 Machine Learning Classification Task Setup . . . 127
List of Tables
1.1 Citizens – Assessment of the dynamic lexicon approach for citizens . . 50
2.1 Canadian National Symbols . . . 71
3.1 A General Overview of the Ten Canadian Elections . . . 93
B.1 Predictors of National Symbolic Webs Types . . . 132
List of Figures
0.1 Decline in response rates to Pew surveys, 1997–2012 . . . 6
1.1 Political candidates – Comparison of estimated positions for the ref-erence method (network scaling approach) and the dynamic lexicon approach . . . 48
1.2 Citizens – Assessing linear combinations of textual and network ide-ologies . . . 51
1.3 Venn diagram illustrating the complementarity between the ideology estimates to predicting voting intentions of citizens . . . 53
1.4 Comparison at the party level of citizens’ Twitter and Survey predic-tion efficiencies . . . 54
2.1 Relative Pride In Canadian Symbols . . . 73
2.2 Four Types of National Symbolic Webs . . . 74
2.3 The Four Types’ Relative Pride In Canadian Symbols . . . 76
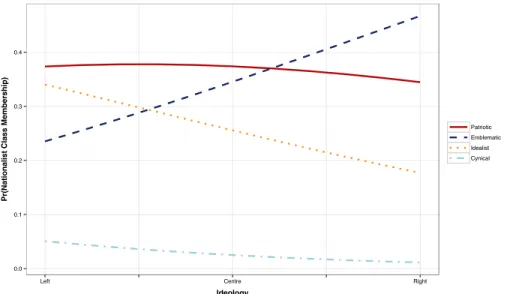
2.3 The Effect of Left-Right Ideology on National Symbolic Web Member-ship . . . 77
3.1 Two Families of Election Prediction Models . . . 90
3.2 Surveying Voter Expectations . . . 96
3.3 Citizen Forecasts: Canada Compared to the UK and US . . . 98
3.4 Vote Intentions vs. Voter Expectations . . . 99
3.5 Comparison with swing ratio model . . . 100
3.6 Citizen forecasts (last 5 days prior to election) . . . 101
3.7 Forecasts as a function of self-assessed competence . . . 102
3.8 Vote Intentions vs. Voter Expectations . . . 103
A.1 Political candidates – Comparing the performance of the dynamic lex-icon approach for unigrams, bigrams and trigrams dictionaries . . . . 126
A.2 Validity of the dynamic lexicon estimates compared to filtering condi-tions . . . 126
A.3 Evolution of the quality of citizens’ estimates compared to the bigram threshold filter (ξ) . . . 128
Alone we can do so little. Helen Keller
Remerciements
Cette thèse est le résultat du soutien, de la motivation et de l’inspiration que j’ai reçu des nombreuses personnes que j’ai eu la chance de rencontrer durant cette fantas-tique aventure académique. J’aimerais remercier toutes ces personnes qui pendant ces cinq années ont fait de moi le chercheur passionné que je suis aujourd’hui. Sans vous, cette thèse n’existerait pas.
Ma gratitude et mes remerciements vont tout d’abord à mes deux directeurs, François Gélineau et Thierry Giasson, qui m’ont pris sous leur aile dès mon arrivée à Québec. Tout au long de cette aventure, vous m’avez apporté les meilleurs conseils et op-portunités qu’un étudiant au doctorat puisse espérer. Grâce à vous, j’ai pu intégrer différentes chaires de recherche où j’ai eu, non seulement, la chance de découvrir le milieu passionnant de la recherche universitaire, mais aussi rencontrer d’autres chercheurs brillants et motivés qui sont rapidement devenus des collaborateurs et amis. Merci à vous deux d’avoir toujours été présents pour me donner de précieux conseils me permettant d’atteindre mes objectifs et de guider mes recherches.
Je remercie également, les membres de mon jury de thèse Marc André Bodet, Michael Lewis-Beck et François Pétry pour avoir accepté de lire et de porter un regard cri-tique sur cette thèse.
Je tiens aussi à remercier tous les membres du département de science politique de l’Université Laval, professeurs et personnel administratif pour avoir rendu ces an-nées de doctorat une aventure stimulante mais aussi pour leur accueil, leur générosité et leur ingéniosité face à tous les défis académiques et administratifs que j’ai croisés tout au long de mon parcours.
Je remercie mes amis et collaborateurs, plus particulièrement Yannick Dufresne, Corentin Vande Kerckhove, Justin Savoie et Charles Tessier, ainsi que les membres des différentes chaires de recherche auxquelles j’ai eu la chance d’être associé. Vous
avez créé un milieu de recherche passionnant, accueillant et convivial. Ce fut un réel plaisir de collaborer avec vous et de découvrir la culture québécoise sous toutes ses coutures.
Grâce au soutien financier et institutionnel du département de science politique, de la Chaire de recherche sur la démocratie et les institutions parlementaires, du Groupe de recherche en communication politiqueet du Centre pour l’étude de la citoyenneté démocra-tique, j’ai eu l’opportunité de participer à des formations et conférences académiques, qui ont contribué à la réalisation de cette thèse. Merci à ces institutions pour leur aide financière. Je remercie également MITACS et Vox Pop Labs qui, dans le cadre du pro-gramme Accelerate, m’ont permis d’acquérir une précieuse expérience profession-nelle en recherche sur l’opinion publique. Plus particulièrement, je tiens à remercier toute l’équipe de la Boussole Électorale pour son accueil chaleureux et, surtout, Clifton van der Linden pour son encadrement et sa bienveillance.
Cette aventure a débuté en 2013 grâce au Professeur Theodorus Koutroubas, su-perviseur de mon mémoire, suggérant que je poursuive une carrière que je n’avais jamais envisagée auparavant à savoir débuter un doctorat en science politique à l’Université Laval à Québec. Je n’avais pas réalisé à l’époque que cette idée, un soutien et sa confiance en mes capacités m’avait ouvert à un tout nouveau monde de partage de connaissances. Professeur Koutroubas, merci d’avoir cru en moi et de m’avoir incité à découvrir le monde fascinant, diversifié, humble et accueillant de la recherche académique.
Mes remerciements les plus sincères vont à mes proches qui, malgré la distance et mon absence, m’ont soutenu tout au long de cette aventure. Merci, tout d’abord, à mes parents–Tina et Norbert–de m’avoir toujours soutenu dans tous mes choix de carrière même si cela impliquait 6000km de distance. Votre capacité à surmonter les nombreux défis auxquels vous avez fait face depuis ma naissance m’ont donné la confiance et la motivation nécessaire pour en faire de même. Je remercie, ensuite, ma sœur et mon frère–Marina et Anthony–dont l’amour, le soutien et la confiance me donnent l’énergie nécessaire pour me surpasser au quotidien.
Enfin, et par-dessus tout, je voudrais remercier du fond du cœur mon épouse, Marie-Catherine. Tu es de loin la plus courageuse dans toute cette aventure. Sans aucune hésitation, tu m’as suivi à l’autre bout du monde, loin de ta famille et de tes amis.
j’apprécie pleinement les bons moments afin de rendre surmontable chaque épreuve. Merci pour ta patience et pour tous les sacrifices que tu as fait pendant ces années. Sans toi, cette thèse n’existerait pas, et je te suis éternellement reconnaissant. Merci.
Foreword
This is an article-based dissertation. All of the work presented henceforth has been published in peer reviewed journals. For each of the empirical chapters–articles lo-cated in Chapters1, 2and3–I was the lead investigator responsible for all major ar-eas of concept formation, data collection, method development and implementation, and analysis, as well as manuscript composition. François Gélineau and Thierry Gi-asson were respectively the supervisor and co-supervisor of this dissertation project and provided valuable feedback throughout various manuscript edits and presenta-tions that happened before their publication. The remainder of the preface clarifies my contributions to each of the manuscripts that constitute the chapters of this the-sis.
A version of Chapter 1 has been published in Political Analysis: Temporão, Mickael, Corentin Vande Kerckhove, Clifton van der Linden, Yannick Dufresne and Julien M. Hendrickx. 2018. "Ideological Scaling of Social Media Users: A Dynamic Lexicon Approach." Political Analysis 26(4):457–473. In this article, I was the lead investi-gator, responsible for all major areas of concept formation, method development and implementation, and analysis, as well as manuscript composition. This article was co-authored with Corentin Vande Kerckhove , Clifton van der Linden,Yannick Dufresne, and Julien Hendrickx.
A version of Chapter 2 has been published in National Identities: Dufresne, Yannick, Charles Tessier, Alexandre Blanchet and Mickael Temporão. 2018. "The symbolic mosaic: an empirical typology of national symbolic webs and its effect on vote choice in Canada." National Identities pp. 1–17. In this article, I was the lead investigator, responsible for all major areas of data collection and analysis, method development and implementation, as well as manuscript composition. Although my name is not in the first position for this article, my co-authors have acknowledged my role as
the lead investigator. This article was co-authored with Yannick Dufresne, Charles Tessier, and Alexandre Blanchet.
A version of Chapter 3 has been published in the International Journal of Forecasting:
Temporão, Mickael, Yannick Dufresne, Justin Savoie and Clifton van der Linden. 2019. "Crowdsourcing the vote: New horizons in citizen forecasting." International Journal of Forecasting35(1):1–10.In this article, I was the lead investigator, responsible
for all major areas of concept formation, method development and implementation, data collection and analysis, as well as manuscript composition. This article was co-authored with Yannick Dufresne, Justin Savoie, and Clifton Van der Linden. The reader should note that each of the empirical chapters introduced in this disser-tation is distinct and intended to "stand alone" as published work. Although each article is self-contained, each of them addresses questions of theoretical and method-ological importance within the common issue of this thesis.
Introduction
0.1 Introduction
The measurement of public opinion is a critical source of validation when it comes to theories in political science that presume to assess democratic systems on the basis of citizens’ ability to elect candidates who ostensibly align with their policy preferences (Wlezien, 1995; Petry and Mendelsohn, 2004; Soroka and Wlezien, 2004; Stimson,
2004;Jessee,2012). These theories often take for granted that citizens possess mean-ingful attitudes and well-defined ideologies that inform their policy preferences in a consistent and reliable fashion (Achen, 1975;Treier and Hillygus, 2009). The logi-cal extension of this argument is that an individual’s ideologilogi-cal predilection should be determinant of their electoral behaviour. But does ideology in fact predict vote intention? This question is central to our understanding of how democracies reflect citizens’ preferences.
Converse(1964) catalyzed an enduring debate in the field of political behaviour by calling into question citizens’ ability to fulfil their ideal role in a democratic system. Since then, the democratic enterprise has continued to face challenges as assumed prerequisites for a functional democracy appeared not to be met by most citizens (Converse,1964;Kinder,1983). This rather bleak portrait of mass publics has gener-ated debate extending across nearly half a century by scholars trying to rehabilitate the picture of the public (Lane, 1962; Achen, 1975; Nie, Verba and Petrocik, 1976;
Lewis-Beck et al.,2008).
The ongoing inquiry into the nature of citizen participation in democratic systems has taken up Converse’s fascination with subgroup dynamics, particularly the dis-tinction between political elites and ordinary citizens (Converse, 1964;Zaller, 1992;
are part of a distinct social and historical context (Noel, 2013). An ideology aggre-gates such shared beliefs, opinions, concerns, and preferences held by individuals into different groups. This prompts the question of whether ideologies predict vot-ing intentions with variable degrees of accuracy across different types of political actors.
Social groupings affect people’s political beliefs and decisions (Lazarsfeld, Berelson and Gaudet,1948), but there are distinctions beyond elite and ordinary citizens that warrant consideration. National symbols are another relevant alternative that can serve to distinguish between groups in diverse settings (Butz, 2009; Geisler, 2005a;
Armstrong, 1982). Scholars have already emphasized that attachment to specific symbols can affect the attitudes and behaviour of citizens (Finell et al., 2012; Finell and Zogmaister, 2015;Ehrlinger et al., 2011). The prevailing assumption, however, has been to define relationships to national symbols as universally and ubiquitously held within a national population. But can different types of relationships to national symbols co-exist within the membership of a nation-state?
More recently, citizens have also been put to test in election forecasting. The lack of individual sophistication by citizens can be compensated by heuristics and aggre-gation. Citizens manage to infer valuable perceptions from their daily experiences (Popkin,1991;Sniderman, Tetlock and Brody,1991). Citizen forecasting can be seen as an alternative area of inquiry to help rehabilitate the picture of the public. Instead of looking at the ability of citizens to fulfil their role in a democratic system through the lens of complex latent concepts, this field of study looks at citizens’ ability to understand electoral dynamics. The aggregation of individual views can result in a meaningful public signal (Page and Shapiro,1992). Can citizens understand political dynamics and predict electoral outcomes? The predictive power of citizen forecast-ing is commonly attributed to the ‘wisdom of crowds’. If citizens’ guesses are better than chance the probability of citizens to predict the victor of an election increases with the size of the sample. That is, the aggregate estimation of a group is generally more accurate than the individual estimations of any of its members (Surowiecki,
2004). Nonetheless, while the study of subgroups is appealing to scholars, it has al-ways been challenging due to data scarcity and the many challenges associated with the measurement of public opinion which has left many questions unanswered. The measurement of public opinion has become increasingly complex as publics transition from the ubiquitous household landline to a diverse array of
communi-cations technologies. Probability sampling methods have been successfully used to measure public opinion for decades (Gelman, Goel, Rothschild and Wang, 2016). Since the 1990s, traditional telephone polling methods such as random-digit dialing (RDD) have been subject to waning credibility (Yeager et al.,2011;Tessier, Bodet and Gélineau, 2014). The decline in response rates makes it increasingly difficult, slow, and costly to obtain probabilistic samples (Groves, 2011; Gelman, Goel, Rothschild and Wang, 2016). This calls into question the accuracy and sustainability of such data and methods.
Despite the introduction of sampling techniques and statistical methods intended to account for contemporary challenges in conducting surveys, collecting public opin-ion data that are representative of a particular populatopin-ion of interest is a fraught endeavour. Recent high-profile failures by pollsters to forecast electoral outcomes– such as the failure of most pre-election polls to predict the republican challenger’s victory during the 2016th American presidential election1or the failure to predict the
Brexit vote in 20162, among other examples–have eroded confidence in the polling
industry and this has implications for democratic governance.
This dissertation takes as a starting premise the view that random sampling is in-creasingly untenable given the proliferation of alternative modes of communication. An increasingly rich yet relatively untapped source of public opinion data takes the form of extraordinarily large, complex datasets commonly referred to as Big Data. The concomitant rise in Big Data generated by social and other digital media is a promising alternative source of public opinion data, but those data are nearly uni-versally non-random which ostensibly precludes them as a means for making gener-alizable claims. The study of population subgroups has been appealing for decades and could be eased with broader sample sizes and increased interdisciplinary ap-proaches, which leads us to ask the following question:
• Can large-scale non-probabilistic heterogeneous data, that are found online, be a valid source of information and contribute to the study of public opinion and political behaviour?
1Pollsters struggle to explain failures of US presidential forecasts. 2016. Nature.
https://www.nature.com/news/pollsters-struggle-to-explain-failures-of-us-presidential-forecasts-1.20968 - Accessed on October 10th, 2018.
The motivation for this dissertation arises from a desire to find alternatives to study-ing public opinion at a time where classic survey instruments are loosstudy-ing in popu-larity, there is a lack of valid and scalable approaches to analyze Big Data, and also a lack of interdisciplinary academic research bringing together social and natural sciences to better understand a rapidly changing society. Our goal is to overcome these challenges by providing methods and tools required to answer such questions and therefore creating new research opportunities and broaden the scope of public opinion research.
Following the footsteps of studies trying to rehabilitate the picture of the mass publics, this thesis introduces three articles that aim to ask and answer questions relying ex-tensively on the availability of large data sets and access to computational resources such as:
• Do ideologies predict voting intentions with variable degrees of accuracy across different types of political actors?
• Can different types of relationships to national symbols co-exist within the membership of a nation-state?
• Do citizens have the ability to understand political dynamics and forecast dif-ferent types of elections?
The answering of such questions, even though they pertain to specific areas of in-quiry, requires the use of larger and heterogeneous samples of political actors in different political contexts that are difficult to obtain using classic survey instru-ments. This project illustrates that by combining recent advances in statistics, natural language processing, network analysis, and machine learning, these challenges can serve as catalysts that drives methodological innovation.
This dissertation introduces novel approaches to study public opinion and human behaviour and contributes to important theoretical debates within the literature by marshalling the empirical evidence necessary to test theories in political science that were previously unaddressed due to data scarcity and computational constraints. The subsequent chapters illustrate how public opinion and political behaviour can be studied empirically and in greater depth with Big Data. The project provides valuable insights in the study of political ideologies, nationalism, voting behaviour, and election forecasting. In Ideological scaling of social media users: a dynamic lexicon
approach, we develop a scalable model to estimate the ideology of different politi-cal actors on a common spoliti-cale, in different countries and for different languages, by virtue of the daily vocabulary that they employ in their interactions on social me-dia platforms and illustrate how the combination of different streams of online data can improve predictions of voting intentions. In The symbolic mosaic: An Empirical Typology of National Symbolic Webs and its Effect on Vote Choice in Canada, we rely on a large online panel survey in Canada to make inferences about the heterogeneous construction of national identities by exploring the variance in attachment to sym-bols among various publics and illustrate how these constructs are predictive of vote choice. In Crowdsourcing the vote: new horizons in citizen forecasting, we endeavour to harness on the wisdom of the crowd by drawing on the largest ever, non-random election studies as part of an effort to control for the selection bias inherent to such samples.
Driven by the computational revolution that is shaping social sciences, we posit the theory that certain non-random data, when properly treated, can be useful in terms of deriving accurate inferences about populations of interest. We argue that non-random samples from social and other digital media sources can be adapted so as to predict individual behaviour and electoral outcomes at least as effectively as with conventional surveys instruments. This dissertation argues ultimately that Big Data in combination with proper methods can provide empirical evidence to advance the theoretical understanding of public opinion and human behaviour in new and useful ways.
0.2 The measurement of public opinion
Before turning to the measurement of public opinion it is important to understand what we mean by public opinion. Defining public opinion is not a trivial task as there is no consensus on the meaning of public opinion. As noted by V.O. Key, more than 50 years ago, "to speak with precision of public opinion is a task not unlike coming to grips with the Holy Ghost" (Key,1961, p.8). Key defines public opinion as "the opinions held by private persons which governments find it prudent to heed" (Key,1961, p.14) We borrow Key’s, definition of public opinion as a starting point for this dissertation. This simple yet broad definition of public opinion is interesting as it encompasses three important concepts: individuals, groups, and governments.
Indi-to the functioning of modern democratic systems. A well-functioning democracy therefore requires effective mechanisms by which public opinion can be accurately and credibly conveyed to government officials and the public. Reliable estimates of public attitudes towards government strengthen political accountability and estab-lish mechanisms for more robust democratic engagement.
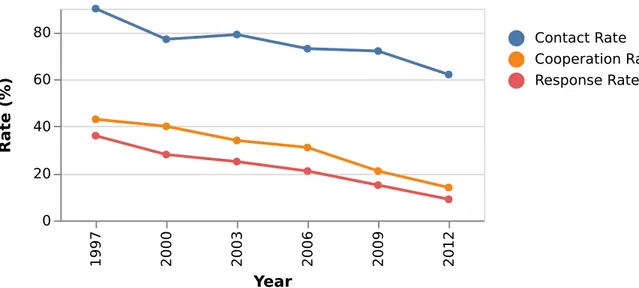
Figure 0.1: Decline in response rates to Pew surveys, 1997–2012
- Contact Rate: percentage of households in which an adult was reached.
- Cooperation Rate: percentage of households contacted that yielded an interview. - Response Rate: percentage of households sampled that yielded an interview. Source: The data are taken fromKohut et al.(2012).
It is becoming increasingly difficult for telephone surveys, including landlines and cell phones, to reach or persuade potential respondents (Kohut et al., 2012). For instance, as illustrated on Figure 0.1, in the United-States, since the late 1990s, the non-response rates have started to rise at substantial rates. The number of potential respondents that the Pew Center for the Study of the People and the Press–one of the most renowned survey operations in the United States–decreased by almost one third and went down from 90% in 1997 to 62% in 2012. Following an even more steady pattern, the response rates of typical surveys decreased four-fold, and went from 36% in 1997 to just 9% in 2012. In other words, this decline means that it is in-creasingly difficult and costly, and more efforts are needed to achieve such responses rates nowadays.
With the advent of online survey techniques, the steep decline in landline telephone ownership, and plummeting response rates to standard telephone surveys,
schol-ars have turned increasingly to new modes of data collection and new methods for enabling statistical inferences to be made about attitudes and behaviors among the population. Recent advances in statistical methods designed for causal inference (Ming and Rosenbaum, 2000; Imbens, 2004; Ho et al., 2007; Austin, 2011) open up the possibility for researchers to weight large online data sources to a population of interest.
These methods are being developed to combat the selection bias inherent to ran-domized controlled trials (RCT), in which subjects are often chosen based on avail-ability. Because causal effects are often heterogeneous, the average treatment effect observed in an RCT will be different than the effect observed in the population of interest. This problem often leads researchers to conduct effectiveness trials to bet-ter test generalizability (Stuart et al., 2011). These samples themselves, however, are often not randomly selected from the population of interest despite best efforts. Methods have therefore–very recently–been developed to estimate the affect of a treatment on a population as a whole (Cole and Stuart,2010;Stuart et al.,2011). The conceptual jump we suggest is to recognize that weighting those who self-select into a RCT up to a population of interest is equivalent to correcting for the bias of those who self-select into an online application. However, theories of selection into medical trials cannot easily be applied to political surveys. In RCT, you generally have a better sample of the population. People who have a conditions are often go-ing to seek treatment. The sample is better known as the patient history is known providing reliable measures of observable variables of interest. In political surveys, some of the main variables of interest, such as previous vote or ideology, are not di-rectly observable. These concepts depend on a citizens ability to recall their previous behaviour or understanding of complex latent concepts such as ideology. We thus require a new set of theories about selection to determine the variables that predict selection and to determine whether selection can be predicted to such a degree that valid inferences can be made about public opinion. In a recent article, Wang et al.
(2015) examine the ability of Multi-Level Regression and Post-stratification (MRP) to successfully weight non-representative data from the Microsoft Xbox gaming plat-form. Their reasons for this study are twofold. First, random digit dialing (RDD) used by conventional polling firms now rely on exceptionally low response rates. Only roughly 10 percent of those who are asked to participate in telephone surveys
technological innovations now enable the cost-effective collection of large quantities of data using online surveys. A benefit of these data is that the attitudes and be-haviours of many previously unexamined groups can now be explored using more sophisticated methods (Ghitza and Gelman,2013).
The data (Wang et al., 2015) use are derived from an opt-in poll of Xbox users that was run in the 45-day lead-up to the 2012 U.S. presidential election. As one would expect, the data are non-representative with respect to known socio-demographics and political identification in the population. The goal is to apply post-stratification to the data, using MRP, to approximate a representative sample of likely voters. The authors set up a multilevel model to predict support for each of the two major can-didates running in the election (Wang et al., 2015). For the post-stratification stage, they then apply the fitted model to exit poll data from the 2008 election, a large high quality dataset. Past exit poll data act effectively as a census of past voters in the election.
In a last step, the authors examine how well the forecast for various sub-populations compares to data from 2012 exit polls. The estimates of vote intention for each socio-demographic is exceptionally accurate. In sum, despite being applied to substan-tively non-representative samples, corrections can be applied and allow forecasts to perform well. Recent scholarship in the fields of political and computer science has sought to extend sample weighting techniques from survey data to social me-dia data with a view to derive public opinion from large, unstructured, continuous sources of public opinion data (O’Connor et al., 2010; Gayo-Avello, 2013; Huberty,
2015; Beauchamp,2016). This work has been complicated primarily by two factors. First, for opinion to be extracted from social media data, text must be converted into discrete variables. Second, given that social media data are statistically biased, they must be weighted to reflect the population of interest in order to lay claim to the capacity for generalizable inferences.
0.3 Modern Data and Methods
In the past years, there has been an increase in the data generated by contemporary digital systems (Groves, 2011;Keller et al., 2017;Lazer and Radford, 2017). The in-terconnectedness of devices and online applications generated by Internet of Things (IoT) has altered the way people access and share information (Gubbi et al., 2013). Advances in information and communication technology (ICT) have led to an
ac-celeration of the dissemination of information and consequently to a continuous increase in size of the data available (Hilbert and López, 2011). Processing power has been increasing exponentially since the first Central Processing Unit (CPU) was made available to the public by Intel in 1971. The growth of computing resources has led to decreasing processing and storage costs and enabled the development of better online applications that provide users with a superior experience (Hilbert and López, 2011). The popularity of such applications and devices resulted in online data extends sample sizes by orders of magnitude, generating large datasets often referred to as Big Data. While online data are appealing recent data scandals and regulations–such as the Facebook–Cambridge Analytica data scandal3 or the
Gen-eral Data Protection Regulation in the EU4–should raise awareness regarding any
data driven activities and call into question how data are used and shared.
To illustrate the popularity of data that can be found online, Facebook had 2.2 billion monthly active users in 2017, and Twitter has 330 million.5 Together, these two social
media platforms produce petabytes of user-generated data daily.6 Users are able
to share their opinions, attitudes, and behaviours on these platforms, while other users can access and interact with this information from any device connected to the Internet. The large-scale Voting Advice Application–Vote Compass7–collects millions
of data points worldwide whenever there is an election being held (van der Linden and Dufresne,2017). These modern application provide scientists with a whole new range of empirical data, which holds great promise for public opinion research. Many disciplines have started to collect and analyze large volumes of data using a combination of computational and statistical tools (Lazer and Radford,2017). Health authorities were able to respond to public concerns in a timely manner based on the way users were disseminating, on social media, the terms "H1N1" and "swine flu" during the 2009 H1N1 pandemic (Chew and Eysenbach, 2010). In genetics,
3Revealed: 50 million Facebook profiles harvested for Cambridge Analytica in major data breach.
2018. The Guardian. https://www.theguardian.com/news/2018/mar/17/cambridge-analytica-facebook-influence-us-election. Accessed on September 29, 2018.
4 Regulation (EU) 2016/679 of the European Parliament and of the Council. 2016.
EUR-Lex. https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A32016R0679. Accessed on September 29, 2018.
5Global social networks ranked by number of users. 2018. Statista.
https://www.statista.com/statistics/272014/global-social-networks-ranked-by-number-of-users/. Accessed on May 17, 2018.
the technological advancements allowed faster, cheaper, and easier sequencing of tumors (Adams, 2015). In artificial intelligence, they have allowed computers to beat humans in some of the most challenging games (Gibney,2016;Moravˇcík et al.,
2017). Social science scholarship has been slower to adapt (Lazer et al., 2009), but researchers driven by the wealth of information contained in online data–about in-dividuals’ opinions and behaviours–can now tackle areas that were previously im-possible due to the scarcity of data.
0.3.1 Large-Scale Online Data
The data generated by the digitization of social life are characterized by larger sizes, reduced acquisition costs, non-representativeness, but also has a much lower infor-mation to data ratio (Groves, 2011; Lazer and Radford,2017). This low information to data ratio means that for a larger quantity of data, the proportion of relevant or useful information to answering a specific question is much lower. Online data can be generated with multiple mechanisms and scholars have identified various ways to characterize them (Groves,2011;Keller et al., 2017). In this dissertation we consider that the data generated from contemporary digital systems are either de-signed or opportunistic. The former refers to data where the researcher using the data played an active role in defining what is collected in regards to a phenomenon being studied. For instance, an opt-in online survey designed by academics to study political issues such as the Vote Compass application (Lees-Marshment et al., 2018). The latter refers to data that are opportunistically used to study a phenomenon dif-ferent than the purpose of the application or tool that generated the data in the first place. Scholars do not play an active role in defining how this data are collected and what is available. Instead, a researcher studying a particular phenomenon sees an opportunity in using data publicly available on the Internet. Opportunistic data generally results in larger datasets that contain very low amounts of relevant in-formation compared to the amount of data available. For instance, using publicly revealed preferences on social media such as Facebook to study political ideologies (Bond and Messing,2015)
Both designed and opportunistic data can yield information about online and offline human behaviour. In comparison to survey data, social media data does not rely on memory or recall of respondents as this data are passively obtained (Buntain et al.,
2016). While traditional offline survey instruments, are by no means rendered obso-lete, the abundance, affordance, and versatility that online data can provide makes
its use advantageous (Buntain et al., 2016; Gelman, Goel, Rothschild and Wang,
2016). Big Data contains attitudinal, behavioural, and socio-demographic informa-tion about its users enabling the study of populainforma-tion structure and human behavior at unprecedented scale (Ruths and Pfeffer, 2014). Social media websites like Twit-ter frequently encourage researchers to use their data (Wilkerson and Casas, 2017). Application Program Interfaces (APIs) allow programmers to crawl the contents of some social media platforms and generate different behavioural datasets (Bond et al., 2012; Batrinca and Treleaven, 2015; Barberá, 2015; Jungherr and Theocharis,
2017). The ease of access to data and the growing affordability of computational resources potentially allow these large online datasets to become a viable source of information to study public opinion, which in turn creates a set of challenges and opportunities in a variety of academic fields.
The size of data along with simple demographic markers enables researchers to con-duct granular analysis of a population (Jungherr and Theocharis,2017;Leemann and Wasserfallen,2017). In traditional offline surveys, the samples are often too small to allow for a valid analysis of subgroups of the population. The vastness of Big Data offers granularity of user behaviour over time (O’Connor et al., 2010; Beauchamp,
2016). Recent advances in statistics offer methods to draw inferences from highly skewed samples in order to overcome sampling challenges (Ho et al., 2007; Wang et al.,2015;Gelman, Goel, Rothschild and Wang,2016). Scholars have demonstrated the effectiveness of the samples drawn from the Web (Chang and Krosnick, 2009;
Lee and Valliant, 2009; Yeager et al., 2011). As a result, researchers can gain a per-ceptive time-sensitive behavioural insight of users on these platforms (Cody et al.,
2016; Jungherr and Theocharis, 2017). Interactions between users can be captured over time, leading to greater and more detailed insights about the social dynamics that were previously invisible (Jungherr and Theocharis,2017).
Big Data also comes with its own set of challenges. In order to be able to study large-scale, non-probabilistic data, proper modelling and efficient use of existing compu-tational resources is crucial. These barriers to entry lead to the development of more sophisticated techniques and increased methodological standards (Ruths and Pfef-fer, 2014; Shiffrin, 2016). This can partly explain why computational social sciences was exclusively done by large Internet companies like Facebook, Google, and gov-ernment agencies (Lazer et al.,2009).
scandals8 that highlight important data privacy concerns raising questions
regard-ing the usage of data–publicly available or owned by other private companies–in research. Any dataset involving human subjects raises ethical and privacy concerns regarding the use of such data. The users–that have opted into an online application– often have very limited knowledge and understanding of how their data are used by the companies storing the data9 or the usage made by third parties in the case such data are publicly available. For instance, the data can be used by political and social scientist to study political mobilization and the spread of fake news (Bond et al., 2012; Vosoughi, Roy and Aral, 2018), but it can also be used by businesses to identify potential customers (Lo, Chiong and Cornforth,2015). Linking a social me-dia account to a publicly available voting record can be made by matching profile names (Barberá,2015). While de-identification procedures exist, the subjects might not have been aware that their data has been used for such purposes in the first place. Scholars also emphasize that de-identification practices can threaten the replication of results or subsequent analysis (Daries et al., 2014). This challenges, at the bare minimum, academic scholars using individual-level data to find an equilibrium be-tween anonymity and science in order to allow the use of promising data for research that is available online or owned by private entities. As said by Daries et al.(2014): "If we want to have high-quality social science research and also protect the privacy of human subjects, we must eventually have trust in researchers."The recent data scandals are not helping on that regard.
0.3.2 Computational Methods
The paradigm of computational social sciences is that information is the key to un-derstanding and explaining social complexity (Cioffi-Revilla, 2014). Information processing, from the allowance of computational systems to hold, process, and ana-lyze the information, plays an important role (Cioffi-Revilla, 2014). Computational social sciences involve the fundamental inquiry of social systems using theories, con-cepts, and practical skills from the social sciences, quantitative methods from statis-tics, paired with algorithmic advancements in computer science, and computational means provided from advances in information and communication technology. The
8Revealed: 50 million Facebook profiles harvested for Cambridge Analytica in major data breach.
2018. The Guardian. https://www.theguardian.com/news/2018/mar/17/cambridge-analytica-facebook-influence-us-election. Accessed on September 29, 2018.
9All the data used in this dissertation, whether Twitter data or online survey data was collected
and anonymized by Vox Pop Labs with the provided consent of the users to use such data for aca-demic research purposes.
field is still relatively new, and it is not devoid of its own unique set of issues, from privacy concerns to the inferences that can be drawn from non-probabilistic samples. In spite of this, the emerging field of computational social science offers new meth-ods for analyzing data of unprecedented size and composition. The question of how to exploit these large amounts of information available on Web and the methods to draw inferences about the general public remains largely unexplored in public opinion research.
The use of Big Data and distributed computing resources and methods to study public opinion is a growing research area, driving new research in social sciences, motivated by methodological and theoretical challenges (Eagle, Pentland and Lazer,
2009; Bond et al.,2012; Vosoughi, Roy and Aral,2018). The size and depth of these data allow researchers to study behavioural patterns for groups for which classic survey samples would have been too small or difficult to implement (Jungherr and Theocharis, 2017). The democratisation of computational resources brings public opinion research into the digital age and can help understand human behaviour (Mann, 2016). Computational methods–whether supervised or unsupervised–can process large amounts of data with ease (Grimmer,2010).
Computational methods in combination with Big Data can allow the analysis of com-plex interactions between heterogeneous actors, and enable the study of a variety of phenomena that are difficult to observe, but which can contribute to questions of theoretical importance (Lazer and Radford, 2017). Researchers have started to ex-plore the ways in which information produced by online applications can influence the public (King, Schneer and White, 2017; Bail et al., 2018). For instance, the net-work information available on social media websites has allowed the scaling of valid ideological positions for different political actors (Barberá,2015). Some believe, that exposure to online political information influences individuals’ beliefs and partici-pation in politics (Gruzd and Roy, 2014; Barberá, 2015; Kim and Chen, 2016). This is supported by existing sociological research on selective exposure theory where individuals prefer information that reinforces their previously held opinion ( Bar-berá, 2015; Bail et al., 2018). Other scholars look more specifically at the reliability of these new online datasets compared to their offline counterparts (Yeager et al.,
2011; Spohr, 2017). During political elections, opportunity data has shown promise in improving election forecasts (O’Connor et al., 2010; Beauchamp, 2016; Jain and
even provide more accurate forecasts than offline polls (Lopez et al., 2017; Bovet, Morone and Makse, 2018). The general goals of computational social science align with this dissertation’s goal to develop scalable methods to allow the study of large-scale online data and provide alternative angles to study public opinion.
0.3.3 Methodological requirements
Big Data and computational tools are attractive, but they also come with their own set of limitations and challenges that need to be addressed in order to draw infer-ences from it. The growth in the quantity of data available has been staggering (Hilbert and López, 2011). Unfortunately, its quality seems to follow the opposite trend consequently leading to a decreasing data to information ratio.
On one side, this can be partly explained by the growth of the "fake news" industry in the recent years. Online bots–automated scripts–generate content and interact with real users to influence political conversations (Forelle et al.,2015;Murthy et al.,2016). This has been further emphasized in recent presidential campaigns where fake news have not only been disseminated by bots, but also real political actors (Allcott and Gentzkow,2017;Spohr,2017). This results in false content being disseminated more broadly and rapidly than reliable news (Vosoughi, Roy and Aral,2018). On the other hand, many of the data available online is selective, incomplete, and generally un-related to the scholar’s initial questions (Lopez et al.,2017). For instance, posts from social media users are mostly made according to their own volition rather than in response to prompts (Gayo-Avello,2013;Barberá and Rivero,2015). There is a rela-tive level of instability as the data can be edited, removed, or hidden based on the users’ preference. Opportunity data provides a large number of possibly low-quality data points whereas designed data are of smaller size but with higher-quality data points. Online opt-in surveys do have a higher information–to–data-ratio given that they are crafted to study a particular phenomenon.
Another area of concern is that the population of users of a given online applica-tion are generally not a representative sample of the populaapplica-tion being studied ( Bar-berá and Rivero, 2015). To provide relevant insights about online, but also offline, behaviour the data needs to be properly weighted to reflect the population of in-terest (Gelman, Goel, Rothschild and Wang, 2016; Jungherr and Theocharis, 2017). Although online applications are popular, they suffer from platform-specific biases (Ruths and Pfeffer, 2014; Barberá and Rivero, 2015). For example, Twitter users in
the United States are often younger, more affluent, and more politically engaged than the average citizen (Barberá and Rivero,2015). The demographic composition of users also fluctuates overtime and there are some social groups that are more prevalent in political discussions, leading to some level of bias (Barberá and Rivero,
2015; Jungherr and Theocharis, 2017). This often requires scholars to have access to complementary socio-demographic information in order to properly weight the es-timates (Wang et al.,2015;Goel, Obeng and Rothschild,2015). Researchers generally do not have access to the data generation process, that is often kept secret by those big corporations. The contents available online are affected by the diffusion policies of such companies. This makes it challenging to understand the sources of potential biases and correct them accordingly (Lazer and Radford,2017).
Big Data are attractive but they should be used critically as bigger data does not nec-essarily mean better data (Boyd and Crawford, 2012; Hargittai, 2015). The various biases that are inherent to Big Data need to be accounted for and properly modelled (Ruths and Pfeffer, 2014; Huberty, 2015). The users of online platforms are not the result of a random sample, instead they self-select onto those platforms generating biased sampling frames. The population of users each platform attracts also has ma-jor implications to the conclusions one can draw from such data (Hargittai, 2015). The democratic nature of social media allows many kinds of actors to disseminate information. There is a methodological need to separate useful information from ex-traneous content. It also needs to overcome the brevity, informality, and wide range of subject matter in the user-generated text on social media platforms. Furthermore, any data involving humans can raise privacy and anonymity concerns regarding the ethical use of such publicly available information (Berry, 2011). De-identification procedures can be applied to the datasets, however those also threaten the repli-cability of the results presented or any subsequent analysis of the results (Daries et al.,2014). A proper equilibrium needs to be attained in order to solve the tensions between privacy and high-quality publicly available data (Daries et al., 2014). The analysis of Big Data needs to be conducted in such a manner that overcomes these challenges and shortcomings. The demand is for robust and scalable methods that can handle large datasets with lower information to data ratio while maintaining the anonymity of any subject without comprising the replicability of any results.
ad-study of complex phenomena that are difficult to observe without substantial sample sizes and computational resources; (3) help answer questions of theoretical impor-tance; and (4) provide new methodological tools for other scholars to do the same. The following section summarizes the goal and contributions of each of the articles that comprise this dissertation to the emergent field of computational social sciences and how their reliance on computationally intensive methods and novel large-scale datasets help answer questions of theoretical importance in public opinion research.
0.4 Organization and Overview
The goal of this dissertation is to demonstrate how Big Data motivates interdis-ciplinary methodological innovation and contributes to important methodological and theoretical debates in political behaviour and public opinion research by mar-shalling the empirical evidence necessary to test theories that were previously un-addressed due to data scarcity.
The utilization of Big Data to answer questions of theoretical importance in politi-cal science is certainly occurring, but the field is still developing: there has been a dearth of effective measures as well as methodological challenges. Further investiga-tion into Big Data’s utility is necessary but remained unanswered. Can online data be a valid source of information to study public opinion and political behaviour? Can large-scale datasets allow for the identification of meaningful clusters within a population of interest that usually go unnoticed due to data scarcity problems? If so, can latent communities identified online be predictive of different types of behaviour? How can we generalize highly skewed datasets and their associated findings to a population of interest? This dissertation endeavours to answer these questions in the subsequent chapters, offering evidences from datasets from Canada and elsewhere. To accomplish my goal and narrow some of the methodological and theoretical gaps in the emerging field of computation social sciences, we introduce several studies in this dissertation that utilize Big Data and computational social science methodologies to address perennial questions in political science research.
Chapter 1: Ideological Scaling of Social Media Users
The first article, addresses doubts that persist in the academic community regarding the validity of online data for studying public opinion (Gayo-Avello,2013;Jungherr,
2016). We ask if new online sources of information can be used to validly capture ide-ologies. More specifically, we ask how can we estimate the ideology of citizens and political elites on a comparable scale? This question is important as it can improve our knowledge about voting behaviour, polarization, representation, and other po-litical phenomena.
In order to answer these questions, we look at different types of large-scale data available online as the variety of political actors active on such platforms is broad and there are multiple opportunities for methodological innovation. In particular, we look at three specific types of data available online: network, textual, and survey data. The first two types can generally be found on social media platforms such as Twitter, the last one can be collected through online survey applications such as Vote Compass. We introduce a novel and cost-effective ideological, unsupervised, textual scaling method. This method relies on the lexicon that political elites’ use on social media platforms during political campaigns to build dictionaries of words which can calibrate the ideological weights of the dictionaries. These dictionaries can then be used on a broader set of actors active on social media in order to estimate their ideological positions. The method allows social media users—political elites, ordinary citizens, and interest groups, among others—to be placed on a comparable ideological dimension.
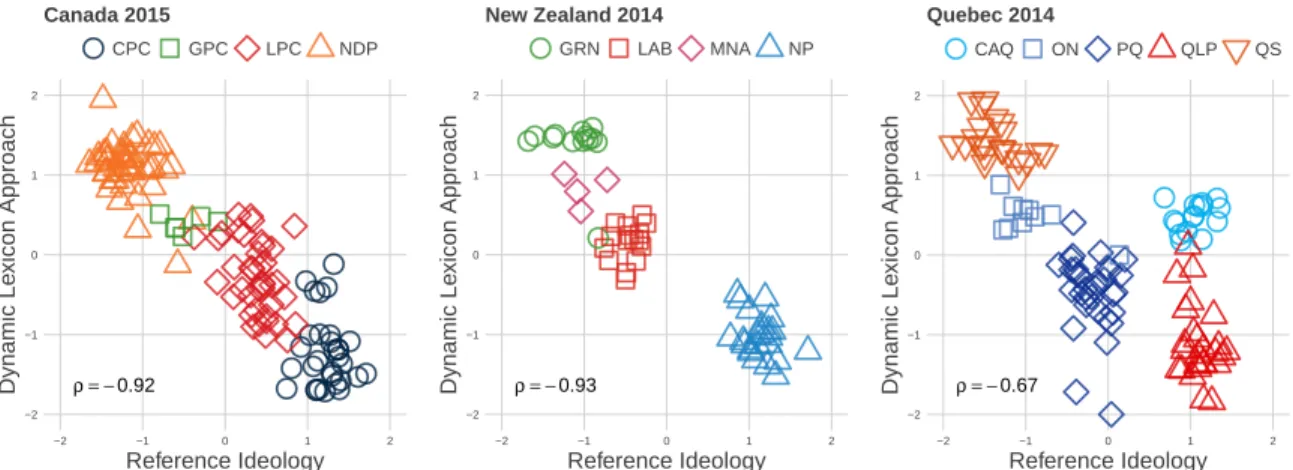
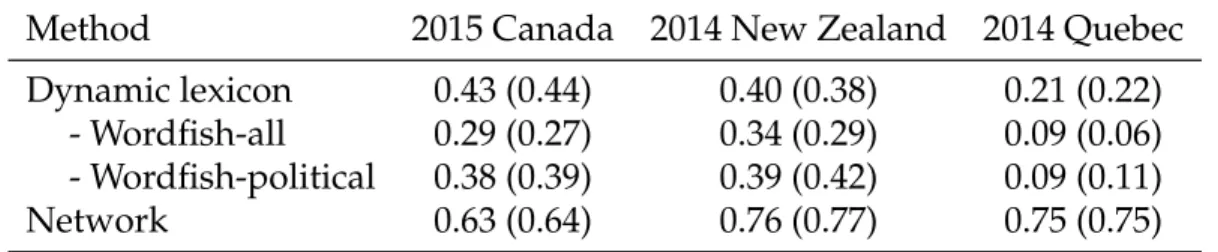
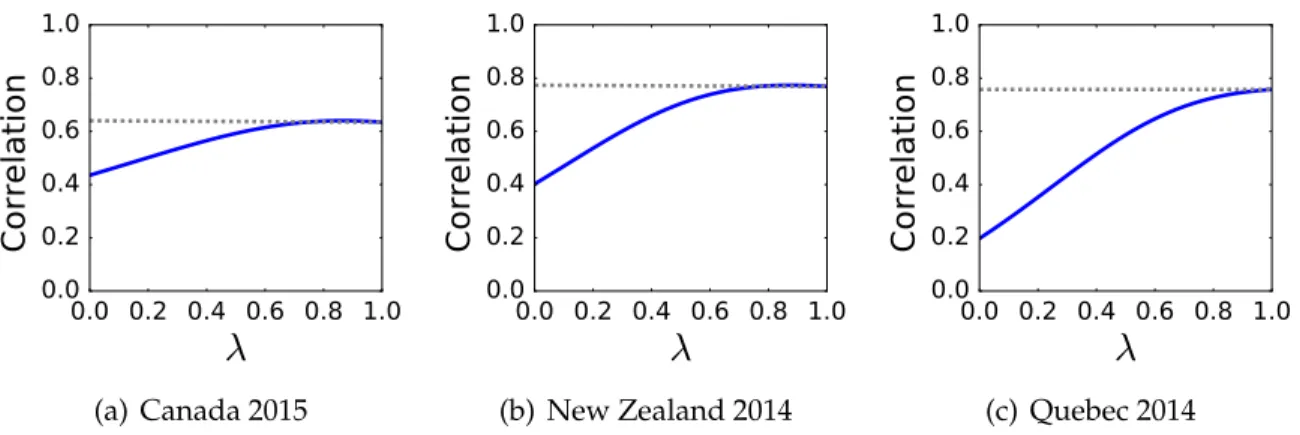
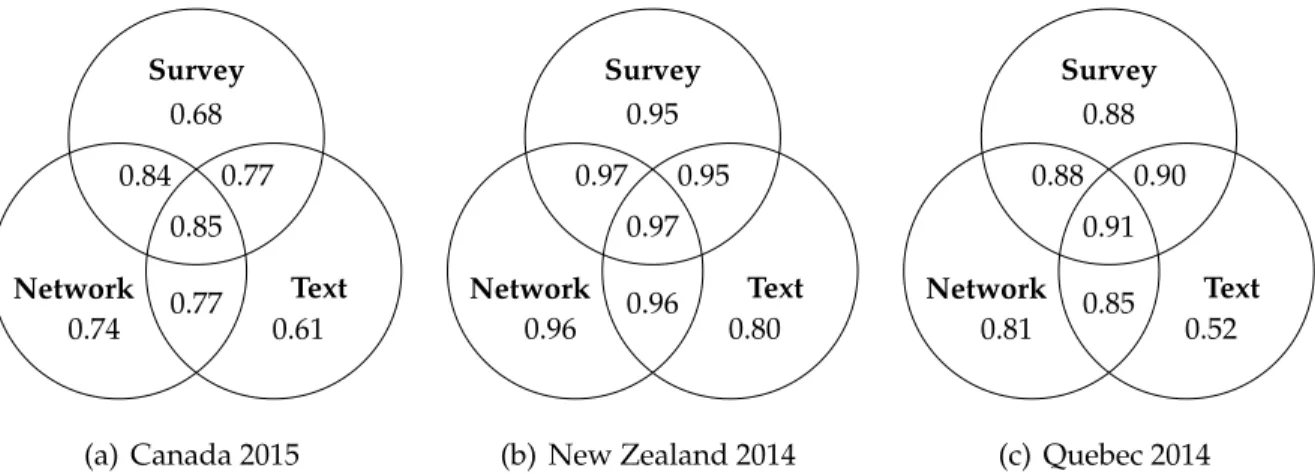
The method is validated by comparing the ideological positions derived from word frequencies to the ideological positions derived on one hand, from network infor-mation (Bond and Messing, 2015; Barberá, 2015) and on the other hand to online survey data using ideological self-placement but also by scaling respondents’ atti-tudes towards multiple political issues (Ellis and Stimson,2012;van der Linden and Dufresne, 2017). The results demonstrate the method has convergent validity with previously accepted ideological scaling methods. To further the validation process, this method is replicated in different countries, in national and sub-national electoral contexts, and for different languages. The three case studies selected to demonstrate the dynamic lexicon approach are the 2015 Canadian federal election, 2014 New Zealand general election, and the 2014 Quebec provincial election. The intuitive ide-ological placement of the parties contesting these elections offers the opportunity to compare the estimates produced by the dynamic lexicon approach for both an ex-ternal validity test and robustness check of the method. The results show that this
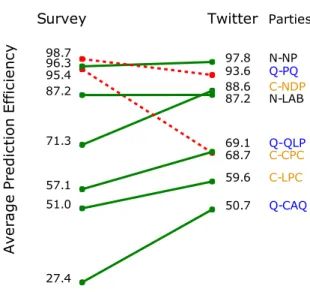
Furthermore, we also evaluate the predictive power of online data to predict out-of-sample, individual-level voting intentions. We compare each of these sources of data individually but also how the combination of these different types of data can improve such predictions. The results emphasize that derivative signal can be bet-ter captured when multiple streams of information are combined rather than using them independently. This finding helps to bridge the gap between survey data and other types of data available on social media.
The disparity in the data, ideologies, political systems, language, and geographi-cal scope serve as robustness checks that illustrate the validity of the new proposed method, but also the validity of online data to conduct public opinion research. The theoretical implications of this research permit us to address age-old debates regard-ing the ability of political actors to possess a coherent and stable structurregard-ing ideol-ogy (Converse, 1964). The ability to compare different types of political actors on a comparable scale, not only political elites but also ordinary citizens–is therefore important (Jessee, 2016). We conclude that it is possible to measure not only elites’ ideology but also citizens’ ideology using online networks, discussions, or survey data thus, providing more compelling evidence that some citizens do possess rela-tively coherent and stable ideological thinking than previously portrayed; and that this overarching ideological position if predictive of self-reported voting intentions.
Chapter Two: The Symbolic Mosaic
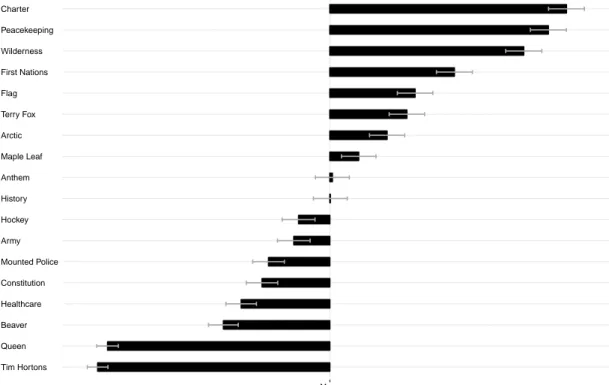
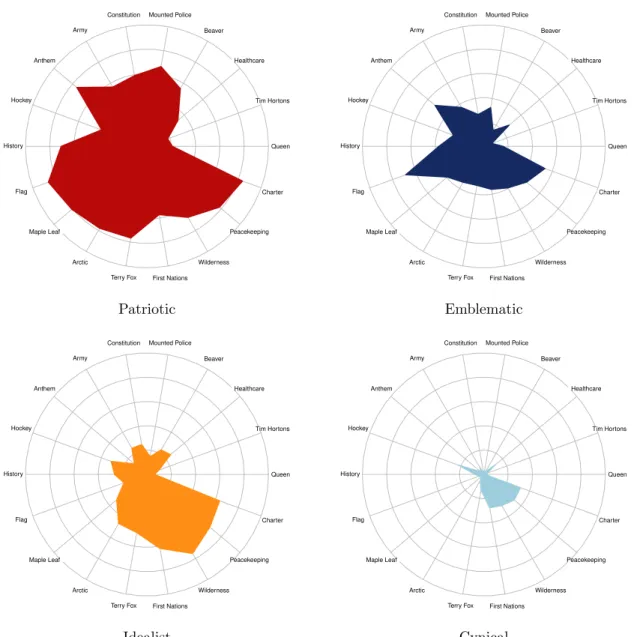
Following this, the second article examines the heterogeneous construction of na-tional identities in Canada. Nana-tionalism is generally seen as a unity among a coun-try. However, symbolic nationalism studies suggest that the group-demarcation function of national symbols might operate heterogeneously in a given population (Geisler,2005b;Butz,2009;Finell and Zogmaister,2015). In this article we ask if dif-ferent types of relationships can co-exist among national symbols within the same national unit? If so, would different national assemblages have an effect on citizens’ attitudes and behaviour? The access to large-scale online surveys and web panels can provide more granularity to the study of nationalism. To answer these ques-tions, we rely on one of the largest Canadian online panels. The data10 taps into Canadians’ attitudes towards eighteen national symbols and was collected 2014 by Vox Pop Labsusing their online panel of users.
This chapter illustrates that the size of the data collected with online web panels and online survey applications allows us to conduct empirical quantitative social re-search with more granularity, addressing political theories about nationalism, and explore the connection between nationalism and vote choice. We illustrate that there can be different types of nationalists among the same national unit. These symbols pertain to left-right positions on the ideological spectrum and, interestingly, conven-tional socio-demographic cleavages. We emphasize that there can be four distinct national symbolic "webs" that represent Canadian citizens. Further analysis con-cludes by illustrating how membership in these symbolic "webs" is predictive of vote choice.
Even though online web panels make it faster and easier to collect large samples to measure public opinion, a series of post-sampling transformation had to be made to correct for coverage, non-response errors and missing values. The data are imputed to correct missing values using multiple imputations that allow for the smoothing of trends across the data, which result in more accurate imputations (King et al.,2001). The imputations are made using a newly designed algorithm that substantially re-duces the computational resources usually required by multiple imputations and allows for the processing of larger chunks of data (Honaker et al.,2011). In a second step, to correct for coverage and non-response bias the data was weighted using a raking ratio estimation (Battaglia et al., 2009). Finally, we use a method to extract latent classes in a population sample to explore the existence of different types of national symbolic webs among patterns of attitudes towards the Canadian national symbols. The method, latent class analysis (LCA), allows the identification of pat-terns in a set of responses relevant to a specific construct (Collins and Lanza, 2010;
Linzer, Lewis et al., 2011; Drton and Plummer, 2017). The categories generated by the LCA are mutually exclusive and can therefore be used as a dependent variable in a model predicting different nationalist classes and testing its effect on vote choice. Large-scale data aided by computational tools allows us to empirically illustrate that national symbols can cluster subgroups of a population within a single coun-try. The relationship between subgroups of citizens and symbols is characterized primarily by left-right ideological positions. This goes against the suggestion that socio-demographic factors drive most of the variation between people and national symbols. Furthermore, symbolic latent groups have substantial impact on political
Chapter Three: Crowdsourcing the Vote
In the final article we explore avenues to overcome various biases that come along with large-scale online datasets. To test our ability to do so we delve into election forecasting, and more particularly into citizen forecasting. We ask how can we make accurate forecasts using highly skewed large-scale online survey samples? Further-more, can we apply such forecasts to different political contexts? To answer these questions, we rely on ten different provincial and federal online election surveys conducted in Canada and collected through the Vote Compass11. The aggregation
of these datasets results in a large-scale dataset of more that 2 million observations spread over five years of elections.
Forecasting elections is a relatively new area of academic research and offers sev-eral methodological challenges. Before the 1980s, there were no predictive models forecasting elections published in political science journals (Lewis-Beck and Tien,
1999;Lewis-Beck and Stegmaier,2014). Most election forecasting literature relies on macro-level factors or micro-level factors. The former uses factors such as the state of the economy, popularity, incumbency (Lewis-Beck and Tien, 2005; Bélanger and Godbout, 2010). The latter focuses on individuals and often relies on voting inten-tions (Graefe, 2014). On one hand, macro-level factors are interesting but can over-look campaign peculiarities that sometimes determine the outcome of close races. On the other hand, micro-level factors such as voting intentions are sensitive to cov-erage bias and require post-sampling correction (Wang et al., 2015). Some schol-ars also started developing hybrid approaches that combine both micro and macro level factors (Lewis-Beck and Dassonneville, 2015). Furthermore, the last few years have seen many scholars make the case to use large but non-representative sam-ples (Wang et al., 2015; Beauchamp, 2016; Gelman, Goel, Rivers, Rothschild et al.,
2016). The main idea is that, with proper statistical adjustments, one can draw infer-ences comparable to random samples. In this article we push that reasoning further, that is, with proper question design–asking for vote expectations rather than vote intentions–no weights are necessary.
Recent research on voter expectations shows that such micro-level factors can pro-vide accurate forecasts even with highly skewed samples (Rothschild and Wolfers,
2011). We focus on this specific micro-level factor that can control for different sources of bias by using an adapted question design. We rely on the ability of citizens
to aggregate and discern information about their local political constituencies. The aggregation of this individual-level information has forecasting power (Converse,
2000;Murr,2011). Proper survey design can help reduce some forms of biases when stochastic sampling is not feasible. To illustrate this, we compare the results of using voting intentions to voting expectations in different political contexts.
Using appropriately worded questions and simple arithmetic, one can provide al-ternative and robust ways to use large-scale online data. This article contributes to the emerging literature on election forecasting by developing an aggregating and scaling method that enables the comparison of different races in complex electoral systems with multiple parties. The article also contributes to the literature on voter expectations by emphasizing citizens’ ability to forecast electoral the outcomes. We conclude that large-scale online data enables the study of complex sub-national dy-namics which is valuable to the study of various political systems. The accuracy of these forecasts in different political contexts emphasizes the robustness of this method. This method can also be valuable in the study of electoral contexts and countries that lack reliable census data.
In the final chapter we summarize the findings and contributions of this dissertation and draws upon their conclusions. We discuss how relying on computational meth-ods and large-scale, novel datasets available online provides new angles that can advance scientific inquiry into socially important research questions relevant to our understanding of public opinion and political behaviour. We further discuss the im-plications of this research as well as its limitations. We discuss in greater depth how this dissertation contributes to the advancement of computational social science and overall development of scientific knowledge by providing better understanding of socio-political dynamics across different geo-political contexts. Finally, we reflect on future areas of inquiry that utilize the wealth of knowledge contained in Big Data in order to further the study of public opinion and political behaviour.
0.5 Bibliography
Achen, Christopher H. 1975. “Mass political attitudes and the survey response.” American Political Science Review69(04):1218–1231.
Adams, Jill U. 2015. “Big hopes for big data.” Nature 527(7578):S108–S109.
Allcott, Hunt and Matthew Gentzkow. 2017. “Social media and fake news in the 2016 election.” Journal of Economic Perspectives 31(2):211–36.
Armstrong, John A. 1982. Nations before nationalism. UNC Press Books.
Austin, Peter C. 2011. “An introduction to propensity score methods for reducing the effects of confounding in observational studies.” Multivariate behavioral research 46(3):399–424.
Bail, Christopher A, Lisa P Argyle, Taylor W Brown, John P Bumpus, Haohan Chen, MB Fallin Hunzaker, Jaemin Lee, Marcus Mann, Friedolin Merhout and Alexan-der Volfovsky. 2018. “Exposure to opposing views on social media can increase political polarization.” Proceedings of the National Academy of Sciences p. 201804840. Barberá, Pablo. 2015. “Birds of the same feather tweet together: Bayesian ideal point
estimation using Twitter data.” Political Analysis 23(1):76–91.
Barberá, Pablo and Gonzalo Rivero. 2015. “Understanding the political representa-tiveness of Twitter users.” Social Science Computer Review 33(6):712–729.
Batrinca, Bogdan and Philip C Treleaven. 2015. “Social media analytics: a survey of techniques, tools and platforms.” Ai & Society 30(1):89–116.
Battaglia, Michael P, David Izrael, David C Hoaglin and Martin R Frankel. 2009. “Practical considerations in raking survey data.” Survey Practice 2(5):1–10.
Beauchamp, Nicholas. 2016. “Predicting and Interpolating State-Level Polls Using Twitter Textual Data.” American Journal of Political Science 61(2):490–503.
URL: https://onlinelibrary.wiley.com/doi/abs/10.1111/ajps.12274
Bélanger, Éric and Jean-François Godbout. 2010. “Forecasting Canadian federal elec-tions.” PS: Political Science & Politics 43(04):691–699.
Berry, David M. 2011. “The computational turn: Thinking about the digital human-ities.” Culture Machine 12.