Improving Moments-based Visual Servoing with Tunable Visual Features
Texte intégral
Figure
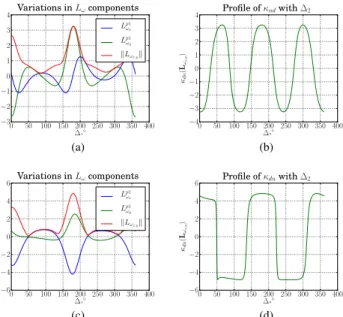
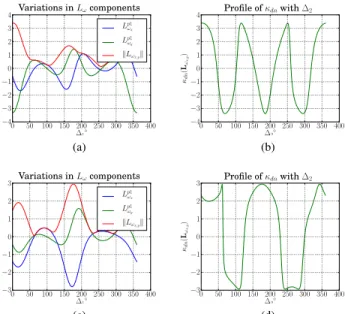

Documents relatifs
À l’échelle des neurones, la technique du patch-clamp (Prix Nobel, 1991) permet de comprendre comment les neurones génèrent leurs signaux électriques par une
The method, makes a matching between consecutive images of a planar reference landmark, using either, homography estimation based on good features to track (Shi & Tomasi
Dans la présente étude, des réponses cardiorespiratoires normales et reflétant les réponses à un test d’effort maximal ont été obtenues par les deux sujets lors
O objetivo central deste livro é, portanto, divul- gar experiências bem sucedidas de inovação para o desenvolvimento rural. Apesar de uma miríade de casos e atores, o que há em
The second option uses affine invariants and requires extracting and tracking two points, but ensure higher performances since it allows convergence for huge motion (exceptional for
Whatever the sensor configuration, which can vary from one on-board camera located on the robot end-effector to several free-standing cameras, a set of visual features has to
Methods for estimating these 3D parameters exist, either using the knowledge of the robot motion (De Luca et al. 2008), or the knowledge of the 3D object model when it is
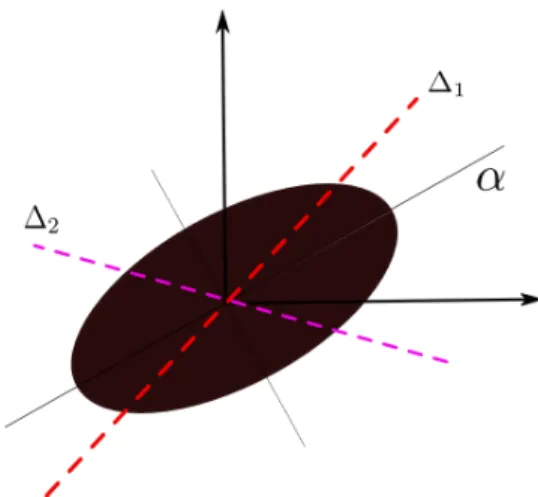
For instance, for the first example depicted on Figure 1, the image processing part consists in extracting and tracking the center of gravity of the moving people, the visual
