Towards Transparent Combination of Model Management Execution Strategies for Low-Code Development Platforms
Texte intégral
Figure
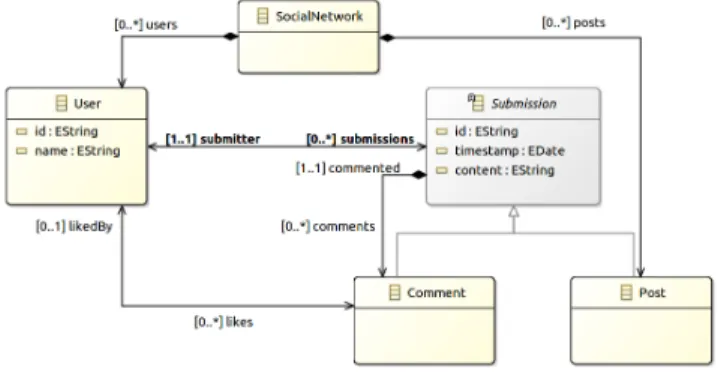

Documents relatifs
P RIVACY -P RESERVING I O T S YSTEMS AND MDE The next steps towards privacy-preserving system design for IoT using an MDE approach are (1) to discuss privacy- preserving systems
Lorikeet can automatically create well-tested smart contract code from specifications that are encoded in the business process and data registry models based on the implemented
To tackle this limitation, we propose execution-based model profil- ing as a continuous process to improve prescriptive models at design-time through runtime information
In our case study, the abstracted views of our entry models are composed of 13 vertices and 16 edges to represent the SysML model, 17 vertices and 33 edges to represent the
Figure 6 draws the big picture of the Execution Model implementation using the Visitor pattern by giving the example of Software Activity, Activity Edge and
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Each plan comprises of a sequence of model synthesis rules (or mutation operators) specified as Graph Grammar (GG) rules.. These mutation operators are primitive GG rules
Keywords: Model Based System Engineering, Engineering Data Management, Product Lifecycle Management, Product Architecture Modelling, Design for Simulation.. 1
